| molecular function |
|---|
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0008301 | | DNA binding, bending | | The activity of binding selectively and non-covalently to and distorting the original structure of DNA, typically a straight helix, into a bend, or increasing the bend if the original structure was intrinsically bent due to its sequence. |
| | GO:0098505 | | G-rich strand telomeric DNA binding | | Interacting selectively and non-covalently with G-rich, single-stranded, telomere-associated DNA. |
| | GO:0003691 | | double-stranded telomeric DNA binding | | Interacting selectively and non-covalently with double-stranded telomere-associated DNA. |
| | GO:0008017 | | microtubule binding | | Interacting selectively and non-covalently with microtubules, filaments composed of tubulin monomers. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0046982 | | protein heterodimerization activity | | Interacting selectively and non-covalently with a nonidentical protein to form a heterodimer. |
| | GO:0042803 | | protein homodimerization activity | | Interacting selectively and non-covalently with an identical protein to form a homodimer. |
| | GO:0003720 | | telomerase activity | | Catalysis of the reaction: deoxynucleoside triphosphate + DNA(n) = diphosphate + DNA(n+1). Catalyzes extension of the 3'- end of a DNA strand by one deoxynucleotide at a time using an internal RNA template that encodes the telomeric repeat sequence. |
| | GO:0042162 | | telomeric DNA binding | | Interacting selectively and non-covalently with a telomere, a specific structure at the end of a linear chromosome required for the integrity and maintenance of the end. |
| | GO:0043130 | | ubiquitin binding | | Interacting selectively and non-covalently with ubiquitin, a protein that when covalently bound to other cellular proteins marks them for proteolytic degradation. |
| biological process |
|---|
| | GO:0000086 | | G2/M transition of mitotic cell cycle | | The mitotic cell cycle transition by which a cell in G2 commits to M phase. The process begins when the kinase activity of M cyclin/CDK complex reaches a threshold high enough for the cell cycle to proceed. This is accomplished by activating a positive feedback loop that results in the accumulation of unphosphorylated and active M cyclin/CDK complex. |
| | GO:0007049 | | cell cycle | | The progression of biochemical and morphological phases and events that occur in a cell during successive cell replication or nuclear replication events. Canonically, the cell cycle comprises the replication and segregation of genetic material followed by the division of the cell, but in endocycles or syncytial cells nuclear replication or nuclear division may not be followed by cell division. |
| | GO:0051301 | | cell division | | The process resulting in division and partitioning of components of a cell to form more cells; may or may not be accompanied by the physical separation of a cell into distinct, individually membrane-bounded daughter cells. |
| | GO:0045141 | | meiotic telomere clustering | | The cell cycle process in which the dynamic reorganization of telomeres occurs in early meiotic prophase, during which meiotic chromosome ends are gathered in a bouquet arrangement at the inner surface of the nuclear envelope proximal to the spindle pole body. This plays an important role in progression through meiosis and precedes synapsis. |
| | GO:0007094 | | mitotic spindle assembly checkpoint | | A cell cycle checkpoint that delays the metaphase/anaphase transition of a mitotic nuclear division until the spindle is correctly assembled and chromosomes are attached to the spindle. |
| | GO:0008156 | | negative regulation of DNA replication | | Any process that stops, prevents, or reduces the frequency, rate or extent of DNA replication. |
| | GO:1904911 | | negative regulation of establishment of RNA localization to telomere | | Any process that stops, prevents or reduces the frequency, rate or extent of establishment of RNA localization to telomere. |
| | GO:1904914 | | negative regulation of establishment of macromolecular complex localization to telomere | | Any process that stops, prevents or reduces the frequency, rate or extent of establishment of macromolecular complex localization to telomere. |
| | GO:1904850 | | negative regulation of establishment of protein localization to telomere | | Any process that stops, prevents or reduces the frequency, rate or extent of establishment of protein localization to telomere. |
| | GO:0051974 | | negative regulation of telomerase activity | | Any process that stops or reduces the activity of the enzyme telomerase, which catalyzes of the reaction: deoxynucleoside triphosphate + DNA(n) = diphosphate + DNA(n+1). |
| | GO:0032214 | | negative regulation of telomere maintenance via semi-conservative replication | | Any process that stops, prevents, or reduces the frequency, rate or extent of the semi-conservative replication of telomeric DNA. |
| | GO:0032211 | | negative regulation of telomere maintenance via telomerase | | Any process that stops, prevents, or reduces the frequency, rate or extent of the addition of telomeric repeats by telomerase. |
| | GO:0043065 | | positive regulation of apoptotic process | | Any process that activates or increases the frequency, rate or extent of cell death by apoptotic process. |
