|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (4, 9)
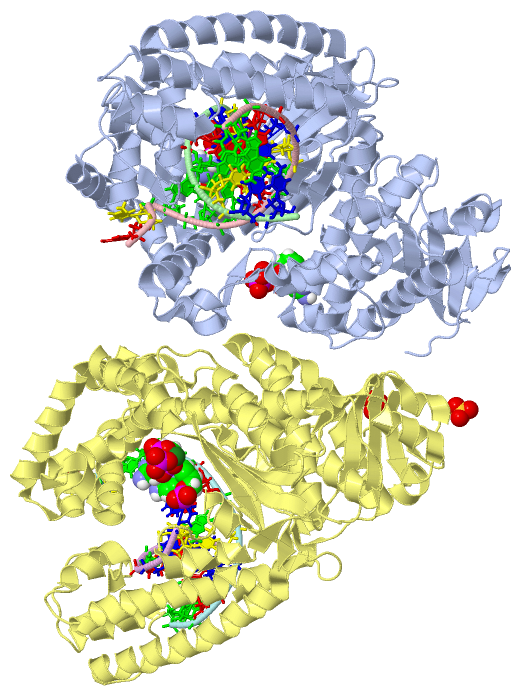
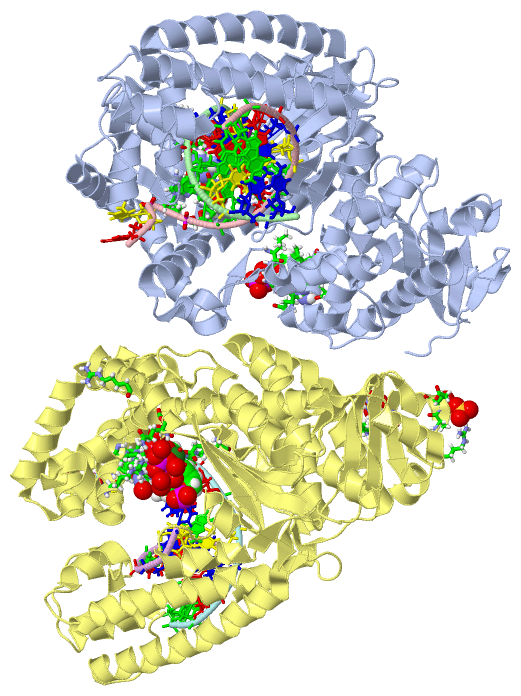
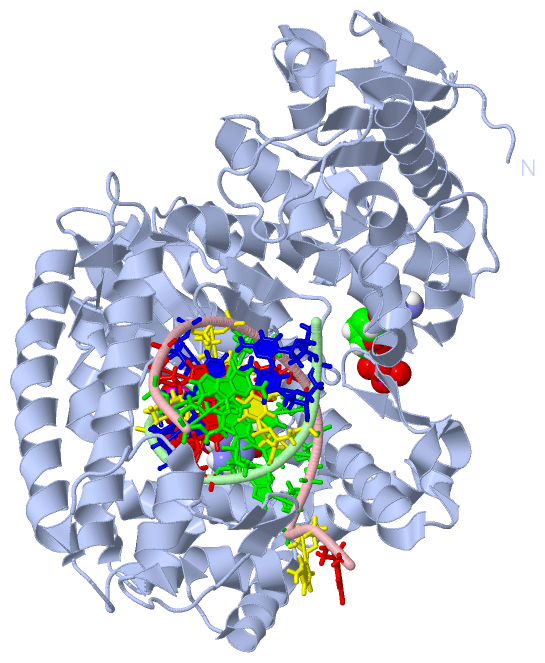
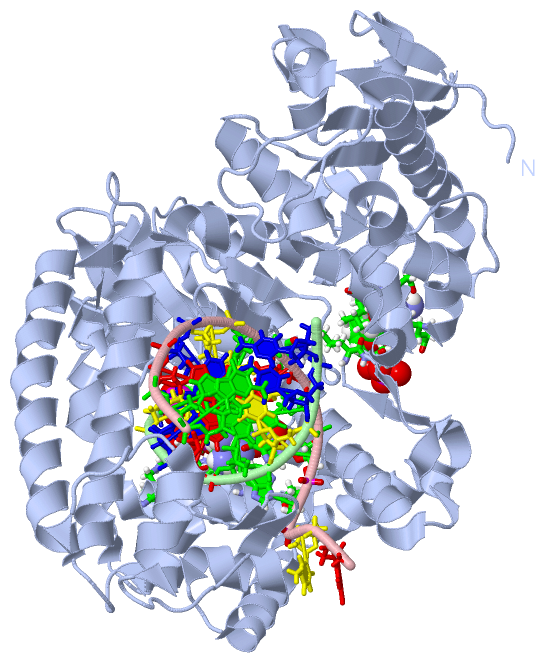
Asymmetric Unit (4, 9)
|
Sites (7, 7)
Asymmetric Unit (7, 7)
|
SS Bonds (0, 0)| (no "SS Bond" information available for 4DQP) |
Cis Peptide Bonds (2, 2)
Asymmetric Unit
|
||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 4DQP) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 4DQP) |
Exons (0, 0)| (no "Exon" information available for 4DQP) |
Sequences/Alignments
Asymmetric UnitChain A from PDB Type:PROTEIN Length:576 aligned with Q5KWC1_GEOKA | Q5KWC1 from UniProtKB/TrEMBL Length:878 Alignment length:580 308 318 328 338 348 358 368 378 388 398 408 418 428 438 448 458 468 478 488 498 508 518 528 538 548 558 568 578 588 598 608 618 628 638 648 658 668 678 688 698 708 718 728 738 748 758 768 778 788 798 808 818 828 838 848 858 868 878 Q5KWC1_GEOKA 299 AKMAFTLADRVTEEMLADKAALVVEVVEENYHDAPIVGIAVVNEHGRFFLRPETALADPQFVAWLGDETKKKSMFDSKRAAVALKWKGIELCGVSFDLLLAAYLLDPAQGVDDVAAAAKMKQYEAVRPDEAVYGKGAKRAVPDEPVLAEHLVRKAAAIWELERPFLDELRRNEQDRLLVELEQPLSSILAEMEFAGVKVDTKRLEQMGKELAEQLGTVEQRIYELAGQEFNINSPKQLGVILFEKLQLPVLKKTKTGYSTSADVLEKLAPYHEIVENILHYRQLGKLQSTYIEGLLKVVRPDTKKVHTIFNQALTQTGRLSSTEPNLQNIPIRLEEGRKIRQAFVPSESDWLIFAADYSQIELRVLAHIAEDDNLMEAFRRDLDIHTKTAMDIFQVSEDEVTPNMRRQAKAVNFGIVYGISDYGLAQNLNISRKEAAEFIERYFESFPGVKRYMENIVQEAKQKGYVTTLLHRRRYLPDITSRNFNVRSFAERMAMNTPIQGSAADIIKKAMIDLNARLKEERLQARLLLQVHDELILEAPKEEMERLCRLVPEVMEQAVTLRVPLKVDYHYGSTWYDAK 878 SCOP domains d4dqpa1 A:297-468 automated matches d4dqpa2 A:469-876 automated matches SCOP domains CATH domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 