|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
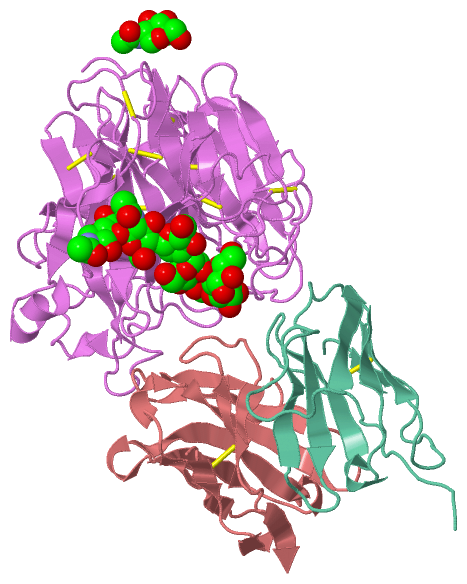
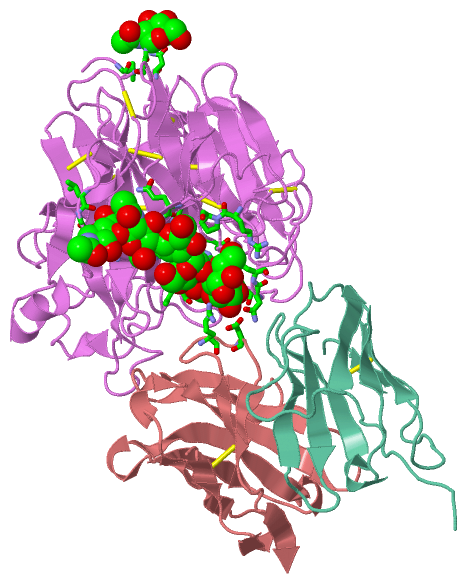
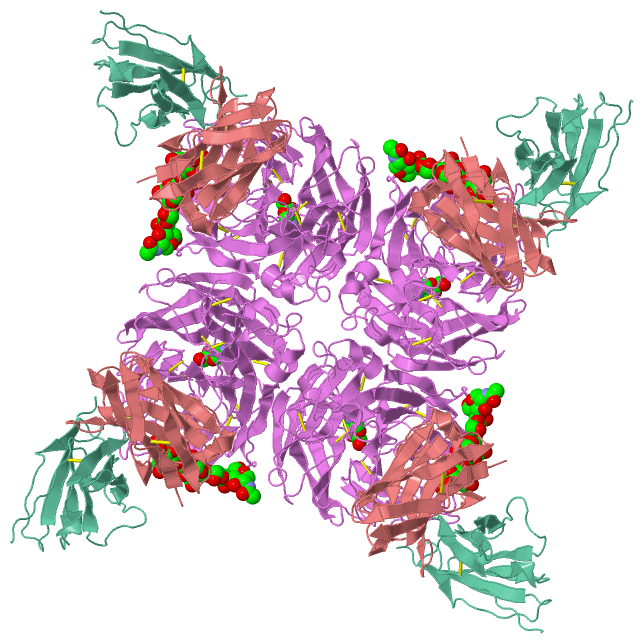
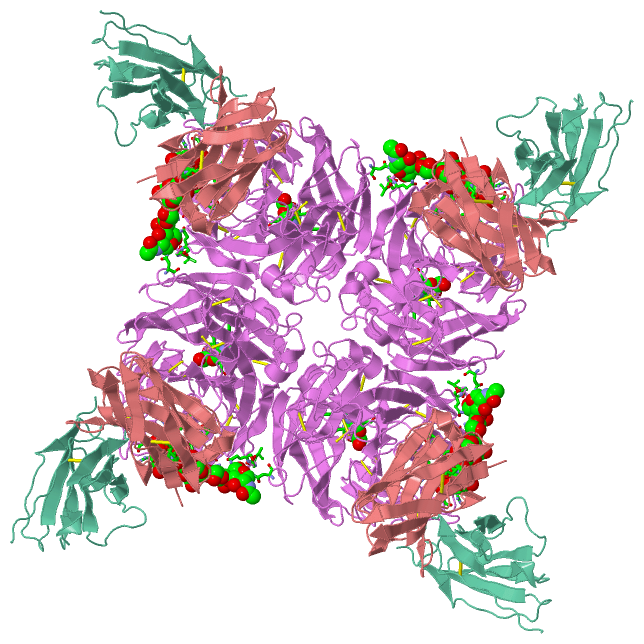
Ligands, Modified Residues, Ions (3, 7)| Asymmetric Unit (3, 7) Biological Unit 1 (3, 28) |
Sites (7, 7)
Asymmetric Unit (7, 7)
|
SS Bonds (11, 11)
Asymmetric Unit
|
||||||||||||||||||||||||||||||||||||||||||||||||
Cis Peptide Bonds (3, 3)
Asymmetric Unit
|
||||||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 1NMA) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 1NMA) |
Exons (0, 0)| (no "Exon" information available for 1NMA) |
Sequences/Alignments
Asymmetric Unit
Chain H from PDB Type:PROTEIN Length:122
SCOP domains d1nmah_ H: Immunoglobulin heavy chain variable domain, VH SCOP domains
CATH domains 1nmaH00 H:1-113 Immunoglobulins CATH domains
Pfam domains -------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) -------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE -------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript -------------------------------------------------------------------------------------------------------------------------- Transcript
1nma H 1 EVQLQQPGAELVKPGASVRMSCKASGYTFTNYNMYWVKQSPGQGLEWIGIFYPGNGDTSYNQKFKDKATLTADKSSNTAYMQLSSLTSEDSAVYYCARSGGSYRYDGGFDYWGQGTTLTVSS 113
10 20 30 40 50 | 59 69 79 ||| 86 96 |||101 111
52A 82A|| 100A||||
82B| 100B|||
82C 100C||
100D|
100E
Chain L from PDB Type:PROTEIN Length:109
SCOP domains d1nmal_ L: Immunoglobulin light chain kappa variable domain, VL-kappa SCOP domains
CATH domains 1nmaL00 L:1-109 Immunoglobulins CATH domains
Pfam domains ------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) ------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ------------------------------------------------------------------------------------------------------------- Transcript
1nma L 1 DIQMTQTTSSLSASLGDRVTISCRASQDISNYLNWYQQNPDGTVKLLIYYTSNLHSEVPSRFSGSGSGTDYSLTISNLEQEDIATYFCQQDFTLPFTFGGGTKLEIRRA 109
