| molecular function |
|---|
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0000981 | | RNA polymerase II transcription factor activity, sequence-specific DNA binding | | Interacting selectively and non-covalently with a specific DNA sequence in order to modulate transcription by RNA polymerase II. The transcription factor may or may not also interact selectively with a protein or macromolecular complex. |
| | GO:0035035 | | histone acetyltransferase binding | | Interacting selectively and non-covalently with the enzyme histone acetyltransferase. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0046983 | | protein dimerization activity | | The formation of a protein dimer, a macromolecular structure consists of two noncovalently associated identical or nonidentical subunits. |
| | GO:0046982 | | protein heterodimerization activity | | Interacting selectively and non-covalently with a nonidentical protein to form a heterodimer. |
| | GO:0043565 | | sequence-specific DNA binding | | Interacting selectively and non-covalently with DNA of a specific nucleotide composition, e.g. GC-rich DNA binding, or with a specific sequence motif or type of DNA e.g. promotor binding or rDNA binding. |
| | GO:0003700 | | transcription factor activity, sequence-specific DNA binding | | Interacting selectively and non-covalently with a specific DNA sequence in order to modulate transcription. The transcription factor may or may not also interact selectively with a protein or macromolecular complex. |
| | GO:0008134 | | transcription factor binding | | Interacting selectively and non-covalently with a transcription factor, any protein required to initiate or regulate transcription. |
| | GO:0001077 | | transcriptional activator activity, RNA polymerase II core promoter proximal region sequence-specific binding | | Interacting selectively and non-covalently with a sequence of DNA that is in cis with and relatively close to a core promoter for RNA polymerase II (RNAP II) in order to activate or increase the frequency, rate or extent of transcription from the RNAP II promoter. |
| biological process |
|---|
| | GO:0001525 | | angiogenesis | | Blood vessel formation when new vessels emerge from the proliferation of pre-existing blood vessels. |
| | GO:0001974 | | blood vessel remodeling | | The reorganization or renovation of existing blood vessels. |
| | GO:0030154 | | cell differentiation | | The process in which relatively unspecialized cells, e.g. embryonic or regenerative cells, acquire specialized structural and/or functional features that characterize the cells, tissues, or organs of the mature organism or some other relatively stable phase of the organism's life history. Differentiation includes the processes involved in commitment of a cell to a specific fate and its subsequent development to the mature state. |
| | GO:0048469 | | cell maturation | | A developmental process, independent of morphogenetic (shape) change, that is required for a cell to attain its fully functional state. |
| | GO:0071456 | | cellular response to hypoxia | | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus indicating lowered oxygen tension. Hypoxia, defined as a decline in O2 levels below normoxic levels of 20.8 - 20.95%, results in metabolic adaptation at both the cellular and organismal level. |
| | GO:0001892 | | embryonic placenta development | | The embryonically driven process whose specific outcome is the progression of the placenta over time, from its formation to the mature structure. The placenta is an organ of metabolic interchange between fetus and mother, partly of embryonic origin and partly of maternal origin. |
