| molecular function |
|---|
| | GO:0008047 | | enzyme activator activity | | Binds to and increases the activity of an enzyme. |
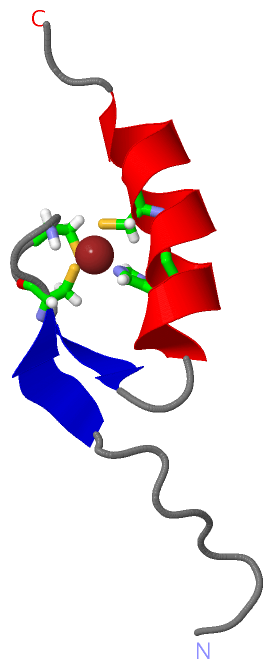
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0003713 | | transcription coactivator activity | | Interacting selectively and non-covalently with a activating transcription factor and also with the basal transcription machinery in order to increase the frequency, rate or extent of transcription. Cofactors generally do not bind the template nucleic acid, but rather mediate protein-protein interactions between activating transcription factors and the basal transcription machinery. |
| | GO:0008270 | | zinc ion binding | | Interacting selectively and non-covalently with zinc (Zn) ions. |
| biological process |
|---|
| | GO:0016578 | | histone deubiquitination | | The modification of histones by removal of ubiquitin groups. |
| | GO:0043085 | | positive regulation of catalytic activity | | Any process that activates or increases the activity of an enzyme. |
| | GO:0045893 | | positive regulation of transcription, DNA-templated | | Any process that activates or increases the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0006357 | | regulation of transcription from RNA polymerase II promoter | | Any process that modulates the frequency, rate or extent of transcription from an RNA polymerase II promoter. |
| | GO:0006355 | | regulation of transcription, DNA-templated | | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0006351 | | transcription, DNA-templated | | The cellular synthesis of RNA on a template of DNA. |
| cellular component |
|---|
| | GO:0071819 | | DUBm complex | | A protein complex that forms part of SAGA-type complexes SAGA and SLIK, and mediates deubiquitination of histone H2B. In S. cerevisiae, the DUBm consists of the proteins Ubp8p, Sgf11p, Sus1p, and Sgf73p. |
| | GO:0000124 | | SAGA complex | | A SAGA-type histone acetyltransferase complex that contains Spt8 (in budding yeast) or a homolog thereof; additional polypeptides include Spt group, consisting of Spt7, Spt3, and Spt20/Ada5, which interact with the TATA-binding protein (TBP); the Ada group, consisting of Ada1, Ada2, Ada3, Ada4/Gcn5, and Ada5/Spt20, which is functionally linked to the nucleosomal HAT activity; Tra1, an ATM/PI-3 kinase-related protein that targets DNA-bound activators for recruitment to promoters; the TBP-associated factor (TAF) proteins, consisting of Taf5, Taf6, Taf9, Taf10, and Taf12, which mediate nucleosomal HAT activity and are thought to help recruit the basal transcription machinery; the ubiquitin specifc protease Ubp-8. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
 Description
Description