|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (4, 6)| Asymmetric/Biological Unit (4, 6) |
Sites (7, 7)
Asymmetric Unit (7, 7)
|
SS Bonds (4, 4)
Asymmetric/Biological Unit
|
||||||||||||||||||||
Cis Peptide Bonds (2, 2)
Asymmetric/Biological Unit
|
||||||||||||
SAPs(SNPs)/Variants (1, 1)
Asymmetric/Biological Unit (1, 1)
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||
PROSITE Motifs (3, 3)
Asymmetric/Biological Unit (3, 3)
|
||||||||||||||||||||||||||||||||||||||||
Exons (3, 3)
Sequences/Alignments
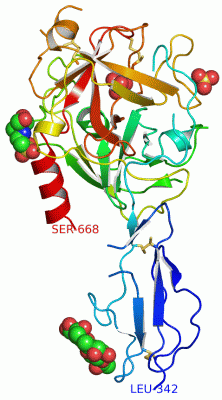
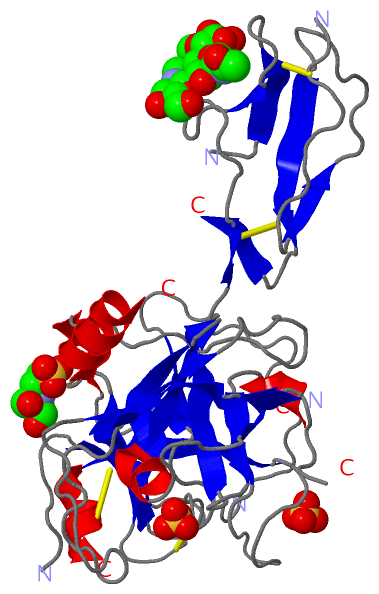
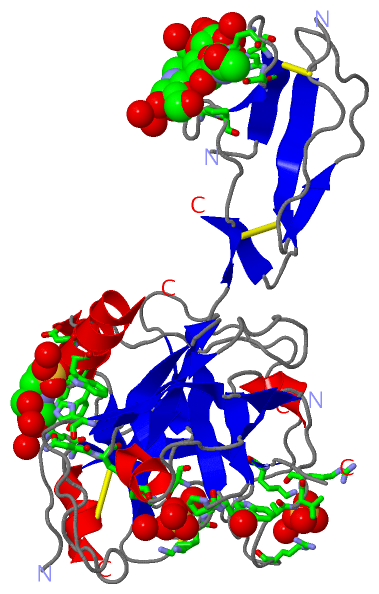
Asymmetric/Biological UnitChain A from PDB Type:PROTEIN Length:303 aligned with C1S_HUMAN | P09871 from UniProtKB/Swiss-Prot Length:688 Alignment length:327 366 376 386 396 406 416 426 436 446 456 466 476 486 496 506 516 526 536 546 556 566 576 586 596 606 616 626 636 646 656 666 676 C1S_HUMAN 357 VDCGIPESIENGKVEDPESTLFGSVIRYTCEEPYYYMENGGGGEYHCAGNGSWVNEVLGPELPKCVPVCGVPREPFEEKQRIIGGSDADIKNFPWQVFFDNPWAGGALINEYWVLTAAHVVEGNREPTMYVGSTSVQTSRLAKSKMLTPEHVFIHPGWKLLEVPEGRTNFDNDIALVRLKDPVKMGPTVSPICLPGTSSDYNLMDGDLGLISGWGRTEKRDRAVRLKAARLPVAPLRKCKEVKVEKPTADAEAYVFTPNMICAGGEKGMDSCKGDSGGAFAVQDPNDKTKFYAAGLVSWGPQCGTYGLYTRVKNYVDWIMKTMQENS 683 SCOP domains d1elva2 A:342-409 Complement C1S prote ase domain d1elva1 A:410-668 Complement C1S protease, catalytic domain SCOP domains CATH domains 1elvA03 A:342-409 Complement Module, d omain 1 -------- 1elvA02 1elvA01 A:437-532,A:656-664 Trypsin-like s erine proteases -1elvA02 A:423-436,A:534-655 Trypsin-like serine pr oteases 1elvA01 ---- CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------H------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SAPs(SNPs) PROSITE (1) SUSHI PDB: A:343-408 UniProt: 357-423 --------------TRYPSIN_DOM PDB: A:423-665 UniProt: 438-680 --- PROSITE (1) PROSITE (2) -----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------TRYPSIN_SER ---------------------------------------------- PROSITE (2) Transcript 1 (1) Exon 1.13c PDB: A:342-384 (gaps) ------------------------Exon 1.17c PDB: A:409-668 (gaps) UniProt: 424-688 [INCOMPLETE] Transcript 1 (1) Transcript 1 (2) ------------------------------------------Exon 1.15b PDB: A:384-409------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1 (2) 1elv A 342 LDCGIPESIENGKVEDPESTLFGSVIRYTCEEPYYYME--GGGEYHCAGNGSWVNEVLGPELPKCVPVCGVPREPF-----IIGGSDADIKNFPWQVFFDNPWAGGALINEYWVLTAAHVVEGNREPTMYVGSTSVQ-------KMLTPEHVFIHPGWKLLAVPEGRTNFDNDIALVRLKDPVKMGPTVSPICLPGTSSDYNLMDGDLGLISGWGRTEKRDRAVRLKAARLPVAPLRKCKEV----------AYVFTPNMICAGGEKGMDSCKGDSGGAFAVQDPNDKTKFYAAGLVSWGPQCGTYGLYTRVKNYVDWIMKTMQENS 668 351 361 371 | -| 391 401 411 | - | 431 441 451 461 471 | - | 491 501 511 521 531 541 551 561 571 581 | - | 601 611 621 631 641 651 661 379 | 417 423 478 486 583 594 382
|
||||||||||||||||||||
SCOP Domains (2, 2)
Asymmetric/Biological Unit
 |
CATH Domains (2, 3)
Asymmetric/Biological Unit
|
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 1ELV) |
Gene Ontology (16, 16)|
Asymmetric/Biological Unit(hide GO term definitions) Chain A (C1S_HUMAN | P09871)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|