|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
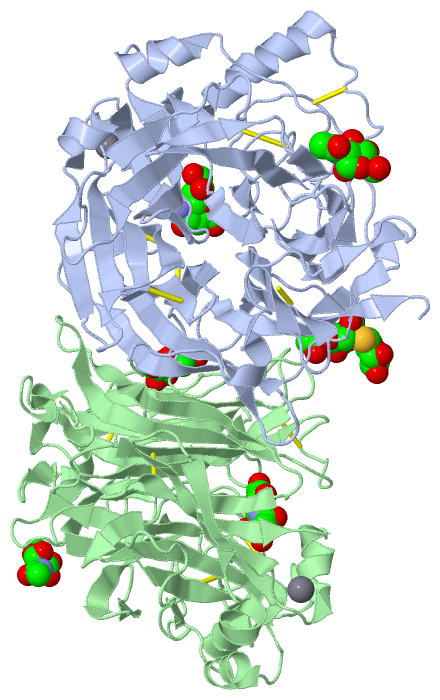
Ligands, Modified Residues, Ions (5, 9)| Asymmetric/Biological Unit (5, 9) |
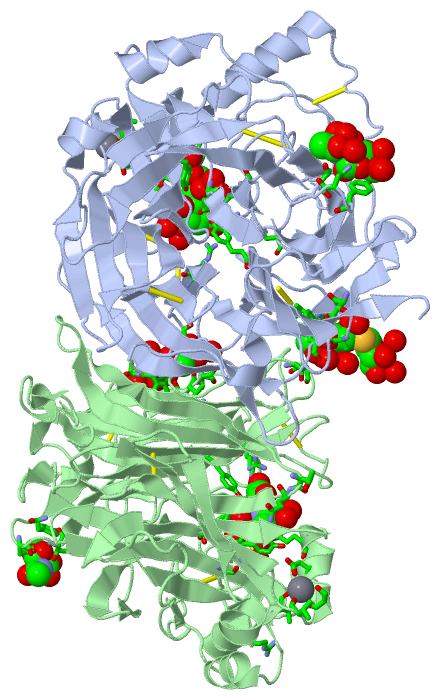
Sites (9, 9)
Asymmetric Unit (9, 9)
|
SS Bonds (11, 11)
Asymmetric/Biological Unit
|
||||||||||||||||||||||||||||||||||||||||||||||||
Cis Peptide Bonds (2, 2)
Asymmetric/Biological Unit
|
||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 1USR) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 1USR) |
Exons (0, 0)| (no "Exon" information available for 1USR) |
Sequences/Alignments
Asymmetric/Biological UnitChain A from PDB Type:PROTEIN Length:448 aligned with HN_NDVB | P32884 from UniProtKB/Swiss-Prot Length:577 Alignment length:448 133 143 153 163 173 183 193 203 213 223 233 243 253 263 273 283 293 303 313 323 333 343 353 363 373 383 393 403 413 423 433 443 453 463 473 483 493 503 513 523 533 543 553 563 HN_NDVB 124 GAPIHDPDFIGGIGKELIVDDASDVTSFYPSAFQEHLNFIPAPTTGSGCTRIPSFDMSATHYCYTHNVILSGCRDHSHSHQYLALGVLRTTATGRIFFSTLRSISLDDTQNRKSCSVSATPLGCDMLCSKVTETEEEDYNSAVPTLMAHGRLGFDGQYHEKDLDVTTLFEDWVANYPGVGGGSFIDGRVWFSVYGGLKPNSPSDTVQEGKYVIYKRYNDTCPDEQDYQIRMAKSSYKPGRFGGKRIQQAILSIKVSTSLGEDPVLTVPPNTVTLMGAEGRILTVGTSHFLYQRGSSYFSPALLYPMTVSNKTATLHSPYTFNAFTRPGSIPCQASARCPNSCVTGVYTDPYPLIFYRNHTLRGVFGTMLDSEQARLNPTSAVFDSTSRSRITRVSSSSTKAAYTTSTCFKVVKTNKTYCLSIAEISNTLFGEFRIVPLLVEILKNDGV 571 SCOP domains d1usra_ A: Paramyxovirus hemagglutinin-neuraminidase head domain SCOP domains CATH domains 1usrA00 A:124-571 [code=2.120.10.10, no name defined] CATH domains Pfam domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1usr A 124 GAPIHDPDFIGGIGKELIVDNASDVTSFYPSAFQEHLNFIPAPTTGSGCTRIPSFDMSATHYCYTHNVILSGCRDHSHSHQYLALGVLRTTATGRIFFSTLRSISLDDTQNRKSCSVSATPLGCDMLCSKVTETEEEDYNSAVPTLMAHGRLGFDGQYHEKDLDVTTLFEDWVANYPGVGGGSFIDGRVWFSVYGGLKPNSPSDTVQEGKYVIYKRYNDTCPDEQDYQIRMAKSSYKPGRFGGKRIQQAILSIKVSTSLGEDPVLTVPPNTVTLMGAEGRILTVGTSHFLYQRGSSYFSPALLYPMTVSNKTATLHSPYTFNAFTRPGSIPCQASARCPNSCVTGVYTDPYPLIFYRNHTLRGVFGTMLDSEQARLNPASAVFDSTSRSRITRVSSSSTKAAYTTSTCFKVVKTNKTYCLSIAEISNTLFGEFRIVPLLVEILKNDGV 571 133 143 153 163 173 