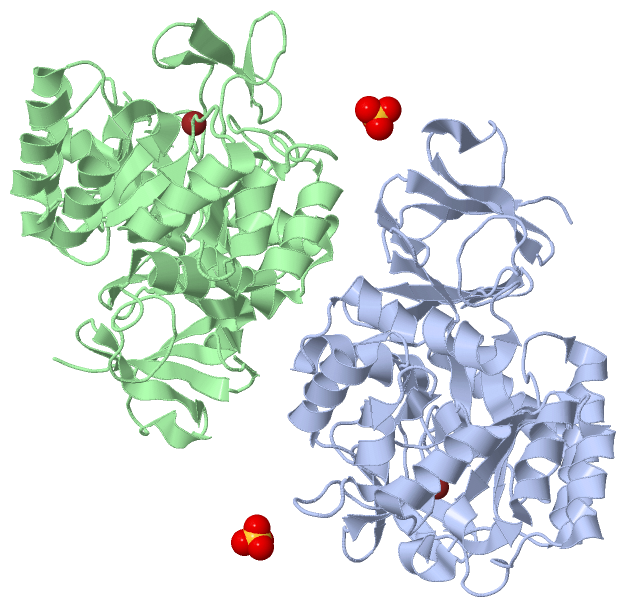
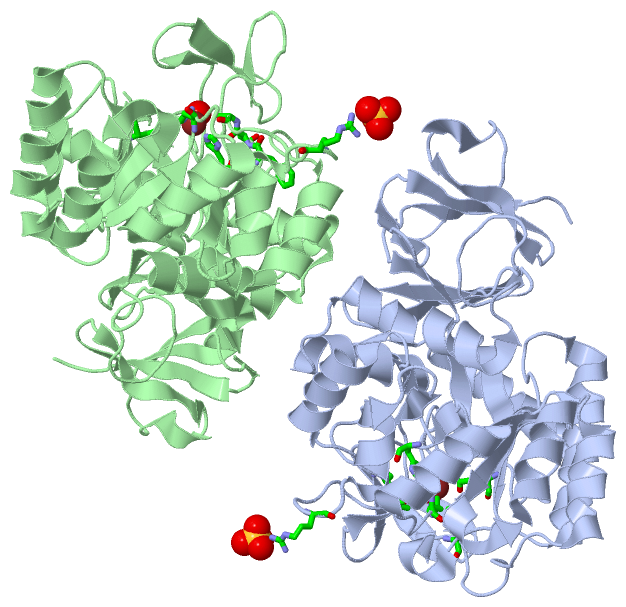
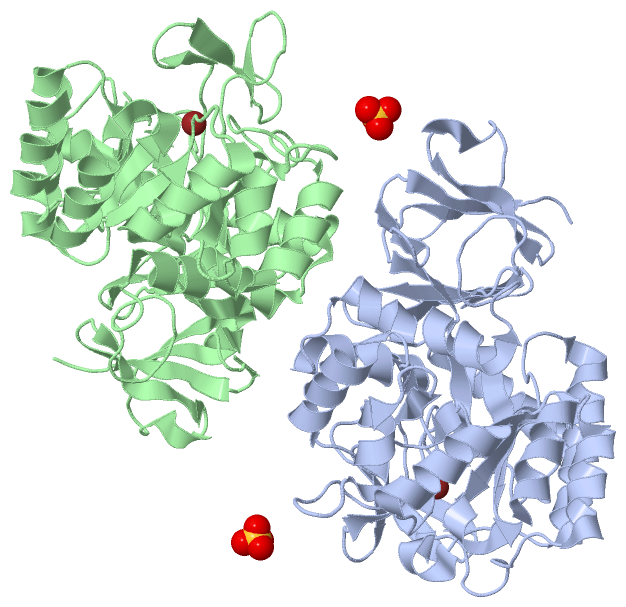
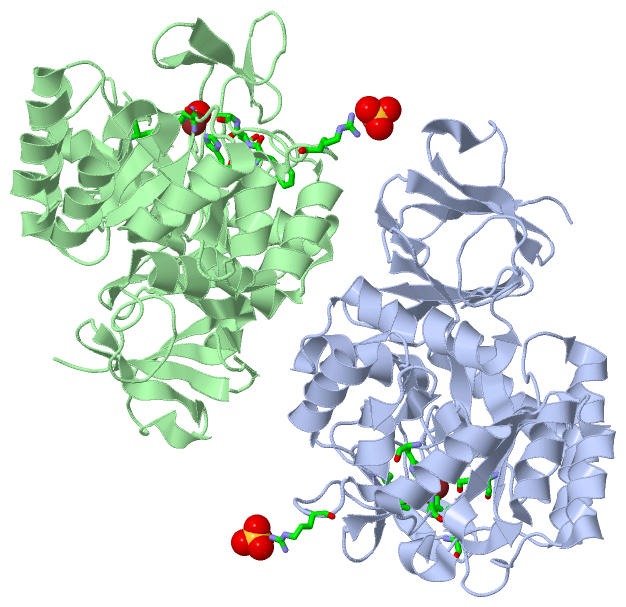
Chain A from PDB Type:PROTEIN Length:379
aligned with NAGA_VIBCH | O32445 from UniProtKB/Swiss-Prot Length:378
Alignment length:379
1
| 8 18 28 38 48 58 68 78 88 98 108 118 128 138 148 158 168 178 188 198 208 218 228 238 248 258 268 278 288 298 308 318 328 338 348 358 368
NAGA_VIBCH - --MYALTNCKIYTGNDVLVKHAVIINGDKIEAVCPIESLPSEMNVVDLNGANLSPGFIDLQLNGCGGVMFNDEITAETIDTMHKANLKSGCTSFLPTLITSSDENMRQAIAAAREYQAKYPNQSLGLHLEGPYLNVMKKGIHSVDFIRPSDDTMIDTICANSDVIAKVTLAPENNKPEHIEKLVKAGIVVSIGHTNATYSEARKSFESGITFATHLFNAMTPMVGREPGVVGAIYDTPEVYAGIIADGFHVDYANIRIAHKIKGEKLVLVTDATAPAGAEMDYFIFVGKKVYYRDGKCVDENGTLGGSALTMIEAVQNTVEHVGIALDEALRMATLYPAKAIGVDEKLGRIKKGMIANLTVFDRDFNVKATVVNGQYEQ 377
SCOP domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SCOP domains
CATH domains 3egjA01 A:-1-54,A:342-377 Urease, subunit C, domain 1 3egjA02 A:55-277,A:278-341 Metal-dependent hydrolases 3egjA02 A:55-277,A:278-341 Metal-dependent hydrolases 3egjA01 A:-1-54,A:342-377 CATH domains
Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
Sec.struct. author ...eeee..eee....ee..eeeeee..eeeeeee.hhh.....eee....eeee.eeeeee............hhhhhhhhhhhhhh..eeeeeeeee..hhhhhhhhhhhhhhhhhhh......eeee....hhhhh...........hhhhhhhhhhh...eeeeeehhhhhhhhhhhhhhhh..eeee.....hhhhhhhhhhhh..ee..............hhhhhhhhh....eeee.......hhhhhhhhhhhhh..eee.............eeee..eeeeee..eeee...ee.....hhhhhhhhhhhh...hhhhhhhh.hhhhhhhhh...............eeee.....eeeeee..eee. Sec.struct. author
SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
3egj A -1 NAMYALTNCKIYTGNDVLVKHAVIINGDKIEAVCPIESLPSEMNVVDLNGANLSPGFIDLQLNGCGGVMFNDEITAETIDTMHKANLKSGCTSFLPTLITSSDENMRQAIAAAREYQAKYPNQSLGLHLEGPYLNVMKKGIHSVDFIRPSDDTMIDTICANSDVIAKVTLAPENNKPEHIEKLVKAGIVVSIGHTNATYSEARKSFESGITFATHLFNAMTPMVGREPGVVGAIYDTPEVYAGIIADGFHVDYANIRIAHKIKGEKLVLVTDATAPAGAEMDYFIFVGKKVYYRDGKCVDENGTLGGSALTMIEAVQNTVEHVGIALDEALRMATLYPAKAIGVDEKLGRIKKGMIANLTVFDRDFNVKATVVNGQYEQ 377
8 18 28 38 48 58 68 78 88 98 108 118 128 138 148 158 168 178 188 198 208 218 228 238 248 258 268 278 288 298 308 318 328 338 348 358 368
Chain B from PDB Type:PROTEIN Length:361
aligned with NAGA_VIBCH | O32445 from UniProtKB/Swiss-Prot Length:378
Alignment length:379
1
| 8 18 28 38 48 58 68 78 88 98 108 118 128 138 148 158 168 178 188 198 208 218 228 238 248 258 268 278 288 298 308 318 328 338 348 358 368
NAGA_VIBCH - --MYALTNCKIYTGNDVLVKHAVIINGDKIEAVCPIESLPSEMNVVDLNGANLSPGFIDLQLNGCGGVMFNDEITAETIDTMHKANLKSGCTSFLPTLITSSDENMRQAIAAAREYQAKYPNQSLGLHLEGPYLNVMKKGIHSVDFIRPSDDTMIDTICANSDVIAKVTLAPENNKPEHIEKLVKAGIVVSIGHTNATYSEARKSFESGITFATHLFNAMTPMVGREPGVVGAIYDTPEVYAGIIADGFHVDYANIRIAHKIKGEKLVLVTDATAPAGAEMDYFIFVGKKVYYRDGKCVDENGTLGGSALTMIEAVQNTVEHVGIALDEALRMATLYPAKAIGVDEKLGRIKKGMIANLTVFDRDFNVKATVVNGQYEQ 377
SCOP domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SCOP domains
CATH domains 3egjB01 B:-1-54,B:342-377 Urease, subunit C, domain 1 3egjB02 B:55-277,B:278-341 Metal-dependent hydrolases 3egjB02 B:55-277,B:278-341 Metal-dependent hydrolases 3egjB01 B:-1-54,B:342-377 CATH domains
Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
Sec.struct. author ...eeeeeeeee....ee..eeeeee..eeeeeee.hhh.....eeeeeeeeeee.eeeeee.ee..ee.....hhhhhhhhhhhhh...eeeeeeeee..hhhhhhhhhhhhhhhhhhh......eeee..------------------hhhhhhhhhhh...eeeeeehhhhhhhhhhhhhhhhh.eeee.....hhhhhhhhhhhh..ee..............hhhhhhhhhh...eeeee......hhhhhhhhhhhhh..eeee............eee....eeee....ee...........hhhhhhhhhhhhhh.hhhhhhhhhhhhhhhhh................eeee.....eeeeee..ee.. Sec.struct. author
SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
3egj B -1 NAMYALTNCKIYTGNDVLVKHAVIINGDKIEAVCPIESLPSEMNVVDLNGANLSPGFIDLQLNGCGGVMFNDEITAETIDTMHKANLKSGCTSFLPTLITSSDENMRQAIAAAREYQAKYPNQSLGLHLEGP------------------DDTMIDTICANSDVIAKVTLAPENNKPEHIEKLVKAGIVVSIGHTNATYSEARKSFESGITFATHLFNAMTPMVGREPGVVGAIYDTPEVYAGIIADGFHVDYANIRIAHKIKGEKLVLVTDATAPAGAEMDYFIFVGKKVYYRDGKCVDENGTLGGSALTMIEAVQNTVEHVGIALDEALRMATLYPAKAIGVDEKLGRIKKGMIANLTVFDRDFNVKATVVNGQYEQ 377
8 18 28 38 48 58 68 78 88 98 108 118 128 | - -| 158 168 178 188 198 208 218 228 238 248 258 268 278 288 298 308 318 328 338 348 358 368
130 149
| Legend: |
|
→ Mismatch |
(orange background) |
| |
- |
→ Gap |
(green background, '-', border residues have a numbering label) |
| |
|
→ Modified Residue |
(blue background, lower-case, 'x' indicates undefined single-letter code, labelled with number + name) |
| |
x |
→ Chemical Group |
(purple background, 'x', labelled with number + name, e.g. ACE or NH2) |
| |
extra numbering lines below/above indicate numbering irregularities and modified residue names etc., number ends below/above '|' |
 Description
Description