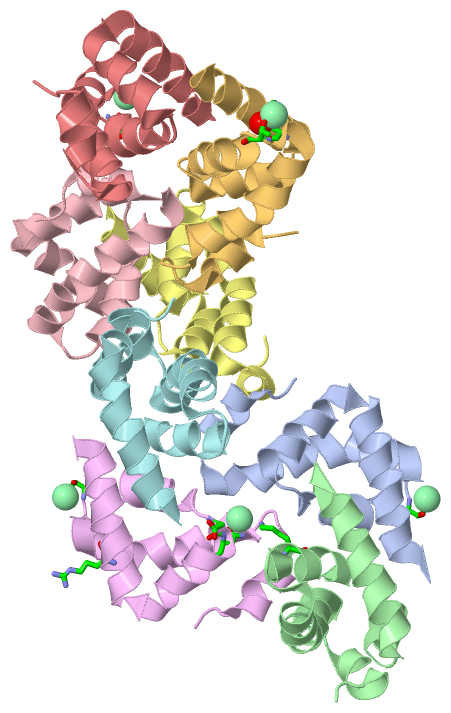
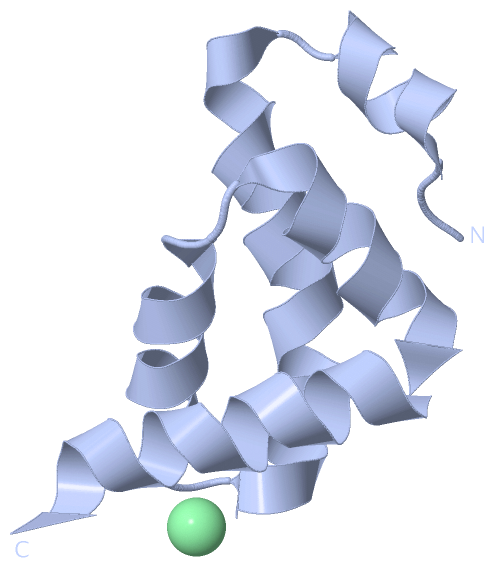
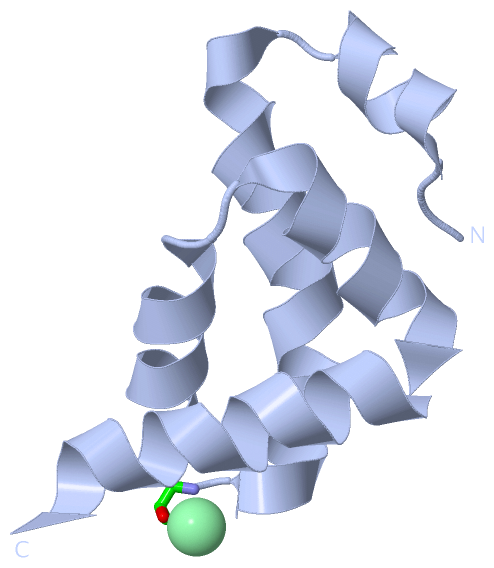
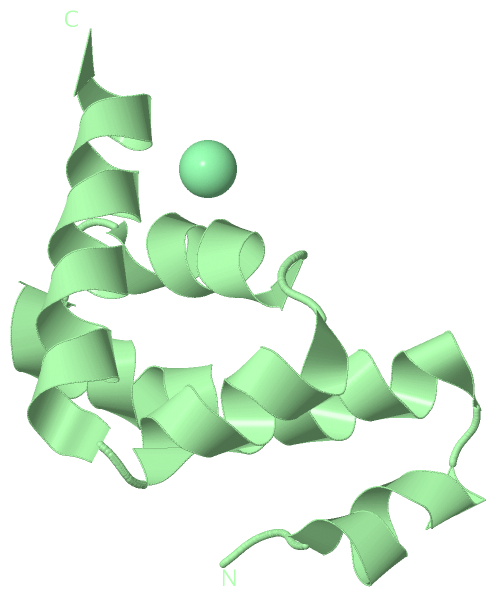
| molecular function |
|---|
| | GO:0003723 | | RNA binding | | Interacting selectively and non-covalently with an RNA molecule or a portion thereof. |
| | GO:0003676 | | nucleic acid binding | | Interacting selectively and non-covalently with any nucleic acid. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| | GO:0008143 | | poly(A) binding | | Interacting selectively and non-covalently with a sequence of adenylyl residues in an RNA molecule, such as the poly(A) tail, a sequence of adenylyl residues at the 3' end of eukaryotic mRNA. |
| | GO:0008266 | | poly(U) RNA binding | | Interacting selectively and non-covalently with a sequence of uracil residues in an RNA molecule. |
| | GO:0008022 | | protein C-terminus binding | | Interacting selectively and non-covalently with a protein C-terminus, the end of any peptide chain at which the 1-carboxy function of a constituent amino acid is not attached in peptide linkage to another amino-acid residue. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0008494 | | translation activator activity | | Any of a group of soluble proteins functioning in the activation of ribosome-mediated translation of mRNA into a polypeptide. |
| biological process |
|---|
| | GO:0008380 | | RNA splicing | | The process of removing sections of the primary RNA transcript to remove sequences not present in the mature form of the RNA and joining the remaining sections to form the mature form of the RNA. |
| | GO:0031047 | | gene silencing by RNA | | Any process in which RNA molecules inactivate expression of target genes. |
| | GO:0006378 | | mRNA polyadenylation | | The enzymatic addition of a sequence of 40-200 adenylyl residues at the 3' end of a eukaryotic mRNA primary transcript. |
| | GO:0006397 | | mRNA processing | | Any process involved in the conversion of a primary mRNA transcript into one or more mature mRNA(s) prior to translation into polypeptide. |
| | GO:0000398 | | mRNA splicing, via spliceosome | | The joining together of exons from one or more primary transcripts of messenger RNA (mRNA) and the excision of intron sequences, via a spliceosomal mechanism, so that mRNA consisting only of the joined exons is produced. |
| | GO:0048255 | | mRNA stabilization | | Prevention of degradation of mRNA molecules. In the absence of compensating changes in other processes, the slowing of mRNA degradation can result in an overall increase in the population of active mRNA molecules. |
| | GO:2000623 | | negative regulation of nuclear-transcribed mRNA catabolic process, nonsense-mediated decay | | Any process that stops, prevents or reduces the frequency, rate or extent of nuclear-transcribed mRNA catabolic process, nonsense-mediated decay. |
| | GO:0000184 | | nuclear-transcribed mRNA catabolic process, nonsense-mediated decay | | The nonsense-mediated decay pathway for nuclear-transcribed mRNAs degrades mRNAs in which an amino-acid codon has changed to a nonsense codon; this prevents the translation of such mRNAs into truncated, and potentially harmful, proteins. |
| | GO:0000289 | | nuclear-transcribed mRNA poly(A) tail shortening | | Shortening of the poly(A) tail of a nuclear-transcribed mRNA from full length to an oligo(A) length. |
| | GO:1900153 | | positive regulation of nuclear-transcribed mRNA catabolic process, deadenylation-dependent decay | | Any process that activates or increases the frequency, rate or extent of nuclear-transcribed mRNA catabolic process, deadenylation-dependent decay. |
