|
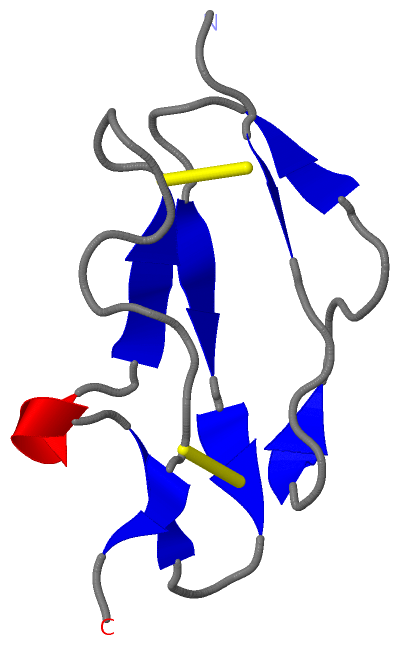
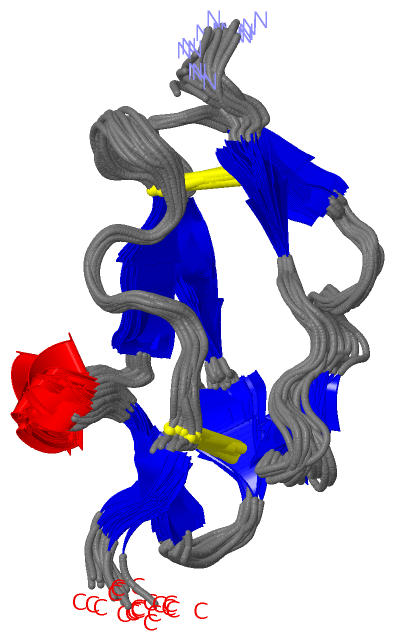
| Title | : | STRUCTURE OF CCP MODULE 7 OF COMPLEMENT FACTOR H - THE AMD AT RISK VARIENT (402H)
|
|---|
| |
|---|
| Authors | : | A. P. Herbert, J. A. Deakin, C. Q. Schmidt, B. S. Blaum, C. Egan, V. P. Ferreira, M. K. Pangburn, M. Lyon, D. Uhrin, P. N. Barlow |
|---|
| Date | : | 16 Feb 07 (Deposition) - 20 Mar 07 (Release) - 24 Feb 09 (Revision) |
|---|
| Method | : | SOLUTION NMR |
|---|
| Resolution | : | NOT APPLICABLE |
|---|
| Chains | : | NMR Structure : A (20x) |
|---|
| Keywords | : | Age Related Macular Degeneration, Age-Related Macular Degeneration, Disease Mutation, Glycosaminoglycan, Alternative Splicing, Complement Alternate Pathway, Glycoprotein, Innate Immunity, Immune Response, Sushi, Factor H, Complement, Polymorphism (Keyword Search: [Gene Ontology, PubMed, Web (Google)] ) |
|---|
| |
|---|
| Reference | : | A. P. Herbert, J. A. Deakin, C. Q. Schmidt, B. S. Blaum, C. Egan, V. P. Ferreira, M. K. Pangburn, M. Lyon, D. Uhrin, P. N. Barlow
Structure Shows That A Glycosaminoglycan And Protein Recognition Site In Factor H Is Perturbed By Age-Related Macular Degeneration-Linked Single Nucleotide Polymorphism.
J. Biol. Chem. V. 282 18960 2007 |
|---|
|
 Description
Description