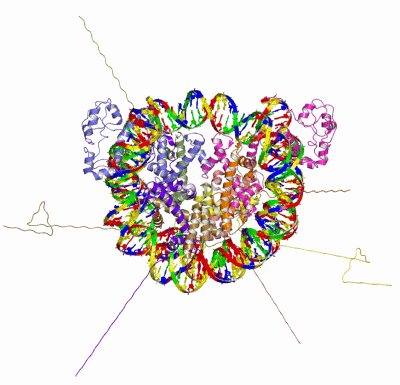
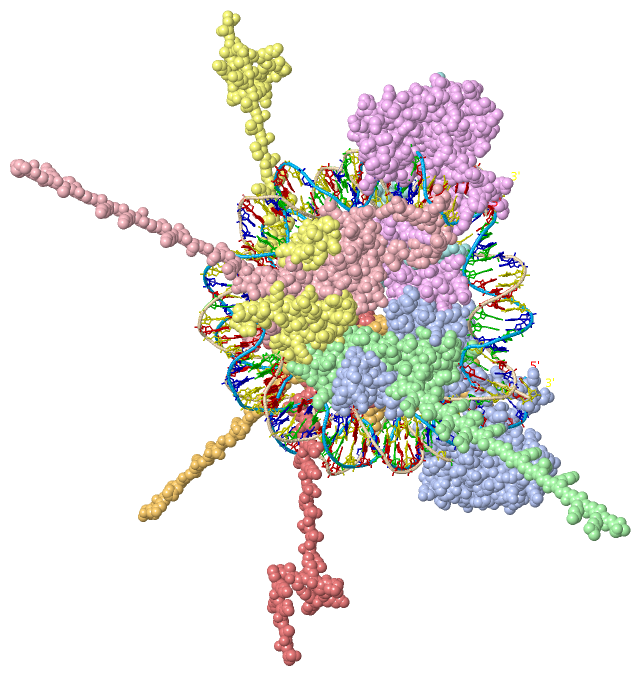
Theoretical Model(hide GO term definitions)
Chain B,F ( H4_YEAST | P02309)
| molecular function |
|---|
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0046982 | | protein heterodimerization activity | | Interacting selectively and non-covalently with a nonidentical protein to form a heterodimer. |
| biological process |
|---|
| | GO:0006333 | | chromatin assembly or disassembly | | The formation or destruction of chromatin structures. |
| | GO:0034729 | | histone H3-K79 methylation | | The modification of histone H3 by addition of a methyl group to lysine at position 79 of the histone. |
| | GO:0006334 | | nucleosome assembly | | The aggregation, arrangement and bonding together of a nucleosome, the beadlike structural units of eukaryotic chromatin composed of histones and DNA. |
| | GO:0043935 | | sexual sporulation resulting in formation of a cellular spore | | The formation of spores derived from the products of meiosis. A cellular spore is a cell form that can be used for dissemination, for survival of adverse conditions because of its heat and dessication resistance, and/or for reproduction. |
| | GO:0061587 | | transfer RNA gene-mediated silencing | | The chromatin silencing that results in the inhibition of RNA polymerase II-transcribed genes located in the vicinity of tRNA genes. |
| cellular component |
|---|
| | GO:0005694 | | chromosome | | A structure composed of a very long molecule of DNA and associated proteins (e.g. histones) that carries hereditary information. |
| | GO:0000788 | | nuclear nucleosome | | A complex comprised of DNA wound around a multisubunit core and associated proteins, which forms the primary packing unit of DNA in the nucleus into higher order structures. |
| | GO:0000786 | | nucleosome | | A complex comprised of DNA wound around a multisubunit core and associated proteins, which forms the primary packing unit of DNA into higher order structures. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0031298 | | replication fork protection complex | | A protein complex conserved in eukaryotes and associated with the replication fork; the complex stabilizes stalled replication forks and is thought to be involved in coordinating leading- and lagging-strand synthesis and in replication checkpoint signaling. |
Chain C,G ( H2AZ_YEAST | Q12692)
| molecular function |
|---|
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0000978 | | RNA polymerase II core promoter proximal region sequence-specific DNA binding | | Interacting selectively and non-covalently with a sequence of DNA that is in cis with and relatively close to a core promoter for RNA polymerase II. |
| | GO:0031490 | | chromatin DNA binding | | Interacting selectively and non-covalently with DNA that is assembled into chromatin. |
| | GO:0003682 | | chromatin binding | | Interacting selectively and non-covalently with chromatin, the network of fibers of DNA, protein, and sometimes RNA, that make up the chromosomes of the eukaryotic nucleus during interphase. |
| | GO:0042802 | | identical protein binding | | Interacting selectively and non-covalently with an identical protein or proteins. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0046982 | | protein heterodimerization activity | | Interacting selectively and non-covalently with a nonidentical protein to form a heterodimer. |
| biological process |
|---|
| | GO:0006338 | | chromatin remodeling | | Dynamic structural changes to eukaryotic chromatin occurring throughout the cell division cycle. These changes range from the local changes necessary for transcriptional regulation to global changes necessary for chromosome segregation. |
| | GO:0030466 | | chromatin silencing at silent mating-type cassette | | Repression of transcription at silent mating-type loci by alteration of the structure of chromatin. |
| | GO:0070481 | | nuclear-transcribed mRNA catabolic process, non-stop decay | | The chemical reactions and pathways resulting in the breakdown of the transcript body of a nuclear-transcribed mRNA that is lacking a stop codon. |
| | GO:0006357 | | regulation of transcription from RNA polymerase II promoter | | Any process that modulates the frequency, rate or extent of transcription from an RNA polymerase II promoter. |
| | GO:0006355 | | regulation of transcription, DNA-templated | | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0006351 | | transcription, DNA-templated | | The cellular synthesis of RNA on a template of DNA. |
| cellular component |
|---|
| | GO:0005694 | | chromosome | | A structure composed of a very long molecule of DNA and associated proteins (e.g. histones) that carries hereditary information. |
| | GO:0000790 | | nuclear chromatin | | The ordered and organized complex of DNA, protein, and sometimes RNA, that forms the chromosome in the nucleus. |
| | GO:0005719 | | nuclear euchromatin | | The dispersed less dense form of chromatin in the interphase nucleus. It exists in at least two forms, a some being in the form of transcriptionally active chromatin which is the least condensed, while the rest is inactive euchromatin which is more condensed than active chromatin but less condensed than heterochromatin. |
