|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
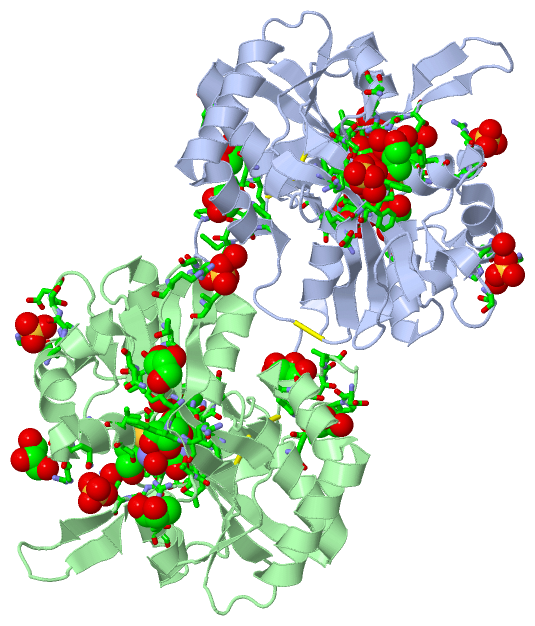
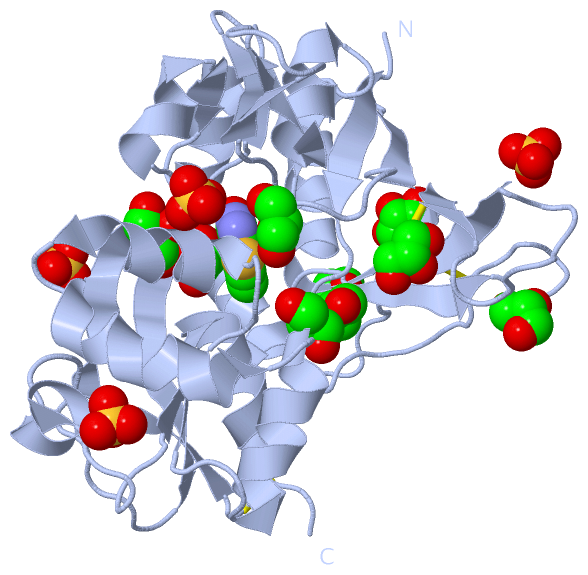
Ligands, Modified Residues, Ions (3, 28)
Asymmetric Unit (3, 28)
|
Sites (28, 28)
Asymmetric Unit (28, 28)
|
SS Bonds (5, 5)
Asymmetric Unit
|
||||||||||||||||||||||||
Cis Peptide Bonds (2, 2)
Asymmetric Unit
|
||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 4KFQ) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 4KFQ) |
Exons (0, 0)| (no "Exon" information available for 4KFQ) |
Sequences/Alignments
Asymmetric Unit
Chain A from PDB Type:PROTEIN Length:289
SCOP domains d4kfqa_ A: N-methyl-D-aspartate receptor subunit 1 SCOP domains
CATH domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains
Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
4kfq A 4 TRLKIVTIHQEPFVYVKPTMSDGTCKEEFTVNGDPVKKVICTGPNDTSPGSPRHTVPQCCYGFCIDLLIKLARTMNFTYEVHLVADGKFGTQERVNNSNKKEWNGMMGELLSGQADMIVAPLTINNERAQYIEFSKPFKYQGLTILVKKGTRITGINDPRLRNPSDKFIYATVKQSSVDIYFRRQVELSTMYRHMEKHNYESAAEAIQAVRDNKLHAFIWDSAVLEFEASQKCDLVTTGELFFRSGFGIGMRKDSPWKQNVSLSILKSHENGFMEDLDKTWVRYQECDS 292
13 23 33 43 53 63 73 83 93 103 113 123 133 143 153 163 173 183 193 203 213 223 233 243 253 263 273 283
Chain B from PDB Type:PROTEIN Length:282
SCOP domains d4kfqb_ B: N-methyl-D-aspartate receptor subunit 1 SCOP domains
CATH domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ CATH domains
Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Pfam domains
SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SAPs(SNPs)
PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ PROSITE
Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Transcript
4kfq B 5 RLKIVTIHQEPFVYVKPTMSDGTCKEEFTVNGDPVKKVICTGPNDTSPGSPRHTVPQCCYGFCIDLLIKLARTMNFTYEVHLVADGKFGTQERVNNSNKKEWNGMMGELLSGQADMIVAPLTINNERAQYIEFSKPFKYQGLTILVKKGTRITGINDPRLRNPSDKFIYATVKQSSVDIYFRRQVELSTMYRHMEKHNYESAAEAIQAVRDNKLHAFIWDSAVLEFEASQKCDLVTTGELFFRSGFGIGMRKDSPWKQNVSLSILKSHENGFMEDLDKTWVR 286
14 24 34 44 54 64 74 84 94 104 114 124 134 144 154 164 174 184 194 204 214 224 234 244 254 264 274 284
|
||||||||||||||||||||
SCOP Domains (1, 2)
Asymmetric Unit
 |
CATH Domains (0, 0)| (no "CATH Domain" information available for 4KFQ) |
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 4KFQ) |
Gene Ontology (45, 45)|
Asymmetric Unit(hide GO term definitions) |
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|