|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (0, 0)| (no "Ligand,Modified Residues,Ions" information available for 2JRS) |
Sites (0, 0)| (no "Site" information available for 2JRS) |
SS Bonds (0, 0)| (no "SS Bond" information available for 2JRS) |
Cis Peptide Bonds (0, 0)| (no "Cis Peptide Bond" information available for 2JRS) |
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 2JRS) |
PROSITE Motifs (1, 1)
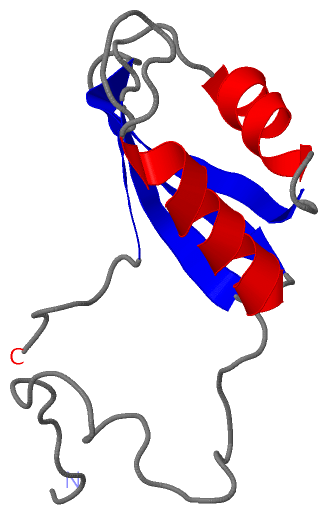
NMR Structure (1, 1)
|
||||||||||||||||||||||||
Exons (4, 4)
Sequences/Alignments
NMR StructureChain A from PDB Type:PROTEIN Length:108 aligned with RBM39_HUMAN | Q14498 from UniProtKB/Swiss-Prot Length:530 Alignment length:113 228 238 248 258 268 278 288 298 308 318 328 RBM39_HUMAN 219 LGVPIIVQASQAEKNRAAAMANNLQKGSAGPMRLYVGSLHFNITEDMLRGIFEPFGRIESIQLMMDSETGRSKGYGFITFSDSECAKKALEQLNGFELAGRPMKVGHVTERTD 331 SCOP domains ----------------------------------------------------------------------------------------------------------------- SCOP domains CATH domains -----------------------------2jrsA01 A:25-103 [code=3.30.70.330, no name defined] ----- CATH domains Pfam domains ---------------------------------RRM_1-2jrsA01 A:29-99 --------- Pfam domains SAPs(SNPs) ----------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE RRM PDB: - -------------------RRM PDB: A:27-105 UniProt: 250-328 --- PROSITE Transcript 1 Exon 1.11c Exon 1.12b PDB: A:7-52 UniProt: 230-275 Exon 1.13a Exon 1.14a PDB: A:75-108 Transcript 1 2jrs A 1 MG-----HHHHHHSHMAAAMANNLQKGSAGPMRLYVGSLHFNITEDMLRGIFEPFGRIESIQLMMDSETGRSKGYGFITFSDSECAKKALEQLNGFELAGRPMKVGHVTERTD 108 | | 5 15 25 35 45 55 65 75 85 95 105 2 3
|
||||||||||||||||||||
SCOP Domains (0, 0)| (no "SCOP Domain" information available for 2JRS) |
CATH Domains (1, 1)
NMR Structure

|
Pfam Domains (1, 1)
NMR Structure
|
Gene Ontology (14, 14)|
NMR Structure(hide GO term definitions) Chain A (RBM39_HUMAN | Q14498)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|