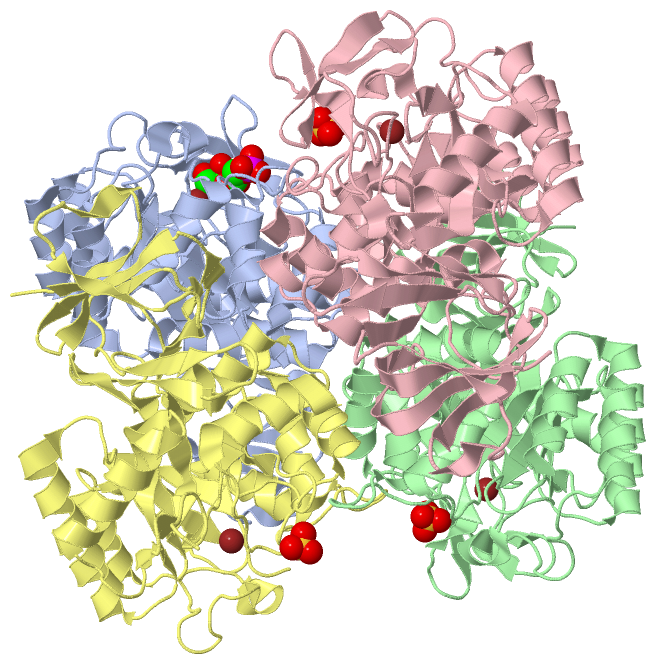
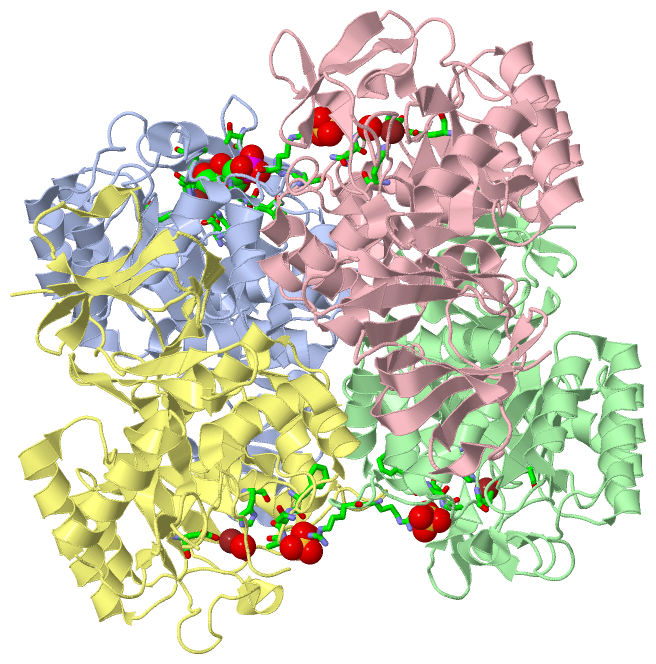
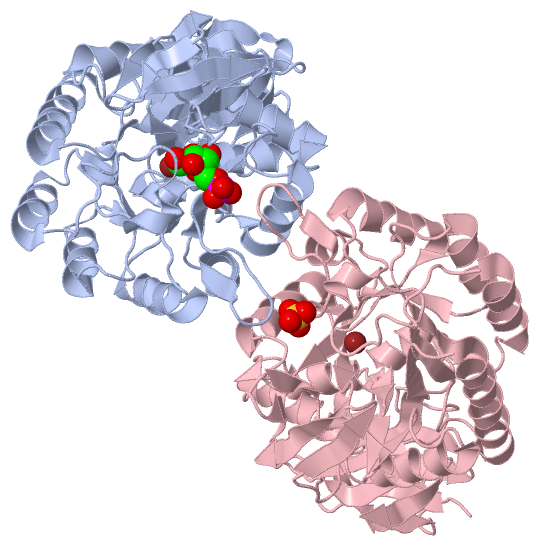
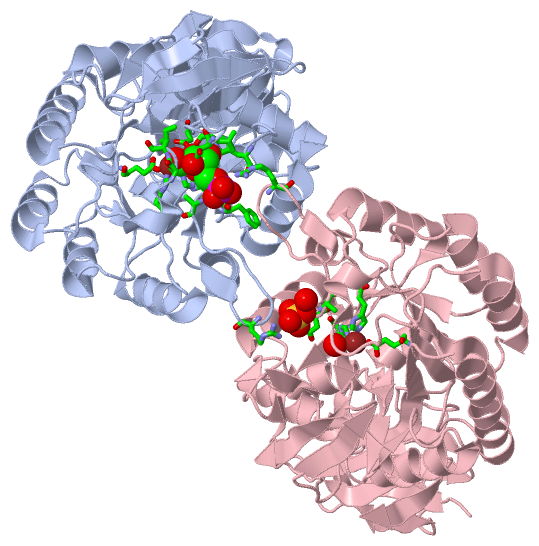
Chain A from PDB Type:PROTEIN Length:379
aligned with NAGA_VIBCH | O32445 from UniProtKB/Swiss-Prot Length:378
Alignment length:379
1
| 9 19 29 39 49 59 69 79 89 99 109 119 129 139 149 159 169 179 189 199 209 219 229 239 249 259 269 279 289 299 309 319 329 339 349 359 369
NAGA_VIBCH - -MYALTNCKIYTGNDVLVKHAVIINGDKIEAVCPIESLPSEMNVVDLNGANLSPGFIDLQLNGCGGVMFNDEITAETIDTMHKANLKSGCTSFLPTLITSSDENMRQAIAAAREYQAKYPNQSLGLHLEGPYLNVMKKGIHSVDFIRPSDDTMIDTICANSDVIAKVTLAPENNKPEHIEKLVKAGIVVSIGHTNATYSEARKSFESGITFATHLFNAMTPMVGREPGVVGAIYDTPEVYAGIIADGFHVDYANIRIAHKIKGEKLVLVTDATAPAGAEMDYFIFVGKKVYYRDGKCVDENGTLGGSALTMIEAVQNTVEHVGIALDEALRMATLYPAKAIGVDEKLGRIKKGMIANLTVFDRDFNVKATVVNGQYEQN 378
SCOP domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SCOP domains
CATH domains 3iv8A01 A:0-54,A:342-378 Urease, subunit C, domain 1 3iv8A02 A:55-277,A:278-341 Metal-dependent hydrolases 3iv8A02 A:55-277,A:278-341 Metal-dependent hydrolases 3iv8A01 A:0-54,A:342-378 CATH domains
Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
Sec.struct. author ..eeeeeeeee....ee..eeeeee..eeeeeee.hhh....eeeeeeeeeeee.eeeeee.ee..ee.....hhhhhhhhhhhhhhh.eeeeeeeee..hhhhhhhhhhhhhhhhhhh......eeee....hhhhh...........hhhhhhhhhhh...eeeeee.....hhhhhhhhhhh..eeee.....hhhhhhhhhhh...ee..............hhhhhhhhhh...eeeee......hhhhhhhhhhhhh..eeee............eee....eeeee..eee...........hhhhhhhhhhhh...hhhhhhhhhhhhhhhhhh...............eeee.....eeeeee..eeee. Sec.struct. author
SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
3iv8 A 0 AMYALTNCKIYTGNDVLVKHAVIINGDKIEAVCPIESLPSEMNVVDLNGANLSPGFIDLQLNGCGGVMFNDEITAETIDTMHKANLKSGCTSFLPTLITSSDENMRQAIAAAREYQAKYPNQSLGLHLEGPYLNVMKKGIHSVDFIRPSDDTMIDTICANSDVIAKVTLAPENNKPEHIEKLVKAGIVVSIGHTNATYSEARKSFESGITFATHLFNAMTPMVGREPGVVGAIYDTPEVYAGIIADGFHVDYANIRIAHKIKGEKLVLVTDATAPAGAEMDYFIFVGKKVYYRDGKCVDENGTLGGSALTMIEAVQNTVEHVGIALDEALRMATLYPAKAIGVDEKLGRIKKGMIANLTVFDRDFNVKATVVNGQYEQN 378
9 19 29 39 49 59 69 79 89 99 109 119 129 139 149 159 169 179 189 199 209 219 229 239 249 259 269 279 289 299 309 319 329 339 349 359 369
