| molecular function |
|---|
| | GO:0005524 | | ATP binding | | Interacting selectively and non-covalently with ATP, adenosine 5'-triphosphate, a universally important coenzyme and enzyme regulator. |
| | GO:0003723 | | RNA binding | | Interacting selectively and non-covalently with an RNA molecule or a portion thereof. |
| | GO:0003724 | | RNA helicase activity | | Catalysis of the reaction: NTP + H2O = NDP + phosphate, to drive the unwinding of a RNA helix. |
| | GO:0003968 | | RNA-directed 5'-3' RNA polymerase activity | | Catalysis of the reaction: nucleoside triphosphate + RNA(n) = diphosphate + RNA(n+1); uses an RNA template, i.e. the catalysis of RNA-template-directed extension of the 3'-end of an RNA strand by one nucleotide at a time. |
| | GO:0004197 | | cysteine-type endopeptidase activity | | Catalysis of the hydrolysis of internal, alpha-peptide bonds in a polypeptide chain by a mechanism in which the sulfhydryl group of a cysteine residue at the active center acts as a nucleophile. |
| | GO:0008234 | | cysteine-type peptidase activity | | Catalysis of the hydrolysis of peptide bonds in a polypeptide chain by a mechanism in which the sulfhydryl group of a cysteine residue at the active center acts as a nucleophile. |
| | GO:0004386 | | helicase activity | | Catalysis of the reaction: NTP + H2O = NDP + phosphate, to drive the unwinding of a DNA or RNA helix. |
| | GO:0016787 | | hydrolase activity | | Catalysis of the hydrolysis of various bonds, e.g. C-O, C-N, C-C, phosphoric anhydride bonds, etc. Hydrolase is the systematic name for any enzyme of EC class 3. |
| | GO:0005216 | | ion channel activity | | Enables the facilitated diffusion of an ion (by an energy-independent process) by passage through a transmembrane aqueous pore or channel without evidence for a carrier-mediated mechanism. May be either selective (it enables passage of a specific ion only) or non-selective (it enables passage of two or more ions of same charge but different size). |
| | GO:0017111 | | nucleoside-triphosphatase activity | | Catalysis of the reaction: a nucleoside triphosphate + H2O = nucleoside diphosphate + phosphate. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| | GO:0016779 | | nucleotidyltransferase activity | | Catalysis of the transfer of a nucleotidyl group to a reactant. |
| | GO:0008233 | | peptidase activity | | Catalysis of the hydrolysis of a peptide bond. A peptide bond is a covalent bond formed when the carbon atom from the carboxyl group of one amino acid shares electrons with the nitrogen atom from the amino group of a second amino acid. |
| | GO:0005198 | | structural molecule activity | | The action of a molecule that contributes to the structural integrity of a complex or its assembly within or outside a cell. |
| | GO:0016740 | | transferase activity | | Catalysis of the transfer of a group, e.g. a methyl group, glycosyl group, acyl group, phosphorus-containing, or other groups, from one compound (generally regarded as the donor) to another compound (generally regarded as the acceptor). Transferase is the systematic name for any enzyme of EC class 2. |
| biological process |
|---|
| | GO:0018144 | | RNA-protein covalent cross-linking | | The formation of a covalent cross-link between RNA and a protein. |
| | GO:0034220 | | ion transmembrane transport | | A process in which an ion is transported from one side of a membrane to the other by means of some agent such as a transporter or pore. |
| | GO:0006811 | | ion transport | | The directed movement of charged atoms or small charged molecules into, out of or within a cell, or between cells, by means of some agent such as a transporter or pore. |