| | GO:0031116 | | positive regulation of microtubule polymerization | | Any process that activates or increases the frequency, rate or extent of microtubule polymerization. |
| | GO:0045931 | | positive regulation of mitotic cell cycle | | Any process that activates or increases the rate or extent of progression through the mitotic cell cycle. |
| | GO:0045840 | | positive regulation of mitotic nuclear division | | Any process that activates or increases the frequency, rate or extent of mitosis. |
| | GO:1904792 | | positive regulation of shelterin complex assembly | | Any process that activates or increases the frequency, rate or extent of shelterin complex assembly. |
| | GO:0051260 | | protein homooligomerization | | The process of creating protein oligomers, compounds composed of a small number, usually between three and ten, of identical component monomers. Oligomers may be formed by the polymerization of a number of monomers or the depolymerization of a large protein polymer. |
| | GO:0042493 | | response to drug | | Any process that results in a change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a drug stimulus. A drug is a substance used in the diagnosis, treatment or prevention of a disease. |
| | GO:0016233 | | telomere capping | | A process in which telomeres are protected from degradation and fusion, thereby ensuring chromosome stability by protecting the ends from both degradation and from being recognized as damaged DNA. May be mediated by specific single- or double-stranded telomeric DNA binding proteins. |
| | GO:0000723 | | telomere maintenance | | Any process that contributes to the maintenance of proper telomeric length and structure by affecting and monitoring the activity of telomeric proteins, the length of telomeric DNA and the replication and repair of the DNA. These processes includes those that shorten, lengthen, replicate and repair the telomeric DNA sequences. |
| | GO:0007004 | | telomere maintenance via telomerase | | The maintenance of proper telomeric length by the addition of telomeric repeats by telomerase. |
| | GO:0031627 | | telomeric loop formation | | The process in which linear telomeric DNA is remodeled into duplex loops, by the invasion of a 3' single-stranded overhang into the duplex region. |
| cellular component |
|---|
| | GO:0005694 | | chromosome | | A structure composed of a very long molecule of DNA and associated proteins (e.g. histones) that carries hereditary information. |
| | GO:0000781 | | chromosome, telomeric region | | The terminal region of a linear chromosome that includes the telomeric DNA repeats and associated proteins. |
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0005856 | | cytoskeleton | | Any of the various filamentous elements that form the internal framework of cells, and typically remain after treatment of the cells with mild detergent to remove membrane constituents and soluble components of the cytoplasm. The term embraces intermediate filaments, microfilaments, microtubules, the microtrabecular lattice, and other structures characterized by a polymeric filamentous nature and long-range order within the cell. The various elements of the cytoskeleton not only serve in the maintenance of cellular shape but also have roles in other cellular functions, including cellular movement, cell division, endocytosis, and movement of organelles. |
| | GO:0000784 | | nuclear chromosome, telomeric region | | The terminal region of a linear nuclear chromosome that includes the telomeric DNA repeats and associated proteins. |
| | GO:0000783 | | nuclear telomere cap complex | | A complex of DNA and protein located at the end of a linear chromosome in the nucleus that protects and stabilizes a linear chromosome. |
| | GO:0005730 | | nucleolus | | A small, dense body one or more of which are present in the nucleus of eukaryotic cells. It is rich in RNA and protein, is not bounded by a limiting membrane, and is not seen during mitosis. Its prime function is the transcription of the nucleolar DNA into 45S ribosomal-precursor RNA, the processing of this RNA into 5.8S, 18S, and 28S components of ribosomal RNA, and the association of these components with 5S RNA and proteins synthesized outside the nucleolus. This association results in the formation of ribonucleoprotein precursors; these pass into the cytoplasm and mature into the 40S and 60S subunits of the ribosome. |
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0070187 | | shelterin complex | | A nuclear telomere cap complex that is formed by the association of telomeric ssDNA- and dsDNA-binding proteins with telomeric DNA, and is involved in telomere protection and recruitment of telomerase. The complex is known to contain TERF1, TERF2, POT1, RAP1, TINF2 and ACD in mammalian cells, and Pot1, Tpz1, Rap1, Rif1, Rif2 and Taz1 in Schizosaccharomyces. Taz1 and Rap1 (or their mammalian equivalents) form a dsDNA-binding subcomplex, Pot1 and Tpz1 form an ssDNA-binding subcomplex, and the two subcomplexes are bridged by Poz1, which acts as an effector molecule along with Ccq1. |
| | GO:0005819 | | spindle | | The array of microtubules and associated molecules that forms between opposite poles of a eukaryotic cell during mitosis or meiosis and serves to move the duplicated chromosomes apart. |
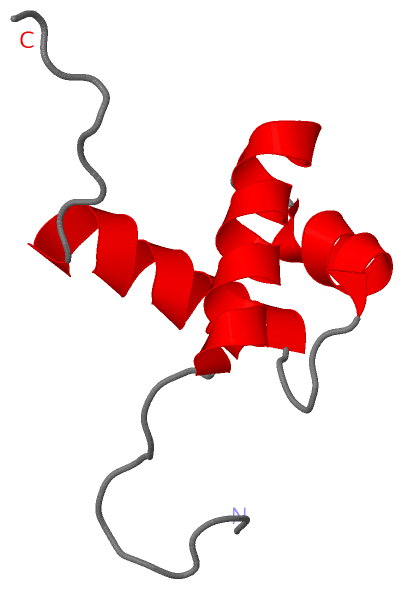
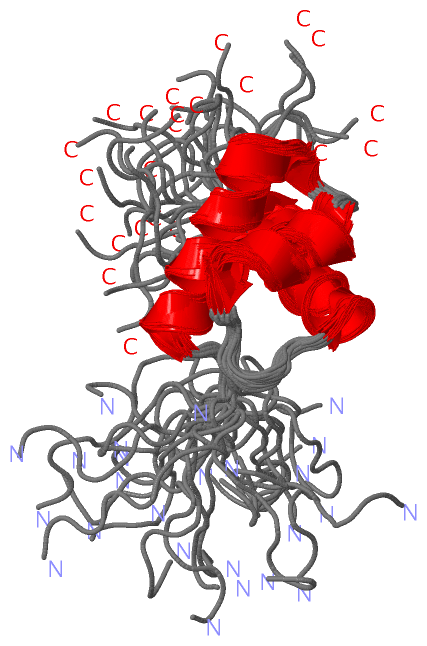
 Description
Description