| molecular function |
|---|
| | GO:0005524 | | ATP binding | | Interacting selectively and non-covalently with ATP, adenosine 5'-triphosphate, a universally important coenzyme and enzyme regulator. |
| | GO:0019788 | | NEDD8 transferase activity | | Catalysis of the transfer of NEDD8 from one protein to another via the reaction X-NEDD8 + Y --> Y-NEDD8 + X, where both X-NEDD8 and Y-NEDD8 are covalent linkages. |
| | GO:0016874 | | ligase activity | | Catalysis of the joining of two substances, or two groups within a single molecule, with the concomitant hydrolysis of the diphosphate bond in ATP or a similar triphosphate. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0061630 | | ubiquitin protein ligase activity | | Catalysis of the transfer of ubiquitin to a substrate protein via the reaction X-ubiquitin + S -> X + S-ubiquitin, where X is either an E2 or E3 enzyme, the X-ubiquitin linkage is a thioester bond, and the S-ubiquitin linkage is an amide bond: an isopeptide bond between the C-terminal glycine of ubiquitin and the epsilon-amino group of lysine residues in the substrate or, in the linear extension of ubiquitin chains, a peptide bond the between the C-terminal glycine and N-terminal methionine of ubiquitin residues. |
| | GO:0031625 | | ubiquitin protein ligase binding | | Interacting selectively and non-covalently with a ubiquitin protein ligase enzyme, any of the E3 proteins. |
| biological process |
|---|
| | GO:0006301 | | postreplication repair | | The conversion of DNA-damage induced single-stranded gaps into large molecular weight DNA after replication. Includes pathways that remove replication-blocking lesions in conjunction with DNA replication. |
| | GO:0070534 | | protein K63-linked ubiquitination | | A protein ubiquitination process in which a polymer of ubiquitin, formed by linkages between lysine residues at position 63 of the ubiquitin monomers, is added to a protein. K63-linked ubiquitination does not target the substrate protein for degradation, but is involved in several pathways, notably as a signal to promote error-free DNA postreplication repair. |
| | GO:0045116 | | protein neddylation | | Covalent attachment of the ubiquitin-like protein NEDD8 (RUB1) to another protein. |
| cellular component |
|---|
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
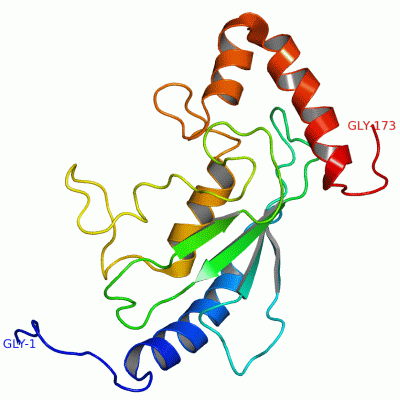
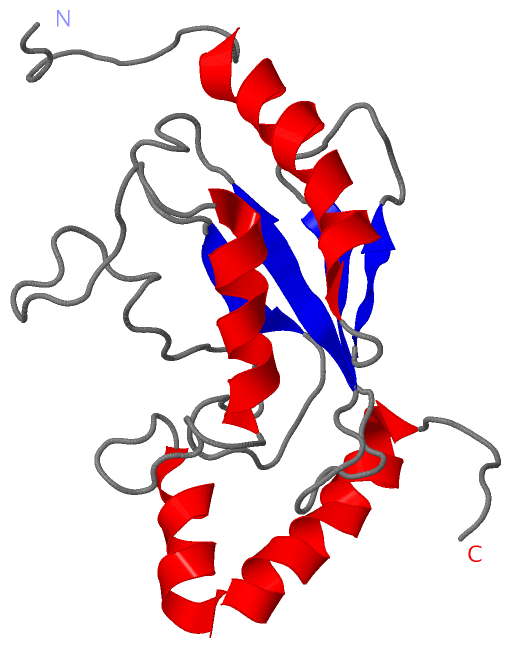
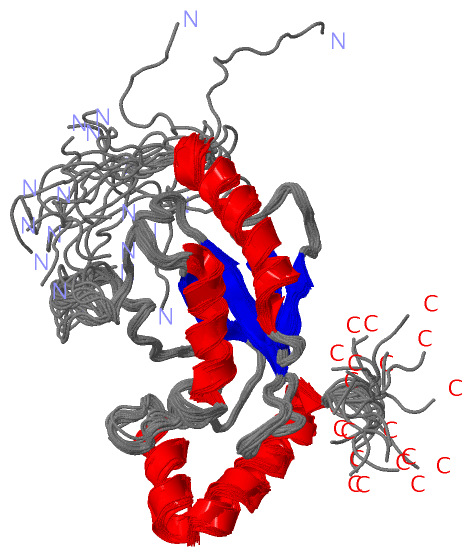
 Description
Description