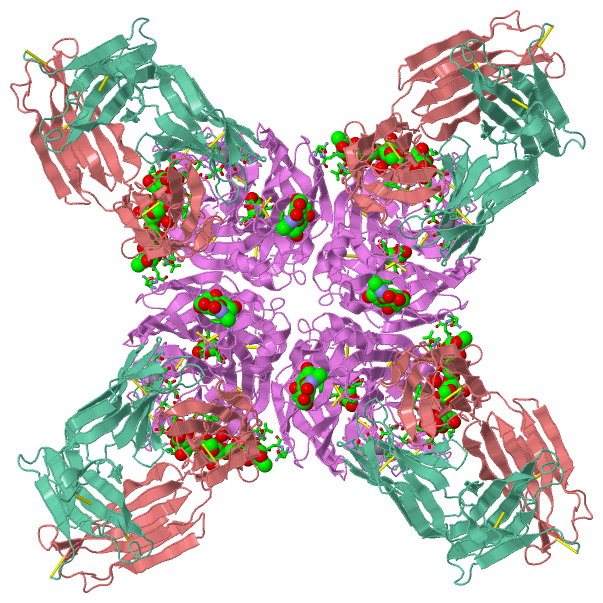
|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
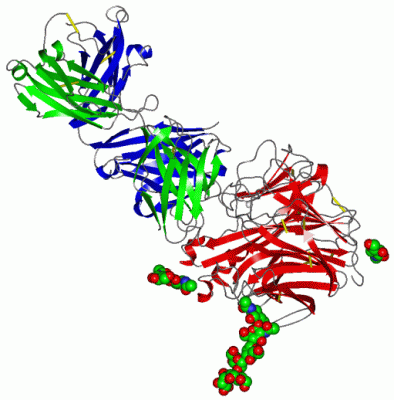
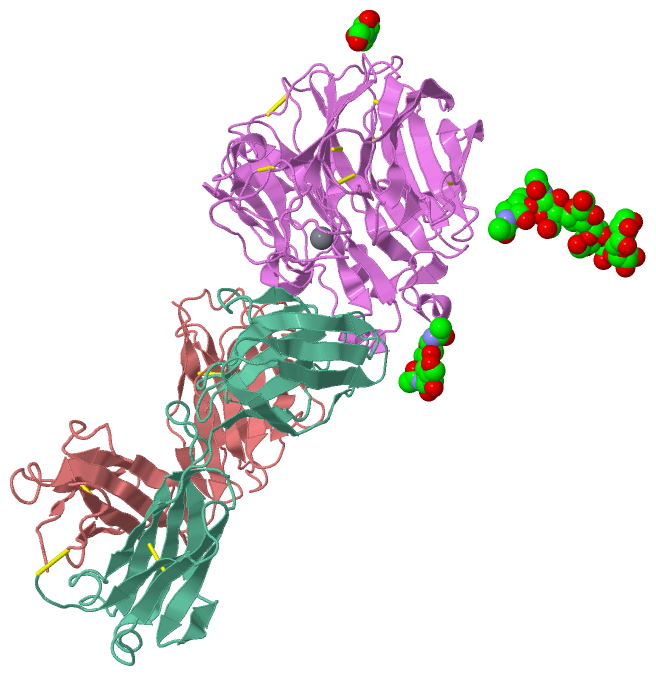
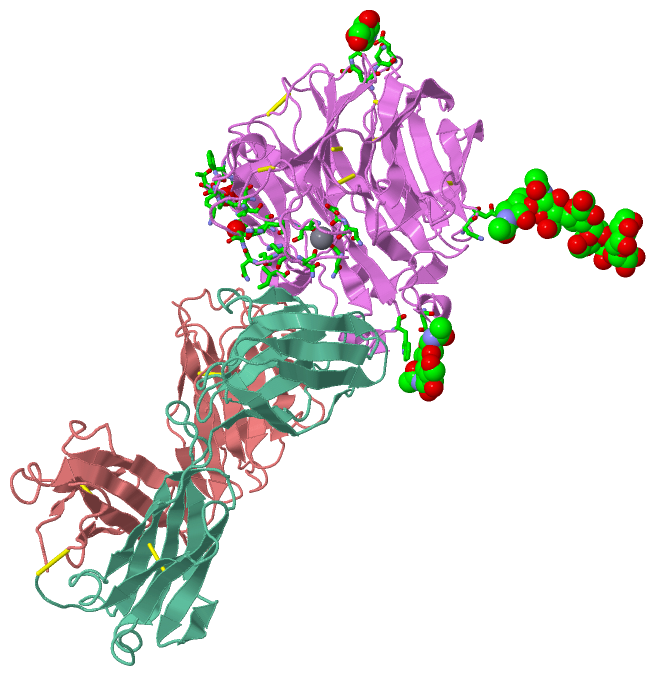
Ligands, Modified Residues, Ions (4, 10)| Asymmetric Unit (4, 10) Biological Unit 1 (3, 36) |
Sites (10, 10)
Asymmetric Unit (10, 10)
|
SS Bonds (14, 14)
Asymmetric Unit
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Cis Peptide Bonds (8, 8)
Asymmetric Unit
|
||||||||||||||||||||||||||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 1NCD) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 1NCD) |
Exons (0, 0)| (no "Exon" information available for 1NCD) |
Sequences/Alignments
Asymmetric Unit
Chain H from PDB Type:PROTEIN Length:221
SCOP domains d1ncdh1 H:1-113 Immunoglobulin heavy chain variable domain, VH d1ncdh2 H:114-227 Immunoglobulin heavy chain gamma constant domain 1, CH1-gamma SCOP domains
CATH domains 1ncdH01 H:1-113 Immunoglobulins 1ncdH02 H:114-218 Immunoglobulins --------- CATH domains
Pfam domains ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
1ncd H 1 QIQLVQSGPELKKPGETVKISCKASGYTFTNYGMNWVKQAPGKGLEWMGWINTNTGEPTYGEEFKGRFAFSLETSASTANLQINNLKNEDKATFFCARGEDNFGSLSDYWGQGTTLTVSSAKTTAPSVYPLAPVCGDTTGSSVTLGCLVKGYFPEPVTLTWNSGSLSSGVHTFPAVLQSDLYTLSSSVTVTSSTWPSQSITCNVAHPASSTKVDKKIEPRG 227
10 20 30 40 50 | 59 69 79 ||| 86 96 |||103 113 123 |135 145 156|| 171 183 193 || ||205|| 216 226
52A 82A|| 100A|| 130| 154||| 169| 180| 196| || 206|
82B| 100B| 133 156|| 171 183 198 || 208
82C 100C 157| 200|
162 202
Chain L from PDB Type:PROTEIN Length:214
SCOP domains d1ncdl1 L:1-108 Immunoglobulin light chain kappa variable domain, VL-kappa d1ncdl2 L:109-214 Immunoglobulin light chain kappa constant domain, CL-kappa SCOP domains
CATH domains 1ncdL01 L:1-108 Immunoglobulins 1ncdL02 L:109-211 Immunoglobulins --- CATH domains
Pfam domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
