| molecular function |
|---|
| | GO:0003723 | | RNA binding | | Interacting selectively and non-covalently with an RNA molecule or a portion thereof. |
| | GO:0003676 | | nucleic acid binding | | Interacting selectively and non-covalently with any nucleic acid. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0003713 | | transcription coactivator activity | | Interacting selectively and non-covalently with a activating transcription factor and also with the basal transcription machinery in order to increase the frequency, rate or extent of transcription. Cofactors generally do not bind the template nucleic acid, but rather mediate protein-protein interactions between activating transcription factors and the basal transcription machinery. |
| biological process |
|---|
| | GO:0008380 | | RNA splicing | | The process of removing sections of the primary RNA transcript to remove sequences not present in the mature form of the RNA and joining the remaining sections to form the mature form of the RNA. |
| | GO:0006397 | | mRNA processing | | Any process involved in the conversion of a primary mRNA transcript into one or more mature mRNA(s) prior to translation into polypeptide. |
| | GO:0006355 | | regulation of transcription, DNA-templated | | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0006351 | | transcription, DNA-templated | | The cellular synthesis of RNA on a template of DNA. |
| cellular component |
|---|
| | GO:0015630 | | microtubule cytoskeleton | | The part of the cytoskeleton (the internal framework of a cell) composed of microtubules and associated proteins. |
| | GO:0005815 | | microtubule organizing center | | An intracellular structure that can catalyze gamma-tubulin-dependent microtubule nucleation and that can anchor microtubules by interacting with their minus ends, plus ends or sides. |
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
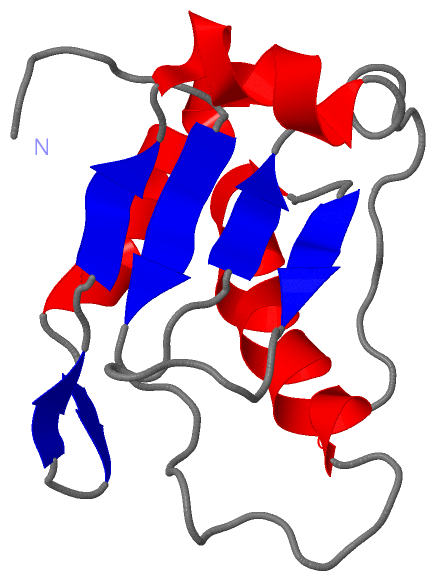
 Description
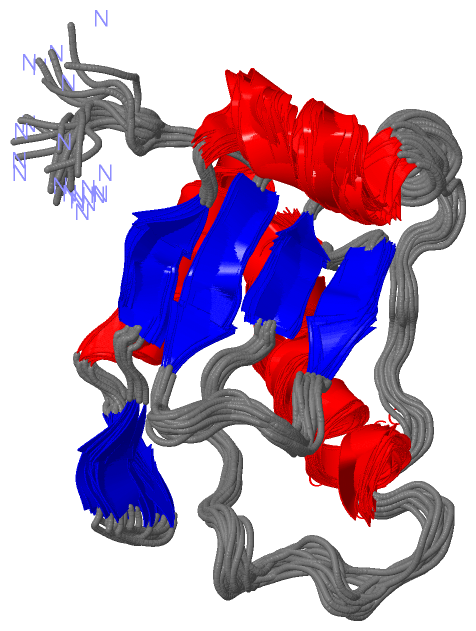
Description