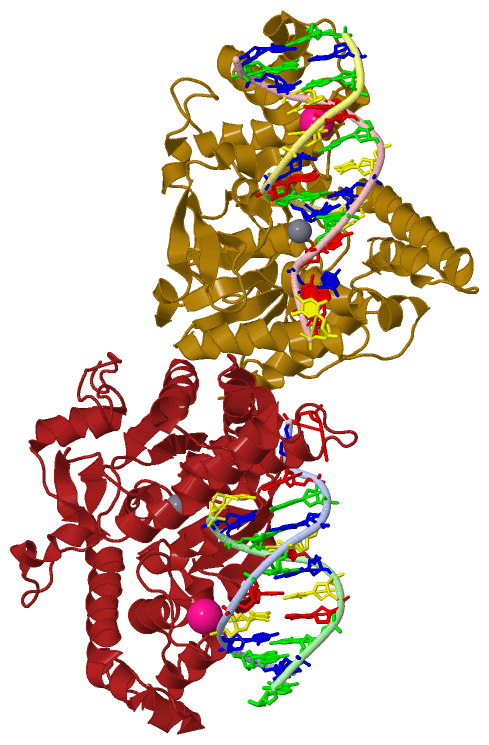
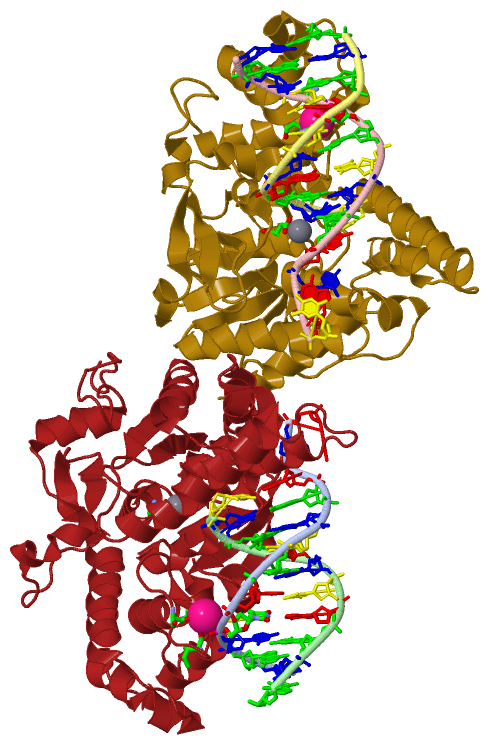
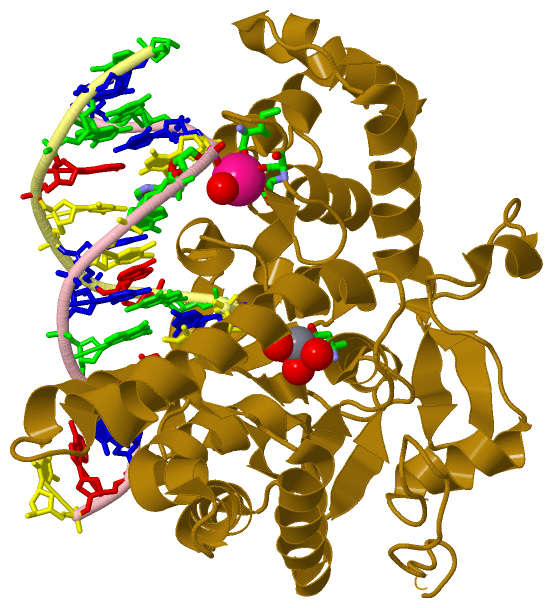
| molecular function |
|---|
| | GO:0035312 | | 5'-3' exodeoxyribonuclease activity | | Catalysis of the sequential cleavage of mononucleotides from a free 5' terminus of a DNA molecule. |
| | GO:0008409 | | 5'-3' exonuclease activity | | Catalysis of the hydrolysis of ester linkages within nucleic acids by removing nucleotide residues from the 5' end. |
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0004523 | | RNA-DNA hybrid ribonuclease activity | | Catalysis of the endonucleolytic cleavage of RNA in RNA-DNA hybrids to 5'-phosphomonoesters. |
| | GO:0003824 | | catalytic activity | | Catalysis of a biochemical reaction at physiological temperatures. In biologically catalyzed reactions, the reactants are known as substrates, and the catalysts are naturally occurring macromolecular substances known as enzymes. Enzymes possess specific binding sites for substrates, and are usually composed wholly or largely of protein, but RNA that has catalytic activity (ribozyme) is often also regarded as enzymatic. |
| | GO:0003682 | | chromatin binding | | Interacting selectively and non-covalently with chromatin, the network of fibers of DNA, protein, and sometimes RNA, that make up the chromosomes of the eukaryotic nucleus during interphase. |
| | GO:0051908 | | double-stranded DNA 5'-3' exodeoxyribonuclease activity | | Catalysis of the sequential cleavage of mononucleotides from a free 5' terminus of a double-stranded DNA molecule. |
| | GO:0004519 | | endonuclease activity | | Catalysis of the hydrolysis of ester linkages within nucleic acids by creating internal breaks. |
| | GO:0004527 | | exonuclease activity | | Catalysis of the hydrolysis of ester linkages within nucleic acids by removing nucleotide residues from the 3' or 5' end. |
| | GO:0048256 | | flap endonuclease activity | | Catalysis of the cleavage of a flap structure in DNA, but not other DNA structures; processes the ends of Okazaki fragments in lagging strand DNA synthesis. |
| | GO:0016787 | | hydrolase activity | | Catalysis of the hydrolysis of various bonds, e.g. C-O, C-N, C-C, phosphoric anhydride bonds, etc. Hydrolase is the systematic name for any enzyme of EC class 3. |
| | GO:0016788 | | hydrolase activity, acting on ester bonds | | Catalysis of the hydrolysis of any ester bond. |
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0004518 | | nuclease activity | | Catalysis of the hydrolysis of ester linkages within nucleic acids. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0045145 | | single-stranded DNA 5'-3' exodeoxyribonuclease activity | | Catalysis of the sequential cleavage of nucleotides (such as mononucleotides or dinucleotides) from a free 5' terminus of a single-stranded DNA molecule. |
| biological process |
|---|
| | GO:0006310 | | DNA recombination | | Any process in which a new genotype is formed by reassortment of genes resulting in gene combinations different from those that were present in the parents. In eukaryotes genetic recombination can occur by chromosome assortment, intrachromosomal recombination, or nonreciprocal interchromosomal recombination. Intrachromosomal recombination occurs by crossing over. In bacteria it may occur by genetic transformation, conjugation, transduction, or F-duction. |
| | GO:0006281 | | DNA repair | | The process of restoring DNA after damage. Genomes are subject to damage by chemical and physical agents in the environment (e.g. UV and ionizing radiations, chemical mutagens, fungal and bacterial toxins, etc.) and by free radicals or alkylating agents endogenously generated in metabolism. DNA is also damaged because of errors during its replication. A variety of different DNA repair pathways have been reported that include direct reversal, base excision repair, nucleotide excision repair, photoreactivation, bypass, double-strand break repair pathway, and mismatch repair pathway. |