| | GO:0060213 | | positive regulation of nuclear-transcribed mRNA poly(A) tail shortening | | Any process that increases the frequency, rate or extent of poly(A) tail shortening of a nuclear-transcribed mRNA. Poly(A) tail shortening is the decrease in length of the poly(A) tail of an mRNA from full length to an oligo(A) length. |
| | GO:0045727 | | positive regulation of translation | | Any process that activates or increases the frequency, rate or extent of the chemical reactions and pathways resulting in the formation of proteins by the translation of mRNA or circRNA. |
| | GO:0045070 | | positive regulation of viral genome replication | | Any process that activates or increases the frequency, rate or extent of viral genome replication. |
| | GO:0043488 | | regulation of mRNA stability | | Any process that modulates the propensity of mRNA molecules to degradation. Includes processes that both stabilize and destabilize mRNAs. |
| | GO:0006413 | | translational initiation | | The process preceding formation of the peptide bond between the first two amino acids of a protein. This includes the formation of a complex of the ribosome, mRNA or circRNA, and an initiation complex that contains the first aminoacyl-tRNA. |
| cellular component |
|---|
| | GO:0071013 | | catalytic step 2 spliceosome | | A spliceosomal complex that contains three snRNPs, including U5, bound to a splicing intermediate in which the first catalytic cleavage of the 5' splice site has occurred. The precise subunit composition differs significantly from that of the catalytic step 1, or activated, spliceosome, and includes many proteins in addition to those found in the associated snRNPs. |
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0036464 | | cytoplasmic ribonucleoprotein granule | | A ribonucleoprotein granule located in the cytoplasm. |
| | GO:0010494 | | cytoplasmic stress granule | | A dense aggregation in the cytosol composed of proteins and RNAs that appear when the cell is under stress. |
| | GO:0005829 | | cytosol | | The part of the cytoplasm that does not contain organelles but which does contain other particulate matter, such as protein complexes. |
| | GO:0070062 | | extracellular exosome | | A vesicle that is released into the extracellular region by fusion of the limiting endosomal membrane of a multivesicular body with the plasma membrane. Extracellular exosomes, also simply called exosomes, have a diameter of about 40-100 nm. |
| | GO:0005925 | | focal adhesion | | Small region on the surface of a cell that anchors the cell to the extracellular matrix and that forms a point of termination of actin filaments. |
| | GO:0030529 | | intracellular ribonucleoprotein complex | | An intracellular macromolecular complex containing both protein and RNA molecules. |
| | GO:0016020 | | membrane | | A lipid bilayer along with all the proteins and protein complexes embedded in it an attached to it. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0005681 | | spliceosomal complex | | Any of a series of ribonucleoprotein complexes that contain snRNA(s) and small nuclear ribonucleoproteins (snRNPs), and are formed sequentially during the spliceosomal splicing of one or more substrate RNAs, and which also contain the RNA substrate(s) from the initial target RNAs of splicing, the splicing intermediate RNA(s), to the final RNA products. During cis-splicing, the initial target RNA is a single, contiguous RNA transcript, whether mRNA, snoRNA, etc., and the released products are a spliced RNA and an excised intron, generally as a lariat structure. During trans-splicing, there are two initial substrate RNAs, the spliced leader RNA and a pre-mRNA. |
 Description
Description