| | GO:0030218 | | erythrocyte differentiation | | The process in which a myeloid precursor cell acquires specializes features of an erythrocyte. |
| | GO:0030097 | | hemopoiesis | | The process whose specific outcome is the progression of the myeloid and lymphoid derived organ/tissue systems of the blood and other parts of the body over time, from formation to the mature structure. The site of hemopoiesis is variable during development, but occurs primarily in bone marrow or kidney in many adult vertebrates. |
| | GO:0055072 | | iron ion homeostasis | | Any process involved in the maintenance of an internal steady state of iron ions within an organism or cell. |
| | GO:0030324 | | lung development | | The process whose specific outcome is the progression of the lung over time, from its formation to the mature structure. In all air-breathing vertebrates the lungs are developed from the ventral wall of the oesophagus as a pouch which divides into two sacs. In amphibians and many reptiles the lungs retain very nearly this primitive sac-like character, but in the higher forms the connection with the esophagus becomes elongated into the windpipe and the inner walls of the sacs become more and more divided, until, in the mammals, the air spaces become minutely divided into tubes ending in small air cells, in the walls of which the blood circulates in a fine network of capillaries. In mammals the lungs are more or less divided into lobes, and each lung occupies a separate cavity in the thorax. |
| | GO:0007005 | | mitochondrion organization | | A process that is carried out at the cellular level which results in the assembly, arrangement of constituent parts, or disassembly of a mitochondrion; includes mitochondrial morphogenesis and distribution, and replication of the mitochondrial genome as well as synthesis of new mitochondrial components. |
| | GO:0007275 | | multicellular organism development | | The biological process whose specific outcome is the progression of a multicellular organism over time from an initial condition (e.g. a zygote or a young adult) to a later condition (e.g. a multicellular animal or an aged adult). |
| | GO:0048625 | | myoblast fate commitment | | The process in which the developmental fate of a cell becomes restricted such that it will develop into a myoblast. A myoblast is a mononucleate cell type that, by fusion with other myoblasts, gives rise to the myotubes that eventually develop into skeletal muscle fibers. |
| | GO:0042415 | | norepinephrine metabolic process | | The chemical reactions and pathways involving norepinephrine, a hormone secreted by the adrenal medulla, and a neurotransmitter in the sympathetic peripheral nervous system and in some tracts in the central nervous system. It is also the demethylated biosynthetic precursor of epinephrine. |
| | GO:0045944 | | positive regulation of transcription from RNA polymerase II promoter | | Any process that activates or increases the frequency, rate or extent of transcription from an RNA polymerase II promoter. |
| | GO:0002027 | | regulation of heart rate | | Any process that modulates the frequency or rate of heart contraction. |
| | GO:0061418 | | regulation of transcription from RNA polymerase II promoter in response to hypoxia | | Any process that modulates the frequency, rate or extent of transcription from an RNA polymerase II promoter as a result of a hypoxia stimulus. |
| | GO:0043619 | | regulation of transcription from RNA polymerase II promoter in response to oxidative stress | | Modulation of the frequency, rate or extent of transcription from an RNA polymerase II promoter as a result of a stimulus indicating the organism is under oxidative stress, a state often resulting from exposure to high levels of reactive oxygen species, e.g. superoxide anions, hydrogen peroxide (H2O2), and hydroxyl radicals. |
