|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
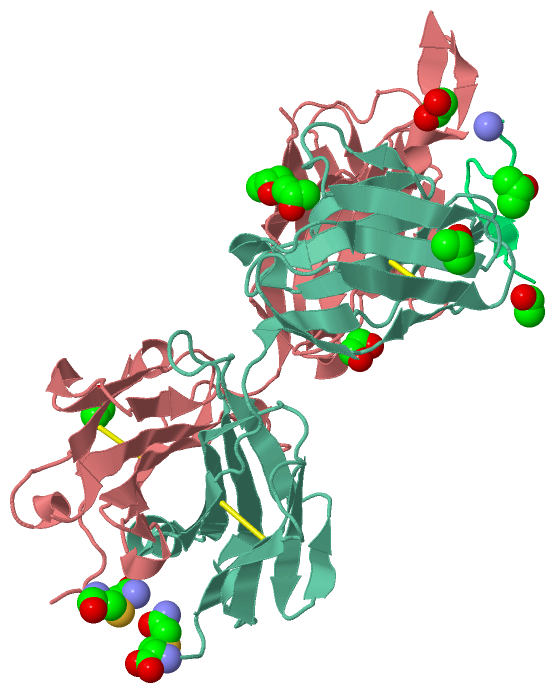
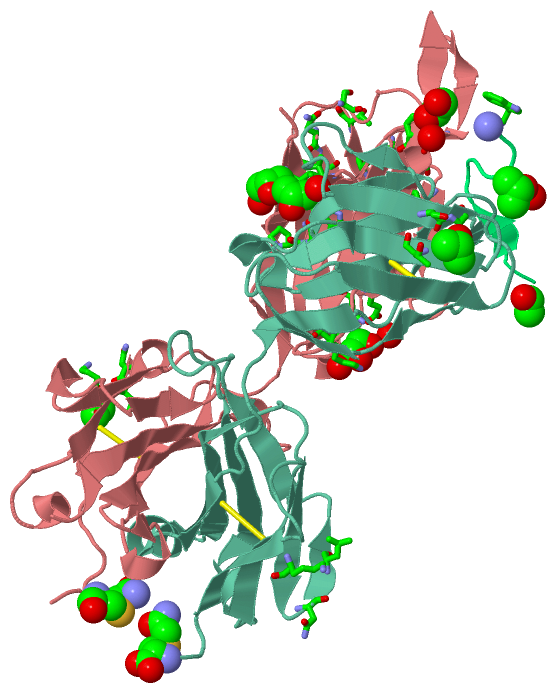
Ligands, Modified Residues, Ions (5, 12)| Asymmetric/Biological Unit (5, 12) |
Sites (8, 8)
Asymmetric Unit (8, 8)
|
SS Bonds (4, 4)
Asymmetric/Biological Unit
|
||||||||||||||||||||
Cis Peptide Bonds (5, 5)
Asymmetric/Biological Unit
|
||||||||||||||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 1TJH) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 1TJH) |
Exons (0, 0)| (no "Exon" information available for 1TJH) |
Sequences/Alignments
Asymmetric/Biological Unit
Chain H from PDB Type:PROTEIN Length:237
SCOP domains d1tjhh1 H:1-113 Immunoglobulin heavy chain variable domain, VH d1tjhh2 H:114-216 Immunoglobulin heavy chain gamma constant domain 1, CH1-gamma -- SCOP domains
CATH domains 1tjhH01 H:1-113 Immunoglobulins 1tjhH02 H:114-213 Immunoglobulins ----- CATH domains
Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
1tjh H 1 RITLKESGPPLVKPTQTLTLTCSFSGFSLSDFGVGVGWIRQPPGKALEWLAIIYSDDDKRYSPSLNTRLTITKDTSKNQVVLVMTRVSPVDTATYFCAHRRGPTTLFGVPIARGPVNAMDVWGQGITVTISSTSTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKScDK 218
10 20 30 || 38 48 58 68 78 ||| 85 95 |100E|||||||101 111 121 131 141 151 161 171 181 191 201 211 |
35A| 82A|| 100A|||||100J|||| 216-YCM
35B 82B| 100B|||||100K|||
82C 100C|||||100L||
100D|||||100M|
100E|||| 100N
100F|||
100G||
100H|
100I
Chain L from PDB Type:PROTEIN Length:214
SCOP domains d1tjhl1 L:1-107 Immunoglobulin light chain kappa variable domain, VL-kappa d1tjhl2 L:108-214 Immunoglobulin light chain kappa constant domain, CL-kappa SCOP domains
CATH domains 1tjhL01 L:1-107 Immunoglobulins 1tjhL02 L:108-211 Immunoglobulins --- CATH domains
Pfam domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
1tjh L 1 ALQLTQSPSSLSASVGDRITITCRASQGVTSALAWYRQKPGSPPQLLIYDASSLESGVPSRFSGSGSGTEFTLTISTLRPEDFATYYCQQLHFYPHTFGGGTRVDVRRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEc 214
10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 |
214-YCM
Chain P from PDB Type:PROTEIN Length:13 aligned with ENV_HV1Z6 | P04580 from UniProtKB/Swiss-Prot Length:855 Alignment length:13 667 ENV_HV1Z6 658 ELLELDKWASLWN 670 SCOP domains ------------- SCOP domains CATH domains ------------- CATH domains Pfam domains -GP41-1tjhP0- Pfam domains SAPs(SNPs) ------------- SAPs(SNPs) PROSITE ------------- PROSITE Transcript ------------- Transcript 1tjh P 659 xLLELDKWASLWx 671 | 668 | | 671-NH2 659-ACE
|
||||||||||||||||||||
SCOP Domains (4, 4)
Asymmetric/Biological Unit
 |
CATH Domains (1, 4)
Asymmetric/Biological Unit
|
Pfam Domains (1, 1)
Asymmetric/Biological Unit
|
Gene Ontology (21, 21)|
Asymmetric/Biological Unit(hide GO term definitions) Chain P (ENV_HV1Z6 | P04580)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|