Chain B from PDB Type:PROTEIN Length:379
aligned with NAGA_VIBCH | O32445 from UniProtKB/Swiss-Prot Length:378
Alignment length:379
1
| 9 19 29 39 49 59 69 79 89 99 109 119 129 139 149 159 169 179 189 199 209 219 229 239 249 259 269 279 289 299 309 319 329 339 349 359 369
NAGA_VIBCH - -MYALTNCKIYTGNDVLVKHAVIINGDKIEAVCPIESLPSEMNVVDLNGANLSPGFIDLQLNGCGGVMFNDEITAETIDTMHKANLKSGCTSFLPTLITSSDENMRQAIAAAREYQAKYPNQSLGLHLEGPYLNVMKKGIHSVDFIRPSDDTMIDTICANSDVIAKVTLAPENNKPEHIEKLVKAGIVVSIGHTNATYSEARKSFESGITFATHLFNAMTPMVGREPGVVGAIYDTPEVYAGIIADGFHVDYANIRIAHKIKGEKLVLVTDATAPAGAEMDYFIFVGKKVYYRDGKCVDENGTLGGSALTMIEAVQNTVEHVGIALDEALRMATLYPAKAIGVDEKLGRIKKGMIANLTVFDRDFNVKATVVNGQYEQN 378
SCOP domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SCOP domains
CATH domains 3iv8B01 B:0-54,B:342-378 Urease, subunit C, domain 1 3iv8B02 B:55-277,B:278-341 Metal-dependent hydrolases 3iv8B02 B:55-277,B:278-341 Metal-dependent hydrolases 3iv8B01 B:0-54,B:342-378 CATH domains
Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
Sec.struct. author ..eeeeeeeee....ee..eeeeee..eeeeeee.hhh....eeeeeeeeeeee.eeeeee.ee..ee.....hhhhhhhhhhhhhh..eeeeeeeee..hhhhhhhhhhhhhhhhhhh......eeee....hhhhh...........hhhhhhhhhhh...eeeeee.....hhhhhhhhhhh..eeee.....hhhhhhhhhhh...ee..............hhhhhhhhh....eeeee......hhhhhhhhhhhhh..eeee............eee....eeeee..eeee....eee...hhhhhhhhhhhh...hhhhhhhhhhhhhhhhh................eeee.....eeeeee..eeee. Sec.struct. author
SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
3iv8 B 0 AMYALTNCKIYTGNDVLVKHAVIINGDKIEAVCPIESLPSEMNVVDLNGANLSPGFIDLQLNGCGGVMFNDEITAETIDTMHKANLKSGCTSFLPTLITSSDENMRQAIAAAREYQAKYPNQSLGLHLEGPYLNVMKKGIHSVDFIRPSDDTMIDTICANSDVIAKVTLAPENNKPEHIEKLVKAGIVVSIGHTNATYSEARKSFESGITFATHLFNAMTPMVGREPGVVGAIYDTPEVYAGIIADGFHVDYANIRIAHKIKGEKLVLVTDATAPAGAEMDYFIFVGKKVYYRDGKCVDENGTLGGSALTMIEAVQNTVEHVGIALDEALRMATLYPAKAIGVDEKLGRIKKGMIANLTVFDRDFNVKATVVNGQYEQN 378
9 19 29 39 49 59 69 79 89 99 109 119 129 139 149 159 169 179 189 199 209 219 229 239 249 259 269 279 289 299 309 319 329 339 349 359 369
Chain C from PDB Type:PROTEIN Length:379
aligned with NAGA_VIBCH | O32445 from UniProtKB/Swiss-Prot Length:378
Alignment length:379
1
