|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
( #: chains that contain no standard or modified protein/DNA/RNA residue)
Summary Information (see also Sequences/Alignments below) |
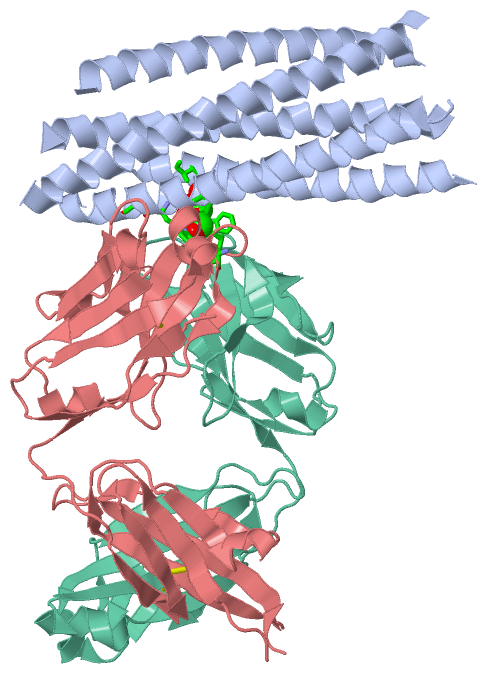
Ligands, Modified Residues, Ions (1, 1)
Asymmetric Unit (1, 1)
|
Sites (1, 1)
Asymmetric Unit (1, 1)
|
SS Bonds (4, 4)
Asymmetric Unit
|
||||||||||||||||||||
Cis Peptide Bonds (5, 5)
Asymmetric Unit
|
||||||||||||||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 2CMR) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 2CMR) |
Exons (0, 0)| (no "Exon" information available for 2CMR) |
Sequences/Alignments
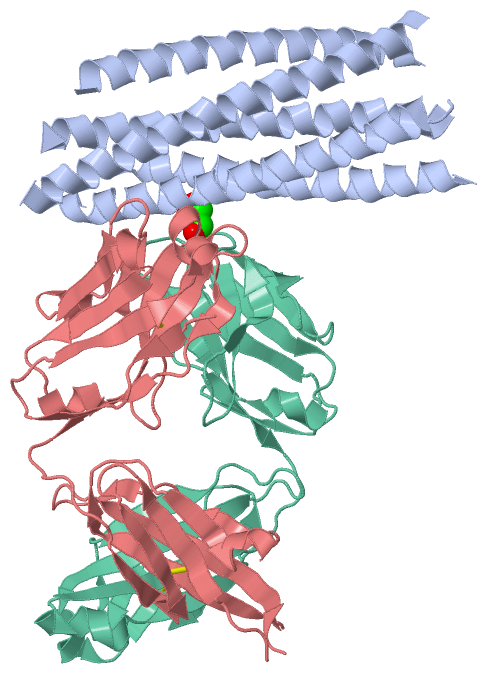
Asymmetric UnitChain A from PDB Type:PROTEIN Length:195 aligned with D0VWW0_9HIV1 | D0VWW0 from UniProtKB/TrEMBL Length:226 Alignment length:216 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 D0VWW0_9HIV1 1 MQLLSGIVQQQNNLLRAIEAQQHLLQLTVWGIKQLQARILAGGSGGHTTWMEWDREINNYTSLIHSLIEESQNQQEKNEQELLEGSSGGQLLSGIVQQQNNLLRAIEAQQHLLQLTVWGIKQLQARILAGGSGGHTTWMEWDREINNYTSLIHSLIEESQNQQEKNEQELLEGSSGGQLLSGIVQQQNNLLRAIEAQQHLLQLTVWGIKQLQARIL 216 SCOP domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SCOP domains CATH domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ CATH domains Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Pfam domains SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SAPs(SNPs) PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ PROSITE Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Transcript 2cmr A 1 MQLLSGIVQQQNNLLRAIEAQQHLLQLTVWGIKQLQARILAG------TWMEWDREINNYTSLIHSLIEESQNQQEKNEQELLE----GQLLSGIVQQQNNLLRAIEAQQHLLQLTVWGIKQLQARIL---------WMEWDREINNYTSLIHSLIEESQNQQEKNEQELLEG--GGQLLSGIVQQQNNLLRAIEAQQHLLQLTVWGIKQLQARIL 216 10 20 30 40 | 50 60 70 80 | 90 100 110 120 | - 140 150 160 170 | | 180 190 200 210 42 49 84 89 128 138 173 | 176 Chain A from PDB Type:PROTEIN Length:195 aligned with ENV_HV1H2 | P04578 from UniProtKB/Swiss-Prot Length:856 Alignment length:598 267 277 287 297 307 317 327 337 347 357 367 377 387 397 407 417 427 437 447 457 467 477 487 497 507 517 527 537 547 557 567 577 587 597 607 617 627 637 647 657 667 677 687 697 707 717 727 737 747 757 767 777 787 797 807 817 827 837 847 ENV_HV1H2 258 QLLLNGSLAEEEVVIRSVNFTDNAKTIIVQLNTSVEINCTRPNNNTRKRIRIQRGPGRAFVTIGKIGNMRQAHCNISRAKWNNTLKQIASKLREQFGNNKTIIFKQSSGGDPEIVTHSFNCGGEFFYCNSTQLFNSTWFNSTWSTEGSNNTEGSDTITLPCRIKQIINMWQKVGKAMYAPPISGQIRCSSNITGLLLTRDGGNSNNESEIFRPGGGDMRDNWRSELYKYKVVKIEPLGVAPTKAKRRVVQREKRAVGIGALFLGFLGAAGSTMGAASMTLTVQARQLLSGIVQQQNNLLRAIEAQQHLLQLTVWGIKQLQARILAVERYLKDQQLLGIWGCSGKLICTTAVPWNASWSNKSLEQIWNHTTWMEWDREINNYTSLIHSLIEESQNQQEKNEQELLELDKWASLWNWFNITNWLWYIKLFIMIVGGLVGLRIVFAVLSIVNRVRQGYSPLSFQTHLPTPRGPDRPEGIEEEGGERDRDRSIRLVNGSLALIWDDLRSLCLFSYHRLRDLLLIVTRIVELLGRRGWEALKYWWNLLQYWSQELKNSAVSLLNATAIAVAEGTDRVIEVVQGACRAIRHIPRRIRQGLERIL 