1ncd L 1 DIVMTQSPKFMSTSVGDRVTITCKASQDVSTAVVWYQQKPGQSPKLLIYWASTRHIGVPDRFAGSGSGTDYTLTISSVQAEDLALYYCQQHYSPPWTFGGGTKLEIKRADAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPKDINVKWKIDGSERQNGVLNSWTDQDSKDSTYSMSSTLTLTKDEYERHNSYTCEATHKTSTSPIVKSFNRNEC 214
10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210
Chain N from PDB Type:PROTEIN Length:389 aligned with NRAM_I84A1 | P05803 from UniProtKB/Swiss-Prot Length:470 Alignment length:389 91 101 111 121 131 141 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 301 311 321 331 341 351 361 371 381 391 401 411 421 431 441 451 461 NRAM_I84A1 82 SREFNNLTKGLCTINSWHIYGKDNAVRIGEDSDVLVTREPYVSCDPDECRFYALSQGTTIRGKHSNGTIHDRSQYRDLISWPLSSPPTVYNSRVECIGWSSTSCHDGRARMSICISGPNNNASAVIWYNRRPVTEINTWARNILRTQESECVCQNGVCPVVFTDGSATGPAETRIYYFKEGKILKWEPLTGTAKHIEECSCYGEQAGVTCTCRDNWQGSNRPVIQIDPVAMTHTSQYICSPVLTDNPRPNDPTVGKCNDPYPGNNNNGVKGFSYLDGGNTWLGRTISIASRSGYEMLKVPNALTDDRSKPTQGQTIVLNTDWSGYSGSFMDYWAEGECYRACFYVELIRGRPKEDKVWWTSNSIVSMCSSTEFLGQWNWPDGAKIEYFL 470 SCOP domains d1ncdn_ N: Influenza neuraminidase SCOP domains CATH domains 1ncdN00 N:81-468 [code=2.120.10.10, no name defined] CATH domains Pfam domains -Neur-1ncdN01 N:82-466 -- Pfam domains SAPs(SNPs) ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1ncd N 81 IREFNNLTKGLCTINSWHIYGKDNAVRIGEDSDVLVTREPYVSCDPDECRFYALSQGTTIRGKHSNGTIHDRSQYRDLISWPLSSPPTVYNSRVECIGWSSTSCHDGRARMSICISGPNNNASAVIWYNRRPVTEINTWARNILRTQESECVCQNGVCPVVFTDGSATGPAETRIYYFKEGKILKWEPLTGTAKHIEECSCYGEQAGVTCTCRDNWQGSNRPVIQIDPVAMTHTSQYICSPVLTDNPRPNDPTVGKCNDPYPGNNNNGVKGFSYLDGGNTWLGRTISIASRSGYEMLKVPNALTDDRSKPTQGQTIVLNTDWSGYSGSFMDYWAEGECYRACFYVELIRGRPKEDKVWWTSNSIVSMCSSTEFLGQWNWPDGAKIEYFL 468 90 100 110 120 130 140 150 160 169A 179 189 199 209 219 229 239 249 259 269 279 289 299 309 319 329 || 340 350 360 370 380 390 || 401 411 || 419 429 439 449 459 169A 333| 392| 412A| 335 394 412B
|
||||||||||||||||||||
SCOP Domains (5, 5)
Asymmetric Unit
 |
CATH Domains (2, 5)
Asymmetric Unit
|
Pfam Domains (1, 1)
Asymmetric Unit
|
Gene Ontology (42, 44)|
Asymmetric Unit(hide GO term definitions) Chain N (NRAM_I84A1 | P05803)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|