| 9 19 29 39 49 59 69 79 89 99 109 119 129 139 149 159 169 179 189 199 209 219 229 239 249 259 269 279 289 299 309 319 329 339 349 359 369
NAGA_VIBCH - -MYALTNCKIYTGNDVLVKHAVIINGDKIEAVCPIESLPSEMNVVDLNGANLSPGFIDLQLNGCGGVMFNDEITAETIDTMHKANLKSGCTSFLPTLITSSDENMRQAIAAAREYQAKYPNQSLGLHLEGPYLNVMKKGIHSVDFIRPSDDTMIDTICANSDVIAKVTLAPENNKPEHIEKLVKAGIVVSIGHTNATYSEARKSFESGITFATHLFNAMTPMVGREPGVVGAIYDTPEVYAGIIADGFHVDYANIRIAHKIKGEKLVLVTDATAPAGAEMDYFIFVGKKVYYRDGKCVDENGTLGGSALTMIEAVQNTVEHVGIALDEALRMATLYPAKAIGVDEKLGRIKKGMIANLTVFDRDFNVKATVVNGQYEQN 378
SCOP domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SCOP domains
CATH domains 3iv8C01 C:0-54,C:342-378 Urease, subunit C, domain 1 3iv8C02 C:55-277,C:278-341 Metal-dependent hydrolases 3iv8C02 C:55-277,C:278-341 Metal-dependent hydrolases 3iv8C01 C:0-54,C:342-378 CATH domains
Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
Sec.struct. author ..eeeeeeeee....eeeeeeeeee..eeeeeee.hhh....eeee....eeee.eeeeee.ee..ee.....hhhhhhhhhhhhh...eeeeeeeee..hhhhhhhhhhhhhhhhhhh......eeee....hhhhh...........hhhhhhhhhhh...eeeeee.....hhhhhhhhhhh..eeee.....hhhhhhhhhhhh..ee..............hhhhhhhhh....eeeee......hhhhhhhhhhhhh..eeee............eeee..eeeeee..eeee....eee...hhhhhhhhhhhh...hhhhhhhhhhhhhhhhhh...............eeee.....eeeeee..eeee. Sec.struct. author
SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
3iv8 C 0 AMYALTNCKIYTGNDVLVKHAVIINGDKIEAVCPIESLPSEMNVVDLNGANLSPGFIDLQLNGCGGVMFNDEITAETIDTMHKANLKSGCTSFLPTLITSSDENMRQAIAAAREYQAKYPNQSLGLHLEGPYLNVMKKGIHSVDFIRPSDDTMIDTICANSDVIAKVTLAPENNKPEHIEKLVKAGIVVSIGHTNATYSEARKSFESGITFATHLFNAMTPMVGREPGVVGAIYDTPEVYAGIIADGFHVDYANIRIAHKIKGEKLVLVTDATAPAGAEMDYFIFVGKKVYYRDGKCVDENGTLGGSALTMIEAVQNTVEHVGIALDEALRMATLYPAKAIGVDEKLGRIKKGMIANLTVFDRDFNVKATVVNGQYEQN 378
9 19 29 39 49 59 69 79 89 99 109 119 129 139 149 159 169 179 189 199 209 219 229 239 249 259 269 279 289 299 309 319 329 339 349 359 369
Chain D from PDB Type:PROTEIN Length:356
aligned with NAGA_VIBCH | O32445 from UniProtKB/Swiss-Prot Length:378
Alignment length:379
1
| 9 19 29 39 49 59 69 79 89 99 109 119 129 139 149 159 169 179 189 199 209 219 229 239 249 259 269 279 289 299 309 319 329 339 349 359 369