4dqp A 297 AKMAFTLADRVTEEMLADKAALVVEVVEENYHDAPIVGIAVVNEHGRFFLRPETALADPQFVAWLGDETKKKSMFDSKRAAVALKWKGIELCGVSFDLLLAAYLLDPAQGVDDVAAAAKMKQYEAVRPDEAVYGKGAKRAVPDEPVLAEHLVRKAAAIWELERPFLDELRRNEQDRLLVELEQPLSSILAEMEFAGVKVDTKRLEQMGKELAEQLGTVEQRIYELAGQEFNINSPKQLGVILFEKLQLPVLKKTKTGYSTSADVLEKLAPYHEIVENILHYRQLGKLQSTYIEGLLKVVRPATKKVHTIFNQALTQTGRLSSTEPNLQNIPIRLEEGRKIRQAFVPSESDWLIFAADYSQIELRVLAHIAEDDNLMEAF----DIHTKTAMDIFQVSEDEVTPNMRRQAKAVNFGIVYGISDYGLAQNLNISRKEAAEFIERYFESFPGVKRYMENIVQEAKQKGYVTTLLHRRRYLPDITSRNFNVRSFAERMAMNTPIQGSAADIIKKAMIDLNARLKEERLQAHLLLQVHDELILEAPKEEMERLCRLVPEVMEQAVTLRVPLKVDYHYGSTWYDAK 876 306 316 326 336 346 356 366 376 386 396 406 416 426 436 446 456 466 476 486 496 506 516 526 536 546 556 566 576 586 596 606 616 626 636 646 656 666 |- | 686 696 706 716 726 736 746 756 766 776 786 796 806 816 826 836 846 856 866 876 675 680
Chain B from PDB Type:DNA Length:9
4dqp B 21 CCTGACTCc 29
|
29-DOC
Chain C from PDB Type:DNA Length:12
4dqp C 1 ATGGGAGTCAGG 12
10
Chain D from PDB Type:PROTEIN Length:579 aligned with Q5KWC1_GEOKA | Q5KWC1 from UniProtKB/TrEMBL Length:878 Alignment length:579 309 319 329 339 349 359 369 379 389 399 409 419 429 439 449 459 469 479 489 499 509 519 529 539 549 559 569 579 589 599 609 619 629 639 649 659 669 679 689 699 709 719 729 739 749 759 769 779 789 799 809 819 829 839 849 859 869 Q5KWC1_GEOKA 300 KMAFTLADRVTEEMLADKAALVVEVVEENYHDAPIVGIAVVNEHGRFFLRPETALADPQFVAWLGDETKKKSMFDSKRAAVALKWKGIELCGVSFDLLLAAYLLDPAQGVDDVAAAAKMKQYEAVRPDEAVYGKGAKRAVPDEPVLAEHLVRKAAAIWELERPFLDELRRNEQDRLLVELEQPLSSILAEMEFAGVKVDTKRLEQMGKELAEQLGTVEQRIYELAGQEFNINSPKQLGVILFEKLQLPVLKKTKTGYSTSADVLEKLAPYHEIVENILHYRQLGKLQSTYIEGLLKVVRPDTKKVHTIFNQALTQTGRLSSTEPNLQNIPIRLEEGRKIRQAFVPSESDWLIFAADYSQIELRVLAHIAEDDNLMEAFRRDLDIHTKTAMDIFQVSEDEVTPNMRRQAKAVNFGIVYGISDYGLAQNLNISRKEAAEFIERYFESFPGVKRYMENIVQEAKQKGYVTTLLHRRRYLPDITSRNFNVRSFAERMAMNTPIQGSAADIIKKAMIDLNARLKEERLQARLLLQVHDELILEAPKEEMERLCRLVPEVMEQAVTLRVPLKVDYHYGSTWYDAK 