855 SCOP domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SCOP domains CATH domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2cmr A 1 MQLLSGIVQQQNNLLRAI----EAQQHLLQLTV-----------------------------------------------WG--IKQLQARILAG-----------------------------------------TWMEWDR---------------------EINN---------YTSLIHSLIEESQNQQ----------EKNEQELLE------------------------------------------------------------------------GQLLSGIVQQQNNLLRAIEAQQHLLQLTVWGIKQLQARIL----------------------------------------------WMEWDREINNYTSLIHSLIEESQNQQEKNEQELLEG-------------------------------------------------------------------------GG--------QLLSG-----------------------------IVQQQN-----------NLL---------------------------RAIEAQQ---HLLQLTVWGIKQLQARIL 216 10 | - | 26 | - - - - -|| | 37 | - - - - | 52 | - - | | - |62 72 | - | 82 | - - - - - - - | 94 104 114 124 | - - - - -| 147 157 167 | - - - - - - - 176| 178 | - - - | |- -| | - - -| | -| 208 18 19 29 30| 32 42 49 55 56 59 60 75 76 84 89 128 138 173 176| 178 182 183 188 189 | 192 198 199 31 177 191
Chain H from PDB Type:PROTEIN Length:204
SCOP domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SCOP domains
CATH domains 2cmrH01 H:3-113 Immunoglobulins 2cmrH02 H:114-211 Immunoglobulins CATH domains
Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Pfam domains
SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SAPs(SNPs)
PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ PROSITE
Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Transcript
2cmr H 3 QLVQSGAEVRKPGASVKVSCKASGDTFSSYAISWVRQAPGQGLEWMGGIIPIFGTANYAQAFQGRVTITANESTSTAYMELSSLRSEDTAIYYCARDNPTLLGSDYWGAGTLVTVSSASTKGPSVFPLAGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSTQTYICNVNHKPSNTKVDKRV 211
12 22 32 42 52| 61 71 81 ||| 88 98 || 106 116 134 144 154 164 174 184 || 197 207
52A 82A|| 100A| 125| 187|
82B| 100B 134 191
82C
Chain L from PDB Type:PROTEIN Length:208
SCOP domains d2cmrl1 L:1-106A automated matches d2cmrl2 L:107-207 automated matches SCOP domains
CATH domains 2cmrL01 L:1-107 Immunoglobulins 2cmrL02 L:108-207 Immunoglobulins CATH domains
Pfam domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
2cmr L 1 DIQMTQSPSTLSASIGDRVTITCRASEGIYHWLAWYQQKPGKAPKLLIYKASSLASGAPSRFSGSGSGTDFTLTISSLQPDDFATYYCQQYSNYPLTFGGGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKS 207
10 20 30 40 50 60 70 80 90 100 |109 119 129 139 149 159 169 179 189 199
106A
|
||||||||||||||||||||
SCOP Domains (2, 2)
Asymmetric Unit

|
CATH Domains (1, 4)
Asymmetric Unit
|
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 2CMR) |
Gene Ontology (32, 32)|
Asymmetric Unit(hide GO term definitions) Chain A (ENV_HV1H2 | P04578)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|