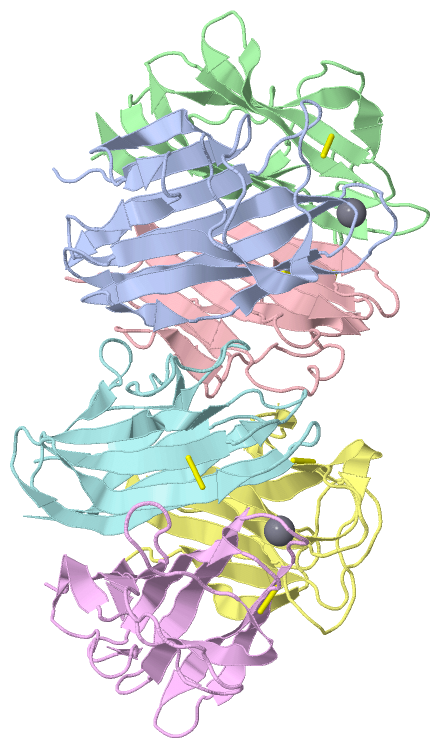
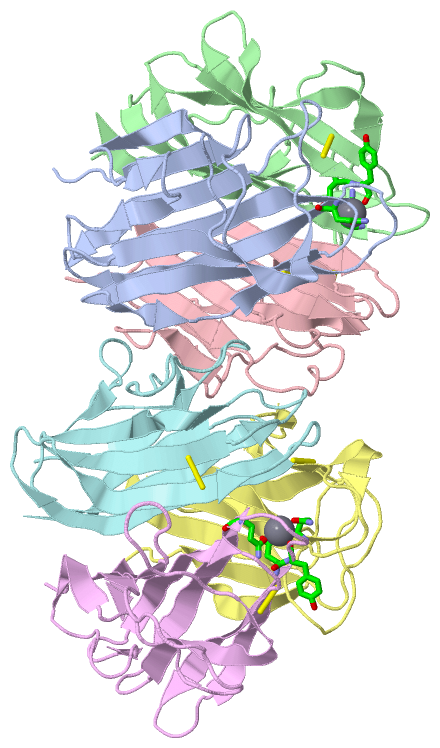
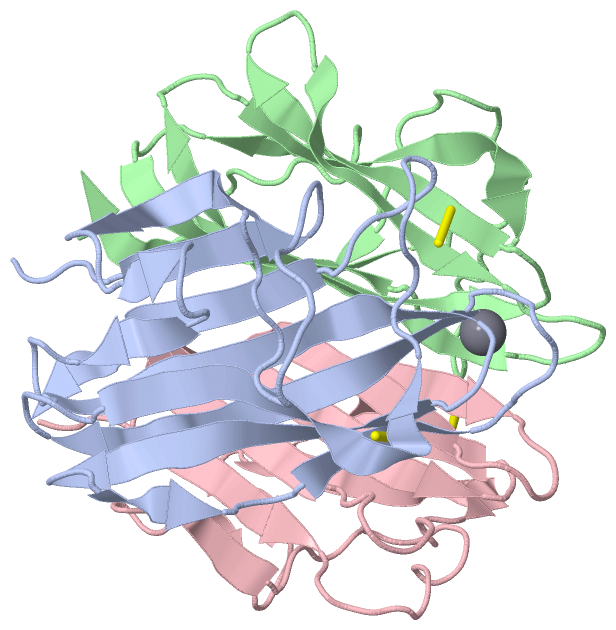
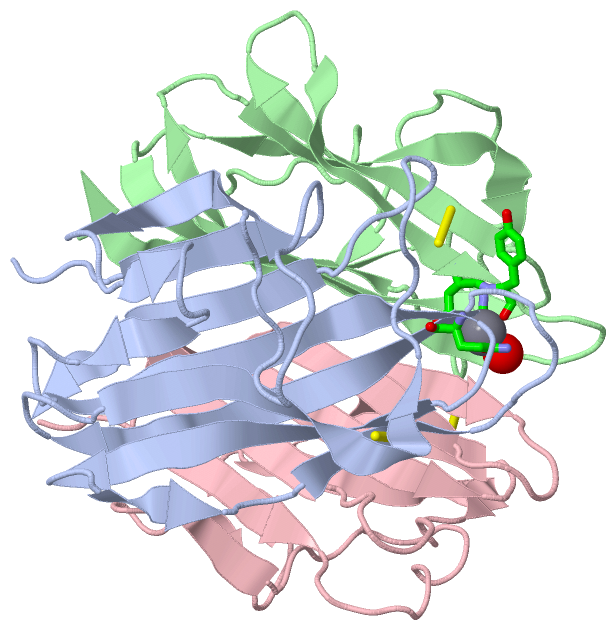
Asymmetric Unit(hide GO term definitions)
Chain A,D ( C1QA_HUMAN | P02745)
| molecular function |
|---|
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0004252 | | serine-type endopeptidase activity | | Catalysis of the hydrolysis of internal, alpha-peptide bonds in a polypeptide chain by a catalytic mechanism that involves a catalytic triad consisting of a serine nucleophile that is activated by a proton relay involving an acidic residue (e.g. aspartate or glutamate) and a basic residue (usually histidine). |
| biological process |
|---|
| | GO:0007267 | | cell-cell signaling | | Any process that mediates the transfer of information from one cell to another. This process includes signal transduction in the receiving cell and, where applicable, release of a ligand and any processes that actively facilitate its transport and presentation to the receiving cell. Examples include signaling via soluble ligands, via cell adhesion molecules and via gap junctions. |
| | GO:0006956 | | complement activation | | Any process involved in the activation of any of the steps of the complement cascade, which allows for the direct killing of microbes, the disposal of immune complexes, and the regulation of other immune processes; the initial steps of complement activation involve one of three pathways, the classical pathway, the alternative pathway, and the lectin pathway, all of which lead to the terminal complement pathway. |
| | GO:0006958 | | complement activation, classical pathway | | Any process involved in the activation of any of the steps of the classical pathway of the complement cascade which allows for the direct killing of microbes, the disposal of immune complexes, and the regulation of other immune processes. |
| | GO:0002376 | | immune system process | | Any process involved in the development or functioning of the immune system, an organismal system for calibrated responses to potential internal or invasive threats. |
| | GO:0045087 | | innate immune response | | Innate immune responses are defense responses mediated by germline encoded components that directly recognize components of potential pathogens. |
| | GO:0006508 | | proteolysis | | The hydrolysis of proteins into smaller polypeptides and/or amino acids by cleavage of their peptide bonds. |
| | GO:0010039 | | response to iron ion | | Any process that results in a change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of an iron ion stimulus. |
| cellular component |
|---|
| | GO:0005581 | | collagen trimer | | A protein complex consisting of three collagen chains assembled into a left-handed triple helix. These trimers typically assemble into higher order structures. |
| | GO:0005602 | | complement component C1 complex | | A protein complex composed of six subunits of C1q, each formed of the three homologous polypeptide chains C1QA, C1QB, and C1QB, and tetramer of two C1QR and two C1QS polypeptide chains. |
| | GO:0070062 | | extracellular exosome | | A vesicle that is released into the extracellular region by fusion of the limiting endosomal membrane of a multivesicular body with the plasma membrane. Extracellular exosomes, also simply called exosomes, have a diameter of about 40-100 nm. |
| | GO:0005576 | | extracellular region | | The space external to the outermost structure of a cell. For cells without external protective or external encapsulating structures this refers to space outside of the plasma membrane. This term covers the host cell environment outside an intracellular parasite. |