878 SCOP domains d4dqpd1 D:298-468 automated matches d4dqpd2 D:469-876 automated matches SCOP domains CATH domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 4dqp D 298 KMAFTLADRVTEEMLADKAALVVEVVEENYHDAPIVGIAVVNEHGRFFLRPETALADPQFVAWLGDETKKKSMFDSKRAAVALKWKGIELCGVSFDLLLAAYLLDPAQGVDDVAAAAKMKQYEAVRPDEAVYGKGAKRAVPDEPVLAEHLVRKAAAIWELERPFLDELRRNEQDRLLVELEQPLSSILAEMEFAGVKVDTKRLEQMGKELAEQLGTVEQRIYELAGQEFNINSPKQLGVILFEKLQLPVLKKTKTGYSTSADVLEKLAPYHEIVENILHYRQLGKLQSTYIEGLLKVVRPATKKVHTIFNQALTQTGRLSSTEPNLQNIPIRLEEGRKIRQAFVPSESDWLIFAADYSQIELRVLAHIAEDDNLMEAFRRDLDIHTKTAMDIFQVSEDEVTPNMRRQAKAVNFGIVYGISDYGLAQNLNISRKEAAEFIERYFESFPGVKRYMENIVQEAKQKGYVTTLLHRRRYLPDITSRNFNVRSFAERMAMNTPIQGSAADIIKKAMIDLNARLKEERLQAHLLLQVHDELILEAPKEEMERLCRLVPEVMEQAVTLRVPLKVDYHYGSTWYDAK 876 307 317 327 337 347 357 367 377 387 397 407 417 427 437 447 457 467 477 487 497 507 517 527 537 547 557 567 577 587 597 607 617 627 637 647 657 667 677 687 697 707 717 727 737 747 757 767 777 787 797 807 817 827 837 847 857 867
Chain E from PDB Type:DNA Length:9
4dqp E 21 CCTGACTCc 29
|
29-DOC
Chain F from PDB Type:DNA Length:12
4dqp F 1 ATGGGAGTCAGG 12
10
|
||||||||||||||||||||
SCOP Domains (2, 4)
Asymmetric Unit
 |
CATH Domains (0, 0)| (no "CATH Domain" information available for 4DQP) |
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 4DQP) |
Gene Ontology (16, 16)|
Asymmetric Unit(hide GO term definitions) Chain A,D (Q5KWC1_GEOKA | Q5KWC1)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|