183 193 203 213 223 233 243 253 263 273 283 293 303 313 323 333 343 353 363 373 383 393 403 413 423 433 443 453 463 473 483 493 503 513 523 533 543 553 563 Chain B from PDB Type:PROTEIN Length:447 aligned with HN_NDVB | P32884 from UniProtKB/Swiss-Prot Length:577 Alignment length:447 133 143 153 163 173 183 193 203 213 223 233 243 253 263 273 283 293 303 313 323 333 343 353 363 373 383 393 403 413 423 433 443 453 463 473 483 493 503 513 523 533 543 553 563 HN_NDVB 124 GAPIHDPDFIGGIGKELIVDDASDVTSFYPSAFQEHLNFIPAPTTGSGCTRIPSFDMSATHYCYTHNVILSGCRDHSHSHQYLALGVLRTTATGRIFFSTLRSISLDDTQNRKSCSVSATPLGCDMLCSKVTETEEEDYNSAVPTLMAHGRLGFDGQYHEKDLDVTTLFEDWVANYPGVGGGSFIDGRVWFSVYGGLKPNSPSDTVQEGKYVIYKRYNDTCPDEQDYQIRMAKSSYKPGRFGGKRIQQAILSIKVSTSLGEDPVLTVPPNTVTLMGAEGRILTVGTSHFLYQRGSSYFSPALLYPMTVSNKTATLHSPYTFNAFTRPGSIPCQASARCPNSCVTGVYTDPYPLIFYRNHTLRGVFGTMLDSEQARLNPTSAVFDSTSRSRITRVSSSSTKAAYTTSTCFKVVKTNKTYCLSIAEISNTLFGEFRIVPLLVEILKNDG 570 SCOP domains d1usrb_ B: Paramyxovirus hemagglutinin-neuraminidase head domain SCOP domains CATH domains 1usrB00 B:124-570 [code=2.120.10.10, no name defined] CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1usr B 124 GAPIHDPDFIGGIGKELIVDNASDVTSFYPSAFQEHLNFIPAPTTGSGCTRIPSFDMSATHYCYTHNVILSGCRDHSHSHQYLALGVLRTTATGRIFFSTLRSISLDDTQNRKSCSVSATPLGCDMLCSKVTETEEEDYNSAVPTLMAHGRLGFDGQYHEKDLDVTTLFEDWVANYPGVGGGSFIDGRVWFSVYGGLKPNSPSDTVQEGKYVIYKRYNDTCPDEQDYQIRMAKSSYKPGRFGGKRIQQAILSIKVSTSLGEDPVLTVPPNTVTLMGAEGRILTVGTSHFLYQRGSSYFSPALLYPMTVSNKTATLHSPYTFNAFTRPGSIPCQASARCPNSCVTGVYTDPYPLIFYRNHTLRGVFGTMLDSEQARLNPASAVFDSTSRSRITRVSSSSTKAAYTTSTCFKVVKTNKTYCLSIAEISNTLFGEFRIVPLLVEILKNDG 570 133 143 153 163 173 183 193 203 213 223 233 243 253 263 273 283 293 303 313 323 333 343 353 363 373 383 393 403 413 423 433 443 453 463 473 483 493 503 513 523 533 543 553 563
|
||||||||||||||||||||
SCOP Domains (1, 2)
Asymmetric/Biological Unit
 |
CATH Domains (1, 2)
Asymmetric/Biological Unit
|
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 1USR) |
Gene Ontology (17, 17)|
Asymmetric/Biological Unit(hide GO term definitions) Chain A,B (HN_NDVB | P32884)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|