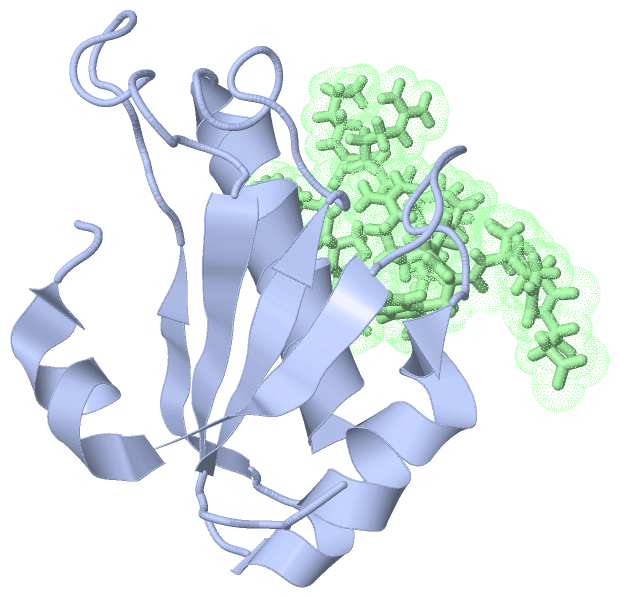
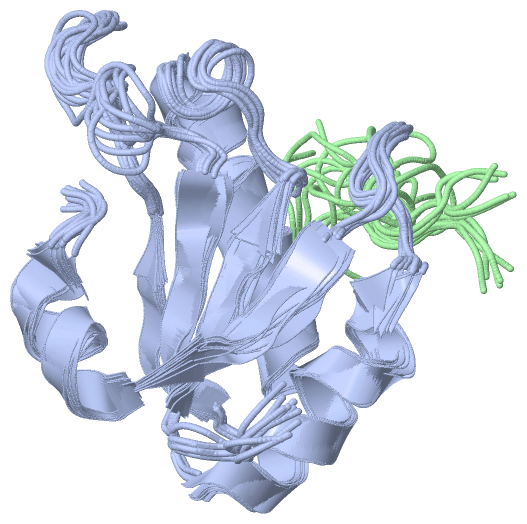
NMR Structure(hide GO term definitions)
Chain A ( U2AF2_HUMAN | P26368)
| molecular function |
|---|
| | GO:0003723 | | RNA binding | | Interacting selectively and non-covalently with an RNA molecule or a portion thereof. |
| | GO:0019899 | | enzyme binding | | Interacting selectively and non-covalently with any enzyme. |
| | GO:0003676 | | nucleic acid binding | | Interacting selectively and non-covalently with any nucleic acid. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| | GO:0008187 | | poly-pyrimidine tract binding | | Interacting selectively and non-covalently with any stretch of pyrimidines (cytosine or uracil) in an RNA molecule. |
| | GO:0030628 | | pre-mRNA 3'-splice site binding | | Interacting selectively and non-covalently with the pre-mRNA 3' splice site sequence. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| biological process |
|---|
| | GO:0006405 | | RNA export from nucleus | | The directed movement of RNA from the nucleus to the cytoplasm. |
| | GO:0008380 | | RNA splicing | | The process of removing sections of the primary RNA transcript to remove sequences not present in the mature form of the RNA and joining the remaining sections to form the mature form of the RNA. |
| | GO:0031124 | | mRNA 3'-end processing | | Any process involved in forming the mature 3' end of an mRNA molecule. |
| | GO:0006406 | | mRNA export from nucleus | | The directed movement of mRNA from the nucleus to the cytoplasm. |
| | GO:0006397 | | mRNA processing | | Any process involved in the conversion of a primary mRNA transcript into one or more mature mRNA(s) prior to translation into polypeptide. |
| | GO:0000398 | | mRNA splicing, via spliceosome | | The joining together of exons from one or more primary transcripts of messenger RNA (mRNA) and the excision of intron sequences, via a spliceosomal mechanism, so that mRNA consisting only of the joined exons is produced. |
| | GO:0048025 | | negative regulation of mRNA splicing, via spliceosome | | Any process that stops, prevents or reduces the rate or extent of mRNA splicing via a spliceosomal mechanism. |
| | GO:0033120 | | positive regulation of RNA splicing | | Any process that activates or increases the frequency, rate or extent of RNA splicing. |
| | GO:1903955 | | positive regulation of protein targeting to mitochondrion | | Any process that activates or increases the frequency, rate or extent of protein targeting to mitochondrion. |
| | GO:1903146 | | regulation of mitophagy | | Any process that modulates the frequency, rate or extent of mitochondrion degradation (mitophagy). |
| | GO:0006369 | | termination of RNA polymerase II transcription | | The process in which the synthesis of an RNA molecule by RNA polymerase II using a DNA template is completed. |
| cellular component |
|---|
| | GO:0000974 | | Prp19 complex | | A protein complex consisting of Prp19 and associated proteins that is involved in the transition from the precatalytic spliceosome to the activated form that catalyzes step 1 of splicing, and which remains associated with the spliceosome through the second catalytic step. It is widely conserved, found in both yeast and mammals, though the exact composition varies. In S. cerevisiae, it contains Prp19p, Ntc20p, Snt309p, Isy1p, Syf2p, Cwc2p, Prp46p, Clf1p, Cef1p, and Syf1p. |