| | GO:0006260 | | DNA replication | | The cellular metabolic process in which a cell duplicates one or more molecules of DNA. DNA replication begins when specific sequences, known as origins of replication, are recognized and bound by initiation proteins, and ends when the original DNA molecule has been completely duplicated and the copies topologically separated. The unit of replication usually corresponds to the genome of the cell, an organelle, or a virus. The template for replication can either be an existing DNA molecule or RNA. |
| | GO:0000731 | | DNA synthesis involved in DNA repair | | Synthesis of DNA that proceeds from the broken 3' single-strand DNA end and uses the homologous intact duplex as the template. |
| | GO:0090502 | | RNA phosphodiester bond hydrolysis, endonucleolytic | | The chemical reactions and pathways involving the hydrolysis of internal 3',5'-phosphodiester bonds in one or two strands of ribonucleotides. |
| | GO:0006974 | | cellular response to DNA damage stimulus | | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus indicating damage to its DNA from environmental insults or errors during metabolism. |
| | GO:0002455 | | humoral immune response mediated by circulating immunoglobulin | | An immune response dependent upon secreted immunoglobulin. An example of this process is found in Mus musculus. |
| | GO:0002376 | | immune system process | | Any process involved in the development or functioning of the immune system, an organismal system for calibrated responses to potential internal or invasive threats. |
| | GO:0045190 | | isotype switching | | The switching of activated B cells from IgM biosynthesis to biosynthesis of other isotypes of immunoglobulin, accomplished through a recombination process involving an intrachromosomal deletion involving switch regions that reside 5' of each constant region gene segment in the immunoglobulin heavy chain locus. |
| | GO:0051321 | | meiotic cell cycle | | Progression through the phases of the meiotic cell cycle, in which canonically a cell replicates to produce four offspring with half the chromosomal content of the progenitor cell via two nuclear divisions. |
| | GO:0006298 | | mismatch repair | | A system for the correction of errors in which an incorrect base, which cannot form hydrogen bonds with the corresponding base in the parent strand, is incorporated into the daughter strand. The mismatch repair system promotes genomic fidelity by repairing base-base mismatches, insertion-deletion loops and heterologies generated during DNA replication and recombination. |
| | GO:0090305 | | nucleic acid phosphodiester bond hydrolysis | | The nucleic acid metabolic process in which the phosphodiester bonds between nucleotides are cleaved by hydrolysis. |
| | GO:1901796 | | regulation of signal transduction by p53 class mediator | | Any process that modulates the frequency, rate or extent of signal transduction by p53 class mediator. |
| | GO:0016446 | | somatic hypermutation of immunoglobulin genes | | Mutations occurring somatically that result in amino acid changes in the rearranged V regions of immunoglobulins. |
| | GO:0000732 | | strand displacement | | The rejection of the broken 3' single-strand DNA molecule that formed heteroduplex DNA with its complement in an intact duplex DNA. The Watson-Crick base pairing in the original duplex is restored. The rejected 3' single-strand DNA molecule reanneals with its original complement to reform two intact duplex molecules. |
| cellular component |
|---|
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
 Description
Description