NAGA_VIBCH - -MYALTNCKIYTGNDVLVKHAVIINGDKIEAVCPIESLPSEMNVVDLNGANLSPGFIDLQLNGCGGVMFNDEITAETIDTMHKANLKSGCTSFLPTLITSSDENMRQAIAAAREYQAKYPNQSLGLHLEGPYLNVMKKGIHSVDFIRPSDDTMIDTICANSDVIAKVTLAPENNKPEHIEKLVKAGIVVSIGHTNATYSEARKSFESGITFATHLFNAMTPMVGREPGVVGAIYDTPEVYAGIIADGFHVDYANIRIAHKIKGEKLVLVTDATAPAGAEMDYFIFVGKKVYYRDGKCVDENGTLGGSALTMIEAVQNTVEHVGIALDEALRMATLYPAKAIGVDEKLGRIKKGMIANLTVFDRDFNVKATVVNGQYEQN 378
SCOP domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SCOP domains
CATH domains 3iv8D01 D:0-54,D:343-378 Urease, subunit C, domain 1 3iv8D02 D:55-342 Metal-dependent hydrolases 3iv8D01 D:0-54,D:343-378 CATH domains
Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
Sec.struct. author ..eeee..eee....ee..eeeeee..eeeeeee.hhh....eeee....eeee.eeeeee.ee..ee.....hhhhhhhhhhhhhh..eeeeeeeee..hhhhhhhhhhhhhhhhhhh......eeee....hhhhh...........hhhhhhhhhhh...eeeeee.....hhhhhhhhhhhh.eeee.....hhhhhhhhhhhh..ee..............hhhhhhhhh....eeeee......hhhhhhhhhhhhh..eeee...........-----------------------......hhhhhhhhhhhh...hhhhhhhhhhhhhhhhhh...............eeee.....eeeeee..eeee. Sec.struct. author
SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
3iv8 D 0 AMYALTNCKIYTGNDVLVKHAVIINGDKIEAVCPIESLPSEMNVVDLNGANLSPGFIDLQLNGCGGVMFNDEITAETIDTMHKANLKSGCTSFLPTLITSSDENMRQAIAAAREYQAKYPNQSLGLHLEGPYLNVMKKGIHSVDFIRPSDDTMIDTICANSDVIAKVTLAPENNKPEHIEKLVKAGIVVSIGHTNATYSEARKSFESGITFATHLFNAMTPMVGREPGVVGAIYDTPEVYAGIIADGFHVDYANIRIAHKIKGEKLVLVTDATAPAGAEM-----------------------LGGSALTMIEAVQNTVEHVGIALDEALRMATLYPAKAIGVDEKLGRIKKGMIANLTVFDRDFNVKATVVNGQYEQN 378
9 19 29 39 49 59 69 79 89 99 109 119 129 139 149 159 169 179 189 199 209 219 229 239 249 259 269 279 - - | 309 319 329 339 349 359 369
279 303
| Legend: |
|
→ Mismatch |
(orange background) |
| |
- |
→ Gap |
(green background, '-', border residues have a numbering label) |
| |
|
→ Modified Residue |
(blue background, lower-case, 'x' indicates undefined single-letter code, labelled with number + name) |
| |
x |
→ Chemical Group |
(purple background, 'x', labelled with number + name, e.g. ACE or NH2) |
| |
extra numbering lines below/above indicate numbering irregularities and modified residue names etc., number ends below/above '|' |
 Description
Description