|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (3, 8)| Asymmetric Unit (3, 8) Biological Unit 1 (3, 16) |
Sites (8, 8)
Asymmetric Unit (8, 8)
|
SS Bonds (0, 0)| (no "SS Bond" information available for 4B4C) |
Cis Peptide Bonds (1, 1)
Asymmetric Unit
|
||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 4B4C) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 4B4C) |
Exons (7, 7)
Sequences/Alignments
Asymmetric UnitChain A from PDB Type:PROTEIN Length:187 aligned with CHD1_HUMAN | O14646 from UniProtKB/Swiss-Prot Length:1710 Alignment length:204 1133 1143 1153 1163 1173 1183 1193 1203 1213 1223 1233 1243 1253 1263 1273 1283 1293 1303 1313 1323 CHD1_HUMAN 1124 KGFSDAEIRRFIKSYKKFGGPLERLDAIARDAELVDKSETDLRRLGELVHNGCIKALKDSSSGTERTGGRLGKVKGPTFRISGVQVNAKLVISHEEELIPLHKSIPSDPEERKQYTIPCHTKAAHFDIDWGKEDDSNLLIGIYEYGYGSWEMIKMDPDLSLTHKILPDDPDKKPQAKQLQTRADYLIKLLSRDLAKKEALSGAG 1327 SCOP domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SCOP domains CATH domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ CATH domains Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Pfam domains SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SAPs(SNPs) PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ PROSITE Transcript 1 (1) Exon 1.23 -------------Exon 1.25 PDB: A:1147-1181 [INCOMPLETE] ---------------------------------------------Exon 1.26c PDB: A:1237-1287 UniProt: 1237-1287 Exon 1.27a PDB: A:1288-1326 1 Transcript 1 (1) Transcript 1 (2) ---------Exon 1.24 -------------------------------------------Exon 1.26b PDB: A:1199-1237 UniProt: 1191-1237------------------------------------------------------------------------------------------ Transcript 1 (2) 4b4c A 1124 KGFSDAEIRRFIKSYKKFGGPLERLDAIARDAELVDKSETDLRRLGELVHNGCIKALK-----------------GPTFRISGVQVNAKLVISHEEELIPLHKSIPSDPEERKQYTIPCHTKAAHFDIDWGKEDDSNLLIGIYEYGYGSWEMIKMDPDLSLTHKILPDDPDKKPQAKQLQTRADYLIKLLSRDLAKKEALSGAG 1327 1133 1143 1153 1163 1173 | - - |1203 1213 1223 1233 1243 1253 1263 1273 1283 1293 1303 1313 1323 1181 1199
|
||||||||||||||||||||
SCOP Domains (0, 0)| (no "SCOP Domain" information available for 4B4C) |
CATH Domains (0, 0)| (no "CATH Domain" information available for 4B4C) |
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 4B4C) |
Gene Ontology (16, 16)|
Asymmetric Unit(hide GO term definitions) Chain A (CHD1_HUMAN | O14646)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
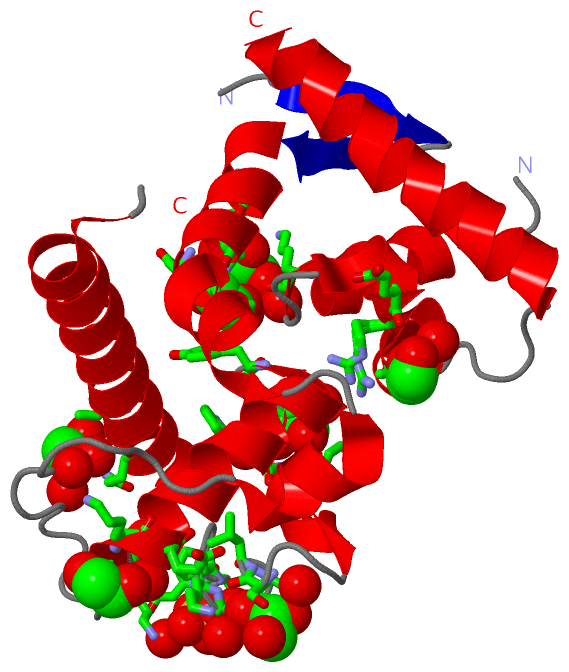
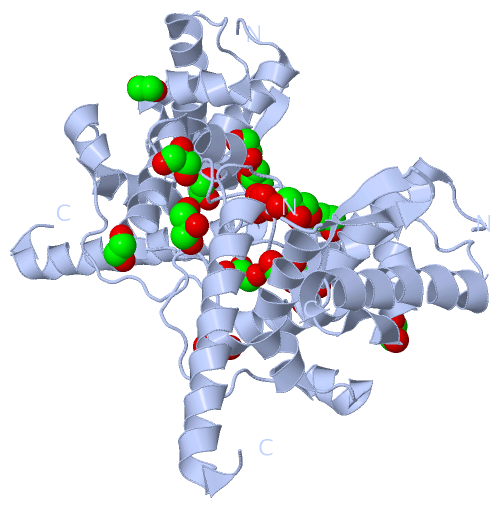
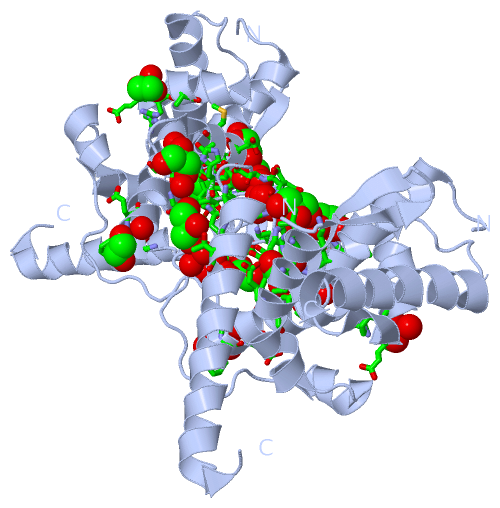
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|