Chain B,E ( C1QB_HUMAN | P02746)
| molecular function |
|---|
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0042803 | | protein homodimerization activity | | Interacting selectively and non-covalently with an identical protein to form a homodimer. |
| | GO:0004252 | | serine-type endopeptidase activity | | Catalysis of the hydrolysis of internal, alpha-peptide bonds in a polypeptide chain by a catalytic mechanism that involves a catalytic triad consisting of a serine nucleophile that is activated by a proton relay involving an acidic residue (e.g. aspartate or glutamate) and a basic residue (usually histidine). |
| biological process |
|---|
| | GO:0006956 | | complement activation | | Any process involved in the activation of any of the steps of the complement cascade, which allows for the direct killing of microbes, the disposal of immune complexes, and the regulation of other immune processes; the initial steps of complement activation involve one of three pathways, the classical pathway, the alternative pathway, and the lectin pathway, all of which lead to the terminal complement pathway. |
| | GO:0006958 | | complement activation, classical pathway | | Any process involved in the activation of any of the steps of the classical pathway of the complement cascade which allows for the direct killing of microbes, the disposal of immune complexes, and the regulation of other immune processes. |
| | GO:0002376 | | immune system process | | Any process involved in the development or functioning of the immune system, an organismal system for calibrated responses to potential internal or invasive threats. |
| | GO:0045087 | | innate immune response | | Innate immune responses are defense responses mediated by germline encoded components that directly recognize components of potential pathogens. |
| | GO:0048839 | | inner ear development | | The process whose specific outcome is the progression of the inner ear over time, from its formation to the mature structure. |
| | GO:0006508 | | proteolysis | | The hydrolysis of proteins into smaller polypeptides and/or amino acids by cleavage of their peptide bonds. |
| cellular component |
|---|
| | GO:0072562 | | blood microparticle | | A phospholipid microvesicle that is derived from any of several cell types, such as platelets, blood cells, endothelial cells, or others, and contains membrane receptors as well as other proteins characteristic of the parental cell. Microparticles are heterogeneous in size, and are characterized as microvesicles free of nucleic acids. |
| | GO:0005581 | | collagen trimer | | A protein complex consisting of three collagen chains assembled into a left-handed triple helix. These trimers typically assemble into higher order structures. |
| | GO:0005602 | | complement component C1 complex | | A protein complex composed of six subunits of C1q, each formed of the three homologous polypeptide chains C1QA, C1QB, and C1QB, and tetramer of two C1QR and two C1QS polypeptide chains. |
| | GO:0070062 | | extracellular exosome | | A vesicle that is released into the extracellular region by fusion of the limiting endosomal membrane of a multivesicular body with the plasma membrane. Extracellular exosomes, also simply called exosomes, have a diameter of about 40-100 nm. |
| | GO:0005576 | | extracellular region | | The space external to the outermost structure of a cell. For cells without external protective or external encapsulating structures this refers to space outside of the plasma membrane. This term covers the host cell environment outside an intracellular parasite. |
Chain C,F ( C1QC_HUMAN | P02747)
| molecular function |
