|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
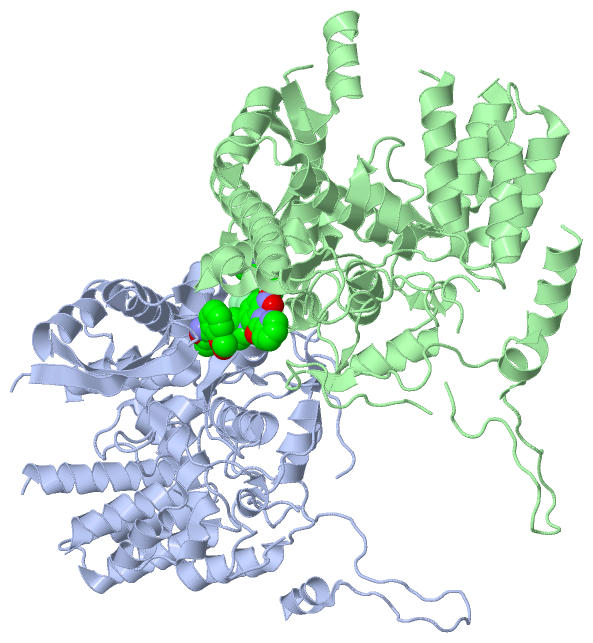
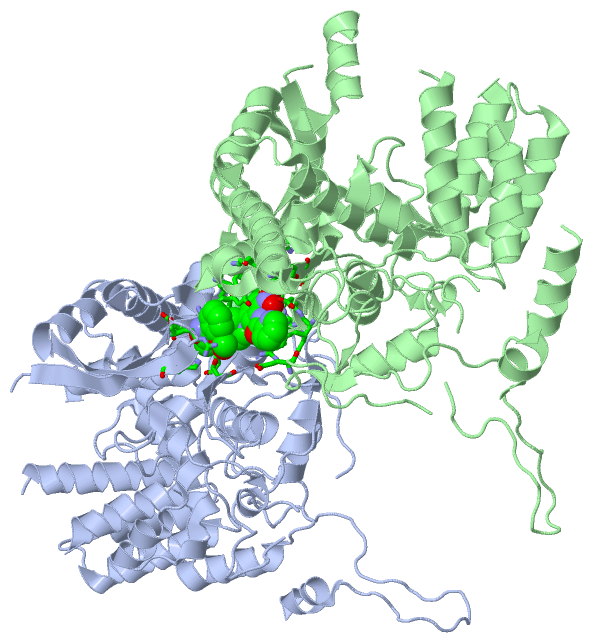
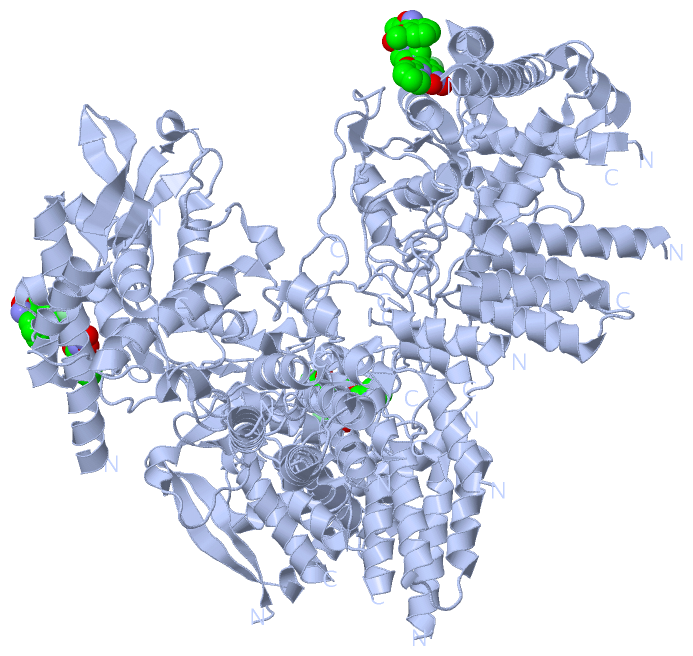
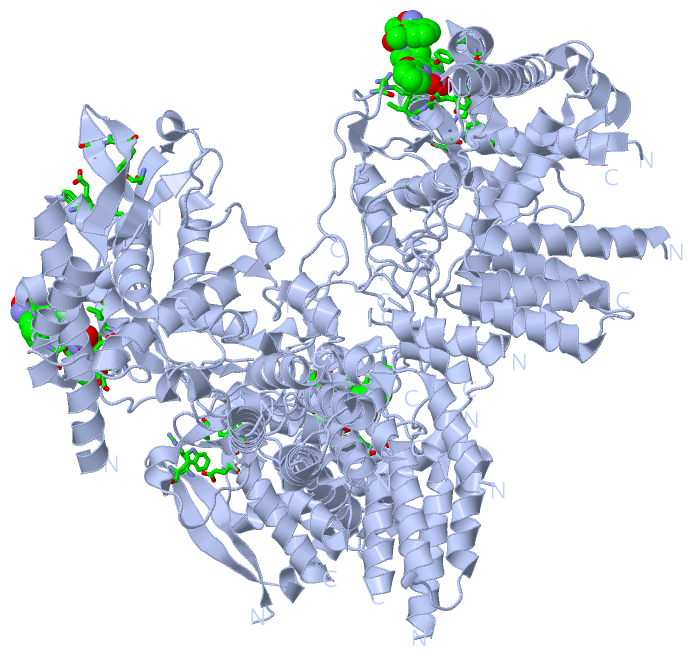
Ligands, Modified Residues, Ions (1, 2)
Asymmetric Unit (1, 2)
|
Sites (2, 2)
Asymmetric Unit (2, 2)
|
SS Bonds (0, 0)| (no "SS Bond" information available for 4DYN) |
Cis Peptide Bonds (0, 0)| (no "Cis Peptide Bond" information available for 4DYN) |
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 4DYN) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 4DYN) |
Exons (0, 0)| (no "Exon" information available for 4DYN) |
Sequences/Alignments
Asymmetric UnitChain A from PDB Type:PROTEIN Length:437 aligned with Q1K9H2_I33A0 | Q1K9H2 from UniProtKB/TrEMBL Length:498 Alignment length:480 28 38 48 58 68 78 88 98 108 118 128 138 148 158 168 178 188 198 208 218 228 238 248 258 268 278 288 298 308 318 328 338 348 358 368 378 388 398 408 418 428 438 448 458 468 478 488 498 Q1K9H2_I33A0 19 RQNATEIRASVGKMIDGIGRFYIQMCTELKLSDYEGRLIQNSLTIERMVLSAFDERRNKYLEEHPSAGKDPKKTGGPIYRRVDGKWRRELILYDKEEIRRIWRQANNGDDATAGLTHMMIWHSNLNDATYQRTRALVRTGMDPRMCSLMQGSTLPRRSGAAGAAVKGVGTMVMELIRMIKRGINDRNFWRGENGRRTRIAYERMCNILKGKFQTAAQRTMVDQVRESRNPGNAEFEDLIFLARSALILRGSVAHKSCLPACVYGSAVASGYDFEREGYSLVGIDPFRLLQNSQVYSLIRPNENPAHKSQLVWMACHSAAFEDLRVSSFIRGTKVVPRGKLSTRGVQIASNENMETMESSTLELRSRYWAIRTRSGGNTNQQRASSGQISIQPTFSVQRNLPFDRPTIMAAFTGNTEGRTSDMRTEIIRLMESARPEDVSFQGRGVFELSDEKATSPIVPSFDMSNEGSYFFGDNAEEYDN 498 SCOP domains d4dyna_ A: Nucleocapsid