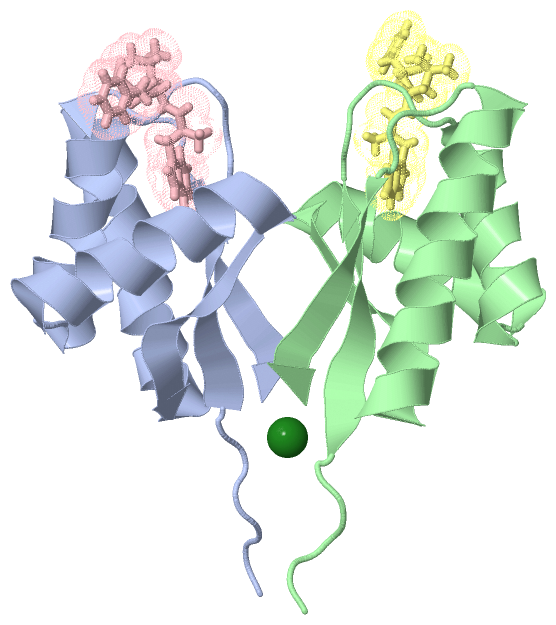
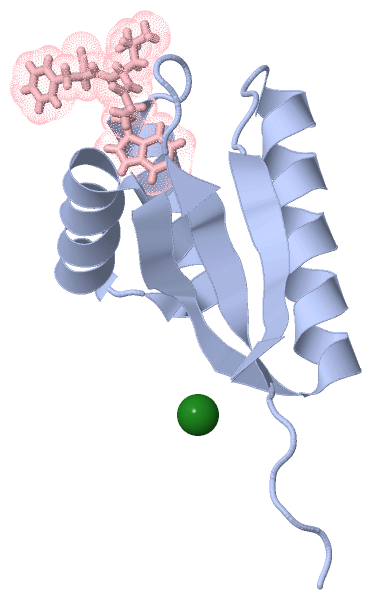
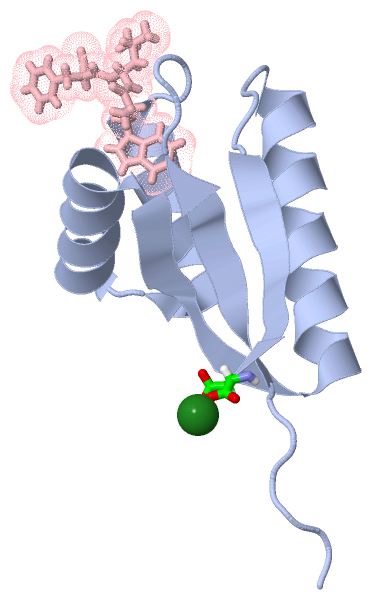
Chain A from PDB Type:PROTEIN Length:85
aligned with CLPS_CAUCR | Q9A5I0 from UniProtKB/Swiss-Prot Length:119
Alignment length:85
44 54 64 74 84 94 104 114
CLPS_CAUCR 35 TQKPSLYRVLILNDDYTPMEFVVYVLERFFNKSREDATRIMLHVHQNGVGVCGVYTYEVAETKVAQVIDSARRHQHPLQCTMEKD 119
SCOP domains d3gq1a_ A: automated matches SCOP domains
CATH domains ------------------------------------------------------------------------------------- CATH domains
Pfam domains ------------------------------------------------------------------------------------- Pfam domains
Sec.struct. author ......eeeeee.....hhhhhhhhhhhhhh.hhhhhhhhhhhhhhhheeeeeeehhhhhhhhhhhhhhhhhhh....eeeeee. Sec.struct. author
SAPs(SNPs) ------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ------------------------------------------------------------------------------------- PROSITE
Transcript ------------------------------------------------------------------------------------- Transcript
3gq1 A 35 TQKPSLYRVLILNDDYTPMEFVVYVLERFFNKSREDATRIMLHVHQNGVGVCGVYTYEVAETKVAQVIDSARRHQHPLQCTMEKD 119
44 54 64 74 84 94 104 114
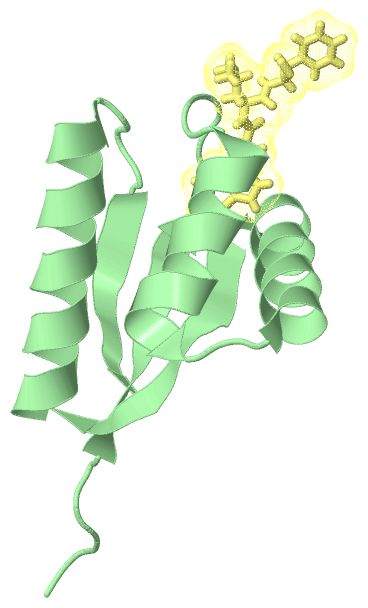
Chain B from PDB Type:PROTEIN Length:85
aligned with CLPS_CAUCR | Q9A5I0 from UniProtKB/Swiss-Prot Length:119
Alignment length:85
44 54 64 74 84 94 104 114
CLPS_CAUCR 35 TQKPSLYRVLILNDDYTPMEFVVYVLERFFNKSREDATRIMLHVHQNGVGVCGVYTYEVAETKVAQVIDSARRHQHPLQCTMEKD 119
SCOP domains d3gq1b_ B: automated matches SCOP domains
CATH domains ------------------------------------------------------------------------------------- CATH domains
Pfam domains ------------------------------------------------------------------------------------- Pfam domains
Sec.struct. author .....eeeeeee.....hhhhhhhhhhhhh..hhhhhhhhhhhhhhhheeeeeeeehhhhhhhhhhhhhhhhhh....eeeeee. Sec.struct. author
SAPs(SNPs) ------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ------------------------------------------------------------------------------------- PROSITE
Transcript ------------------------------------------------------------------------------------- Transcript
3gq1 B 35 TQKPSLYRVLILNDDYTPMEFVVYVLERFFNKSREDATRIMLHVHQNGVGVCGVYTYEVAETKVAQVIDSARRHQHPLQCTMEKD 119
44 54 64 74 84 94 104 114
Chain C from PDB Type:PROTEIN Length:3
SCOP domains --- SCOP domains
CATH domains --- CATH domains
Pfam domains --- Pfam domains
Sec.struct. author ... Sec.struct. author
SAPs(SNPs) --- SAPs(SNPs)
PROSITE --- PROSITE
Transcript --- Transcript
3gq1 C 1 WLF 3
Chain D from PDB Type:PROTEIN Length:3
SCOP domains --- SCOP domains
CATH domains --- CATH domains
Pfam domains --- Pfam domains
Sec.struct. author ... Sec.struct. author
SAPs(SNPs) --- SAPs(SNPs)
PROSITE --- PROSITE
Transcript --- Transcript
3gq1 D 1 WLF 3
| Legend: |
|
→ Mismatch |
(orange background) |
| |
- |
→ Gap |
(green background, '-', border residues have a numbering label) |
| |
|
→ Modified Residue |
(blue background, lower-case, 'x' indicates undefined single-letter code, labelled with number + name) |
| |
x |
→ Chemical Group |
(purple background, 'x', labelled with number + name, e.g. ACE or NH2) |
| |
extra numbering lines below/above indicate numbering irregularities and modified residue names etc., number ends below/above '|' |
 Description
Description