|---|
| | GO:0004252 | | serine-type endopeptidase activity | | Catalysis of the hydrolysis of internal, alpha-peptide bonds in a polypeptide chain by a catalytic mechanism that involves a catalytic triad consisting of a serine nucleophile that is activated by a proton relay involving an acidic residue (e.g. aspartate or glutamate) and a basic residue (usually histidine). |
| biological process |
|---|
| | GO:0006956 | | complement activation | | Any process involved in the activation of any of the steps of the complement cascade, which allows for the direct killing of microbes, the disposal of immune complexes, and the regulation of other immune processes; the initial steps of complement activation involve one of three pathways, the classical pathway, the alternative pathway, and the lectin pathway, all of which lead to the terminal complement pathway. |
| | GO:0006958 | | complement activation, classical pathway | | Any process involved in the activation of any of the steps of the classical pathway of the complement cascade which allows for the direct killing of microbes, the disposal of immune complexes, and the regulation of other immune processes. |
| | GO:0006955 | | immune response | | Any immune system process that functions in the calibrated response of an organism to a potential internal or invasive threat. |
| | GO:0002376 | | immune system process | | Any process involved in the development or functioning of the immune system, an organismal system for calibrated responses to potential internal or invasive threats. |
| | GO:0045087 | | innate immune response | | Innate immune responses are defense responses mediated by germline encoded components that directly recognize components of potential pathogens. |
| | GO:0030853 | | negative regulation of granulocyte differentiation | | Any process that stops, prevents, or reduces the frequency, rate or extent of granulocyte differentiation. |
| | GO:0045650 | | negative regulation of macrophage differentiation | | Any process that stops, prevents, or reduces the frequency, rate or extent of macrophage differentiation. |
| | GO:0006508 | | proteolysis | | The hydrolysis of proteins into smaller polypeptides and/or amino acids by cleavage of their peptide bonds. |
| cellular component |
|---|
| | GO:0072562 | | blood microparticle | | A phospholipid microvesicle that is derived from any of several cell types, such as platelets, blood cells, endothelial cells, or others, and contains membrane receptors as well as other proteins characteristic of the parental cell. Microparticles are heterogeneous in size, and are characterized as microvesicles free of nucleic acids. |
| | GO:0005581 | | collagen trimer | | A protein complex consisting of three collagen chains assembled into a left-handed triple helix. These trimers typically assemble into higher order structures. |
| | GO:0070062 | | extracellular exosome | | A vesicle that is released into the extracellular region by fusion of the limiting endosomal membrane of a multivesicular body with the plasma membrane. Extracellular exosomes, also simply called exosomes, have a diameter of about 40-100 nm. |
| | GO:0005576 | | extracellular region | | The space external to the outermost structure of a cell. For cells without external protective or external encapsulating structures this refers to space outside of the plasma membrane. This term covers the host cell environment outside an intracellular parasite. |
| | GO:0005615 | | extracellular space | | That part of a multicellular organism outside the cells proper, usually taken to be outside the plasma membranes, and occupied by fluid. |
|
 Description
Description