protein SCOP domains CATH domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ CATH domains Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Pfam domains SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SAPs(SNPs) PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ PROSITE Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Transcript 4dyn A 19 RQNATEIRASVGKMIDGIGRFYIQMCTELKLSDYEGRLIQNSLTIERMVLSAFD----------------PKKTGGPIYRRVDGKWRRELILYDKEEIRRIWRQANNGDDATAGLTHMMIWHSNLNDATYQRTRALVRTGMDPRMCSLMQGSTLPRRSGAAGAAVKGVGTMVMELIRMIK-------------GRRTRIAYERMCNILKGKFQTAAQRTMVDQVRESRNPGNAEFEDLIFLARSALILRGSVAHKSCLPACVYGSAVASGYDFEREGYSLVGIDPFRLLQNSQVYSLIRPNENPAHKSQLVWMACHSAAFEDLRVSSFIRGTKVVPRGKLSTRGVQIASNENMETMESSTLELRSRYWAIRTRSGGNTNQQRASSGQISIQPTFSVQRNLPFDRPTIMAAF---------DMRTEIIRLMESARPEDVSFQGRGVFELSDEKATSPIVPSF-----GSYFFGDNAEEYDN 498 28 38 48 58 68 | - -| 98 108 118 128 138 148 158 168 178 188 198 - | 218 228 238 248 258 268 278 288 298 308 318 328 338 348 358 368 378 388 398 408 418 428| -| 448 458 468 478| |488 498 72 89 198 212 429 439 479 485 Chain B from PDB Type:PROTEIN Length:437 aligned with Q1K9H2_I33A0 | Q1K9H2 from UniProtKB/TrEMBL Length:498 Alignment length:482 18 28 38 48 58 68 78 88 98 108 118 128 138 148 158 168 178 188 198 208 218 228 238 248 258 268 278 288 298 308 318 328 338 348 358 368 378 388 398 408 418 428 438 448 458 468 478 488 Q1K9H2_I33A0 9 