| | GO:0039707 | | pore formation by virus in membrane of host cell | | The aggregation, arrangement and bonding together of a set of components by a virus to form a pore complex in a membrane of a host organism. |
| | GO:0051259 | | protein oligomerization | | The process of creating protein oligomers, compounds composed of a small number, usually between three and ten, of component monomers; protein oligomers may be composed of different or identical monomers. Oligomers may be formed by the polymerization of a number of monomers or the depolymerization of a large protein polymer. |
| | GO:0006508 | | proteolysis | | The hydrolysis of proteins into smaller polypeptides and/or amino acids by cleavage of their peptide bonds. |
| | GO:0006351 | | transcription, DNA-templated | | The cellular synthesis of RNA on a template of DNA. |
| | GO:0001172 | | transcription, RNA-templated | | The cellular synthesis of RNA on a template of RNA. |
| | GO:0006810 | | transport | | The directed movement of substances (such as macromolecules, small molecules, ions) or cellular components (such as complexes and organelles) into, out of or within a cell, or between cells, or within a multicellular organism by means of some agent such as a transporter, pore or motor protein. |
| | GO:0039694 | | viral RNA genome replication | | The replication of a viral RNA genome. |
| | GO:0046718 | | viral entry into host cell | | The process that occurs after viral attachment by which a virus, or viral nucleic acid, breaches the plasma membrane or cell envelope and enters the host cell. The process ends when the viral nucleic acid is released into the host cell cytoplasm. |
| | GO:0016032 | | viral process | | A multi-organism process in which a virus is a participant. The other participant is the host. Includes infection of a host cell, replication of the viral genome, and assembly of progeny virus particles. In some cases the viral genetic material may integrate into the host genome and only subsequently, under particular circumstances, 'complete' its life cycle. |
| | GO:0019062 | | virion attachment to host cell | | The process by which a virion protein binds to molecules on the host cellular surface or host cell surface projection. |
| cellular component |
|---|
| | GO:0030430 | | host cell cytoplasm | | The cytoplasm of a host cell. |
| | GO:0044161 | | host cell cytoplasmic vesicle | | A vesicle formed of membrane or protein, found in the cytoplasm of a host cell. |
| | GO:0044162 | | host cell cytoplasmic vesicle membrane | | The lipid bilayer surrounding a host cell cytoplasmic vesicle. |
| | GO:0033644 | | host cell membrane | | Double layer of lipid molecules as it encloses host cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins. The host is defined as the larger of the organisms involved in a symbiotic interaction. |
| | GO:0044385 | | integral to membrane of host cell | | Penetrating at least one phospholipid bilayer of a membrane. May also refer to the state of being buried in the bilayer with no exposure outside the bilayer. When used to describe a protein, indicates that all or part of the peptide sequence is embedded in the membrane. Occurring in a host cell. |
| | GO:0016020 | | membrane | | A lipid bilayer along with all the proteins and protein complexes embedded in it an attached to it. |
| | GO:0019028 | | viral capsid | | The protein coat that surrounds the infective nucleic acid in some virus particles. It comprises numerous regularly arranged subunits, or capsomeres. |
| | GO:0019012 | | virion | | The complete fully infectious extracellular virus particle. |
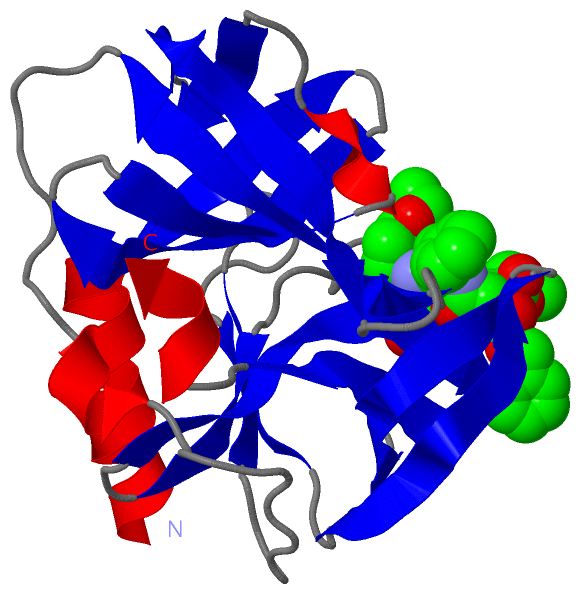
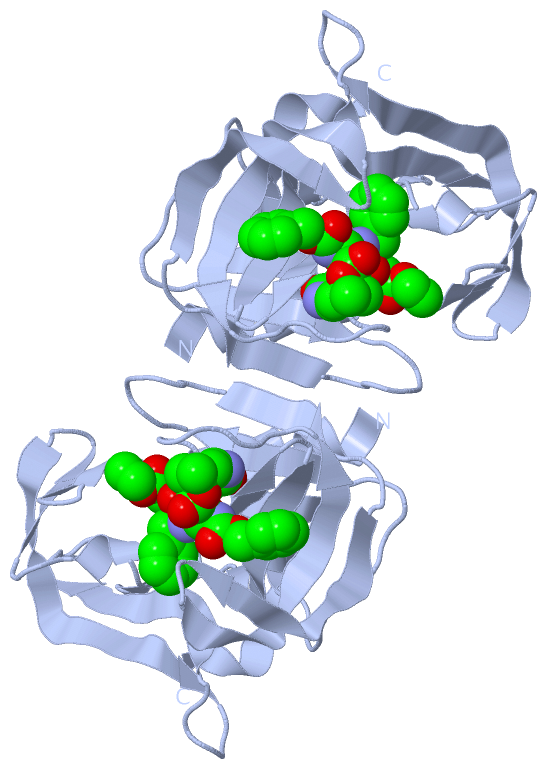
 Description
Description