|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
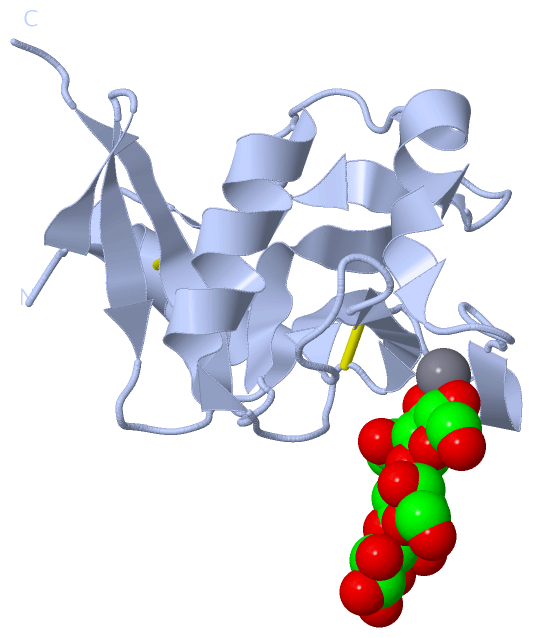
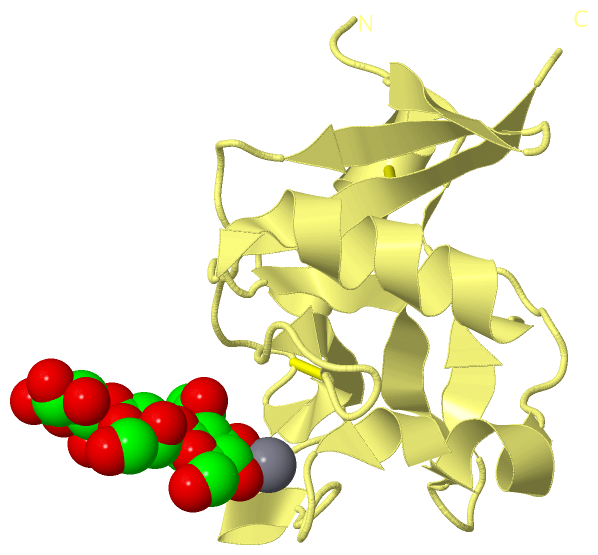
Ligands, Modified Residues, Ions (4, 15)
Asymmetric Unit (4, 15)
|
Sites (8, 8)
Asymmetric Unit (8, 8)
|
SS Bonds (8, 8)
Asymmetric Unit
|
||||||||||||||||||||||||||||||||||||
Cis Peptide Bonds (4, 4)
Asymmetric Unit
|
||||||||||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 4N35) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 4N35) |
Exons (0, 0)| (no "Exon" information available for 4N35) |
Sequences/Alignments
Asymmetric Unit
Chain A from PDB Type:PROTEIN Length:128
SCOP domains d4n35a_ A: automated matches SCOP domains
CATH domains -------------------------------------------------------------------------------------------------------------------------------- CATH domains
Pfam domains -------------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) -------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE -------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript -------------------------------------------------------------------------------------------------------------------------------- Transcript
4n35 A 198 GWKYFKGNFYYFSLIPKTWYSAEQFCVSRNSHLTSVTSESEQEFLYKTAGGLIYWIGLTKAGMEGDWSWVDDTPFNKVQSARFWIPGEPNNAGNNEHCGNIKAPSLQAWNDAPCDITFLFICKRPYVP 325
207 217 227 237 247 257 267 277 287 297 307 317
Chain B from PDB Type:PROTEIN Length:128
SCOP domains d4n35b_ B: automated matches SCOP domains
CATH domains -------------------------------------------------------------------------------------------------------------------------------- CATH domains
Pfam domains -------------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) -------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE -------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript -------------------------------------------------------------------------------------------------------------------------------- Transcript
4n35 B 198 GWKYFKGNFYYFSLIPKTWYSAEQFCVSRNSHLTSVTSESEQEFLYKTAGGLIYWIGLTKAGMEGDWSWVDDTPFNKVQSARFWIPGEPNNAGNNEHCGNIKAPSLQAWNDAPCDITFLFICKRPYVP 325
207 217 227 237 247 257 267 277 287 297 307 317
Chain C from PDB Type:PROTEIN Length:130
SCOP domains d4n35c_ C: automated matches SCOP domains
CATH domains ---------------------------------------------------------------------------------------------------------------------------------- CATH domains
Pfam domains ---------------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ---------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ---------------------------------------------------------------------------------------------------------------------------------- Transcript
4n35 C 196 SQGWKYFKGNFYYFSLIPKTWYSAEQFCVSRNSHLTSVTSESEQEFLYKTAGGLIYWIGLTKAGMEGDWSWVDDTPFNKVQSARFWIPGEPNNAGNNEHCGNIKAPSLQAWNDAPCDITFLFICKRPYVP 325
205 215 225 235 245 255 265 275 285 295 305 315 325
Chain D from PDB Type:PROTEIN Length:128
SCOP domains d4n35d_ D: automated matches SCOP domains
CATH domains -------------------------------------------------------------------------------------------------------------------------------- CATH domains
Pfam domains -------------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) -------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE -------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript -------------------------------------------------------------------------------------------------------------------------------- Transcript
4n35 D 197 QGWKYFKGNFYYFSLIPKTWYSAEQFCVSRNSHLTSVTSESEQEFLYKTAGGLIYWIGLTKAGMEGDWSWVDDTPFNKVQSARFWIPGEPNNAGNNEHCGNIKAPSLQAWNDAPCDITFLFICKRPYV 324
206 216 226 236 246 256 266 276 286 296 306 316
|
||||||||||||||||||||
SCOP Domains (1, 4)
Asymmetric Unit
 |
CATH Domains (0, 0)| (no "CATH Domain" information available for 4N35) |
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 4N35) |
Gene Ontology (11, 11)|
Asymmetric Unit(hide GO term definitions) |
Interactive Views
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|