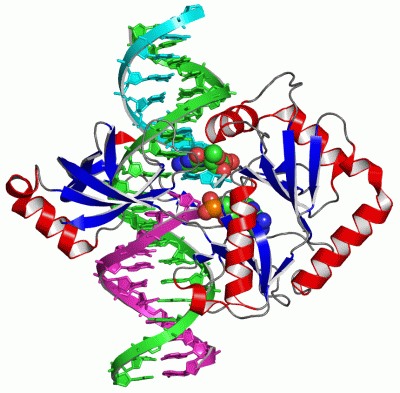
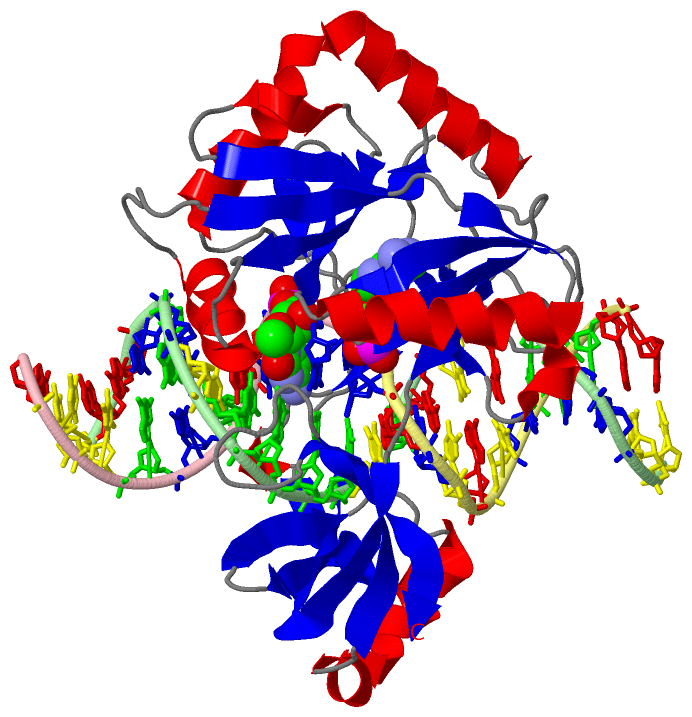
| molecular function |
|---|
| | GO:0005524 | | ATP binding | | Interacting selectively and non-covalently with ATP, adenosine 5'-triphosphate, a universally important coenzyme and enzyme regulator. |
| | GO:0003910 | | DNA ligase (ATP) activity | | Catalysis of the reaction: ATP + deoxyribonucleotide(n) + deoxyribonucleotide(m) = AMP + diphosphate + deoxyribonucleotide(n+m). |
| | GO:0003909 | | DNA ligase activity | | Catalysis of the formation of a phosphodiester bond between the 3'-hydroxyl group at the end of one DNA chain and the 5'-phosphate group at the end of another. This reaction requires an energy source such as ATP or NAD+. |
| | GO:0016874 | | ligase activity | | Catalysis of the joining of two substances, or two groups within a single molecule, with the concomitant hydrolysis of the diphosphate bond in ATP or a similar triphosphate. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| biological process |
|---|
| | GO:0051103 | | DNA ligation involved in DNA repair | | The re-formation of a broken phosphodiester bond in the DNA backbone, carried out by DNA ligase, that contributes to DNA repair. |
| | GO:0006310 | | DNA recombination | | Any process in which a new genotype is formed by reassortment of genes resulting in gene combinations different from those that were present in the parents. In eukaryotes genetic recombination can occur by chromosome assortment, intrachromosomal recombination, or nonreciprocal interchromosomal recombination. Intrachromosomal recombination occurs by crossing over. In bacteria it may occur by genetic transformation, conjugation, transduction, or F-duction. |
| | GO:0006281 | | DNA repair | | The process of restoring DNA after damage. Genomes are subject to damage by chemical and physical agents in the environment (e.g. UV and ionizing radiations, chemical mutagens, fungal and bacterial toxins, etc.) and by free radicals or alkylating agents endogenously generated in metabolism. DNA is also damaged because of errors during its replication. A variety of different DNA repair pathways have been reported that include direct reversal, base excision repair, nucleotide excision repair, photoreactivation, bypass, double-strand break repair pathway, and mismatch repair pathway. |
 Description
Description