10 20 30 40 50 60 70 80 90 100
Chain N from PDB Type:PROTEIN Length:378 aligned with NRAM_I84A1 | P05803 from UniProtKB/Swiss-Prot Length:470 Alignment length:378 92 102 112 122 132 142 152 162 172 182 192 202 212 222 232 242 252 262 272 282 292 302 312 322 332 342 352 362 372 382 392 402 412 422 432 442 452 NRAM_I84A1 83 REFNNLTKGLCTINSWHIYGKDNAVRIGEDSDVLVTREPYVSCDPDECRFYALSQGTTIRGKHSNGTIHDRSQYRDLISWPLSSPPTVYNSRVECIGWSSTSCHDGRARMSICISGPNNNASAVIWYNRRPVTEINTWARNILRTQESECVCQNGVCPVVFTDGSATGPAETRIYYFKEGKILKWEPLTGTAKHIEECSCYGEQAGVTCTCRDNWQGSNRPVIQIDPVAMTHTSQYICSPVLTDNPRPNDPTVGKCNDPYPGNNNNGVKGFSYLDGGNTWLGRTISIASRSGYEMLKVPNALTDDRSKPTQGQTIVLNTDWSGYSGSFMDYWAEGECYRACFYVELIRGRPKEDKVWWTSNSIVSMCSSTEFLGQWNW 460 SCOP domains d1nman_ N: Influenza neuraminidase SCOP domains CATH domains 1nmaN00 N:82-458 [code=2.120.10.10, no name defined] CATH domains Pfam domains Neur-1nmaN01 N:82-458 Pfam domains SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SAPs(SNPs) PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ PROSITE Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Transcript 1nma N 82 REFNNLTKGLCTINSWHIYGKDNAVRIGEDSDVLVTREPYVSCDPDECRFYALSQGTTIRGKHSNGTIHDRSQYRDLISWPLSSPPTVYNSRVECIGWSSTSCHDGRARMSICISGPNNNASAVIWYNRRPVTEINTWARNILRTQESECVCQNGVCPVVFTDGSATGPAETRIYYFKEGKILKWEPLTGTAKHIEECSCYGEQAGVTCTCRDNWQGSNRPVIQIDPVAMTHTSQYICSPVLTDNPRPNDPTVGKCNDPYPGNNNNGVKGFSYLDGGNTWLGRTISIASRSGYEMLKVPNALTDDKSRPTQGQTIVLNTDWSGYSGSFMDYWAEGECYRACFYVELIRGRPKEDKVWWTSNSIVSMCSSTEFLGQWNW 458 91 101 111 121 131 141 151 161 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 || 341 351 361 371 381 391|| 402 412|| 420 430 440 450 169A 333| 392| 412A| 335 394 412B
|
||||||||||||||||||||
SCOP Domains (3, 3)
Asymmetric Unit
 |
CATH Domains (2, 3)
Asymmetric Unit
|
Pfam Domains (1, 1)
Asymmetric Unit
|
Gene Ontology (15, 15)|
Asymmetric Unit(hide GO term definitions) Chain N (NRAM_I84A1 | P05803)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|