| | GO:0006355 | | regulation of transcription, DNA-templated | | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0001666 | | response to hypoxia | | Any process that results in a change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus indicating lowered oxygen tension. Hypoxia, defined as a decline in O2 levels below normoxic levels of 20.8 - 20.95%, results in metabolic adaptation at both the cellular and organismal level. |
| | GO:0006979 | | response to oxidative stress | | Any process that results in a change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of oxidative stress, a state often resulting from exposure to high levels of reactive oxygen species, e.g. superoxide anions, hydrogen peroxide (H2O2), and hydroxyl radicals. |
| | GO:0007165 | | signal transduction | | The cellular process in which a signal is conveyed to trigger a change in the activity or state of a cell. Signal transduction begins with reception of a signal (e.g. a ligand binding to a receptor or receptor activation by a stimulus such as light), or for signal transduction in the absence of ligand, signal-withdrawal or the activity of a constitutively active receptor. Signal transduction ends with regulation of a downstream cellular process, e.g. regulation of transcription or regulation of a metabolic process. Signal transduction covers signaling from receptors located on the surface of the cell and signaling via molecules located within the cell. For signaling between cells, signal transduction is restricted to events at and within the receiving cell. |
| | GO:0035019 | | somatic stem cell population maintenance | | Any process by which an organism retains a population of somatic stem cells, undifferentiated cells in the embryo or adult which can undergo unlimited division and give rise to cell types of the body other than those of the germ-line. |
| | GO:0043129 | | surfactant homeostasis | | Any process involved in the maintenance of a steady-state level of the surface-active lipoprotein mixture which coats the alveoli. |
| | GO:0006366 | | transcription from RNA polymerase II promoter | | The synthesis of RNA from a DNA template by RNA polymerase II, originating at an RNA polymerase II promoter. Includes transcription of messenger RNA (mRNA) and certain small nuclear RNAs (snRNAs). |
| | GO:0006351 | | transcription, DNA-templated | | The cellular synthesis of RNA on a template of DNA. |
| | GO:0007601 | | visual perception | | The series of events required for an organism to receive a visual stimulus, convert it to a molecular signal, and recognize and characterize the signal. Visual stimuli are detected in the form of photons and are processed to form an image. |
| cellular component |
|---|
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0005829 | | cytosol | | The part of the cytoplasm that does not contain organelles but which does contain other particulate matter, such as protein complexes. |
| | GO:0016607 | | nuclear speck | | A discrete extra-nucleolar subnuclear domain, 20-50 in number, in which splicing factors are seen to be localized by immunofluorescence microscopy. |
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0005667 | | transcription factor complex | | A protein complex that is capable of associating with DNA by direct binding, or via other DNA-binding proteins or complexes, and regulating transcription. |
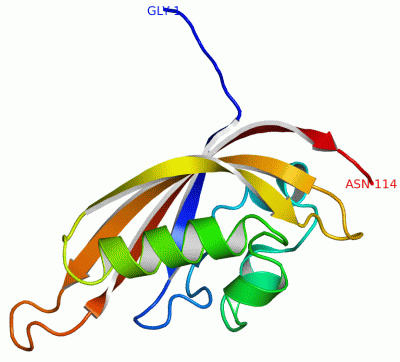
 Description
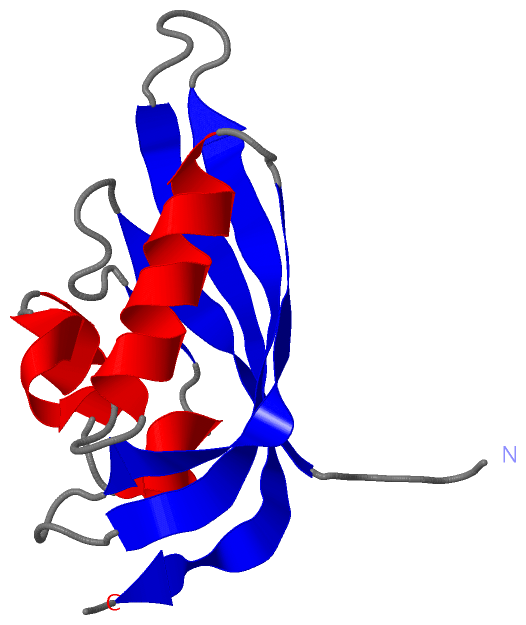
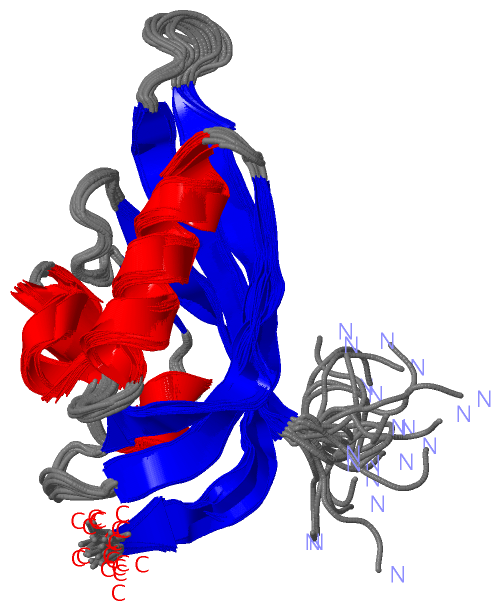
Description