| | GO:0000786 | | nucleosome | | A complex comprised of DNA wound around a multisubunit core and associated proteins, which forms the primary packing unit of DNA into higher order structures. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
Chain D,H ( H2B2_YEAST | P02294)
| molecular function |
|---|
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0046982 | | protein heterodimerization activity | | Interacting selectively and non-covalently with a nonidentical protein to form a heterodimer. |
| biological process |
|---|
| | GO:0006333 | | chromatin assembly or disassembly | | The formation or destruction of chromatin structures. |
| | GO:0006334 | | nucleosome assembly | | The aggregation, arrangement and bonding together of a nucleosome, the beadlike structural units of eukaryotic chromatin composed of histones and DNA. |
| cellular component |
|---|
| | GO:0005694 | | chromosome | | A structure composed of a very long molecule of DNA and associated proteins (e.g. histones) that carries hereditary information. |
| | GO:0000788 | | nuclear nucleosome | | A complex comprised of DNA wound around a multisubunit core and associated proteins, which forms the primary packing unit of DNA in the nucleus into higher order structures. |
| | GO:0000786 | | nucleosome | | A complex comprised of DNA wound around a multisubunit core and associated proteins, which forms the primary packing unit of DNA into higher order structures. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0031298 | | replication fork protection complex | | A protein complex conserved in eukaryotes and associated with the replication fork; the complex stabilizes stalled replication forks and is thought to be involved in coordinating leading- and lagging-strand synthesis and in replication checkpoint signaling. |
Chain E ( CENPA_YEAST | P36012)
| molecular function |
|---|
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0019237 | | centromeric DNA binding | | Interacting selectively and non-covalently with a centromere, a region of chromosome where the spindle fibers attach during mitosis and meiosis. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0046982 | | protein heterodimerization activity | | Interacting selectively and non-covalently with a nonidentical protein to form a heterodimer. |
| | GO:0043565 | | sequence-specific DNA binding | | Interacting selectively and non-covalently with DNA of a specific nucleotide composition, e.g. GC-rich DNA binding, or with a specific sequence motif or type of DNA e.g. promotor binding or rDNA binding. |
| biological process |
|---|
| | GO:0030543 | | 2-micrometer plasmid partitioning | | The process in which copies of the 2-micrometer plasmid, found in fungi such as Saccharomyces, are distributed to daughter cells upon cell division. |
| | GO:0000070 | | mitotic sister chromatid segregation | | The cell cycle process in which replicated homologous chromosomes are organized and then physically separated and apportioned to two sets during the mitotic cell cycle. Each replicated chromosome, composed of two sister chromatids, aligns at the cell equator, paired with its homologous partner. One homolog of each morphologic type goes into each of the resulting chromosome sets. |
| cellular component |
|---|
| | GO:0043505 | | CENP-A containing nucleosome | | A form of nucleosome located only at the centromere, in which the histone H3 is replaced by the variant form CENP-A (sometimes known as CenH3). |
| | GO:0005694 | | chromosome | | A structure composed of a very long molecule of DNA and associated proteins (e.g. histones) that carries hereditary information. |
| | GO:0000775 | | chromosome, centromeric region | | The region of a chromosome that includes the centromeric DNA and associated proteins. In monocentric chromosomes, this region corresponds to a single area of the chromosome, whereas in holocentric chromosomes, it is evenly distributed along the chromosome. |
| | GO:0000777 | | condensed chromosome kinetochore | | A multisubunit complex that is located at the centromeric region of a condensed chromosome and provides an attachment point for the spindle microtubules. |
| | GO:0000780 | | condensed nuclear chromosome, centromeric region | | The region of a condensed nuclear chromosome that includes the centromere and associated proteins, including the kinetochore. In monocentric chromosomes, this region corresponds to a single area of the chromosome, whereas in holocentric chromosomes, it is evenly distributed along the chromosome. |
| | GO:0005727 | | extrachromosomal circular DNA | | Circular DNA structures that are not part of a chromosome. |
| | GO:0000776 | | kinetochore | | A multisubunit complex that is located at the centromeric region of DNA and provides an attachment point for the spindle microtubules. |
| | GO:0000786 | | nucleosome | | A complex comprised of DNA wound around a multisubunit core and associated proteins, which forms the primary packing unit of DNA into higher order structures. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
|
 Description
Description