SYEQMETDGERQNATEIRASVGKMIDGIGRFYIQMCTELKLSDYEGRLIQNSLTIERMVLSAFDERRNKYLEEHPSAGKDPKKTGGPIYRRVDGKWRRELILYDKEEIRRIWRQANNGDDATAGLTHMMIWHSNLNDATYQRTRALVRTGMDPRMCSLMQGSTLPRRSGAAGAAVKGVGTMVMELIRMIKRGINDRNFWRGENGRRTRIAYERMCNILKGKFQTAAQRTMVDQVRESRNPGNAEFEDLIFLARSALILRGSVAHKSCLPACVYGSAVASGYDFEREGYSLVGIDPFRLLQNSQVYSLIRPNENPAHKSQLVWMACHSAAFEDLRVSSFIRGTKVVPRGKLSTRGVQIASNENMETMESSTLELRSRYWAIRTRSGGNTNQQRASSGQISIQPTFSVQRNLPFDRPTIMAAFTGNTEGRTSDMRTEIIRLMESARPEDVSFQGRGVFELSDEKATSPIVPSFDMSNEGSYFFG 490 SCOP domains d4dynb_ B: Nucleocapsid protein SCOP domains CATH domains -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 4dyn B 9 SYEQMETDGERQNATEIRASVGKMIDGIGRFYIQMCTELKLSDYEGRLIQNSLTIERMVLSAFDERRNKYLEEHP----DPKKTGGPIYRRVDGKWRRELILYDKEEIRRIWRQANNGDDATAGLTHMMIWHSNLNDATYQRTRALVRTGMDPRMCSLMQGSTLPRRSGAAGAAVKGVGTMVMELIRMIKR--------------RTRIAYERMCNILKGKFQTAAQRTMVDQVRESRNPGNAEFEDLIFLARSALILRGSVAHKSCLPACVYGSAVASGYDFEREGYSLVGIDPFRLLQNSQVYSLIRPNENPAHKSQLVWMACHSAAFEDLRVSSFIRGTKVVPRGKLSTRGVQIASNENMETMESSTLELRSRYWAIRTRSG--------SSGQISIQPTFSVQRNLPFDRPTIMAA------------RTEIIRLMESARPEDVSFQGRGVFELSDEKATSPIVPS-------SYFFG 490 18 28 38 48 58 68 78 | 88 98 108 118 128 138 148 158 168 178 188 198| - | 218 228 238 248 258 268 278 288 298 308 318 328 338 348 358 368 378 388 | - | 408 418 428 - | 448 458 468 478 488 83 88 199 214 393 402 428 441 478 486
|
||||||||||||||||||||
SCOP Domains (1, 2)
Asymmetric Unit
 |
CATH Domains (0, 0)| (no "CATH Domain" information available for 4DYN) |
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 4DYN) |
Gene Ontology (10, 20)|
Asymmetric Unit(hide GO term definitions) Chain A,B (Q1K9H2_I33A0 | Q1K9H2)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|