| | GO:0071004 | | U2-type prespliceosome | | A spliceosomal complex that is formed by association of the 5' splice site with the U1 snRNP, while the branch point sequence is recognized by the U2 snRNP. The prespliceosome includes many proteins in addition to those found in the U1 and U2 snRNPs. Commitment to a given pair of 5' and 3' splice sites occurs at the time of prespliceosome formation. |
| | GO:0089701 | | U2AF | | A heterodimeric protein complex consisting of conserved large and small U2AF subunits that contributes to spliceosomal RNA splicing by binding to consensus sequences at the 3' splice site. U2AF is required to stabilize the association of the U2 snRNP with the branch point. |
| | GO:0000243 | | commitment complex | | A spliceosomal complex that is formed by association of the U1 snRNP with the 5' splice site of an unspliced intron in an RNA transcript. |
| | GO:0016607 | | nuclear speck | | A discrete extra-nucleolar subnuclear domain, 20-50 in number, in which splicing factors are seen to be localized by immunofluorescence microscopy. |
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0005681 | | spliceosomal complex | | Any of a series of ribonucleoprotein complexes that contain snRNA(s) and small nuclear ribonucleoproteins (snRNPs), and are formed sequentially during the spliceosomal splicing of one or more substrate RNAs, and which also contain the RNA substrate(s) from the initial target RNAs of splicing, the splicing intermediate RNA(s), to the final RNA products. During cis-splicing, the initial target RNA is a single, contiguous RNA transcript, whether mRNA, snoRNA, etc., and the released products are a spliced RNA and an excised intron, generally as a lariat structure. During trans-splicing, there are two initial substrate RNAs, the spliced leader RNA and a pre-mRNA. |
Chain B ( SF01_HUMAN | Q15637)
| molecular function |
|---|
| | GO:0003723 | | RNA binding | | Interacting selectively and non-covalently with an RNA molecule or a portion thereof. |
| | GO:0042802 | | identical protein binding | | Interacting selectively and non-covalently with an identical protein or proteins. |
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0003676 | | nucleic acid binding | | Interacting selectively and non-covalently with any nucleic acid. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0003714 | | transcription corepressor activity | | Interacting selectively and non-covalently with a repressing transcription factor and also with the basal transcription machinery in order to stop, prevent, or reduce the frequency, rate or extent of transcription. Cofactors generally do not bind the template nucleic acid, but rather mediate protein-protein interactions between repressive transcription factors and the basal transcription machinery. |
| | GO:0008270 | | zinc ion binding | | Interacting selectively and non-covalently with zinc (Zn) ions. |
| biological process |
|---|
| | GO:0033327 | | Leydig cell differentiation | | The process in which a relatively unspecialized cell acquires specialized structural and/or functional features of a Leydig cell. A Leydig cell is a testosterone-secreting cell in the interstitial area, between the seminiferous tubules, in the testis. |
| | GO:0008380 | | RNA splicing | | The process of removing sections of the primary RNA transcript to remove sequences not present in the mature form of the RNA and joining the remaining sections to form the mature form of the RNA. |
| | GO:0000389 | | mRNA 3'-splice site recognition | | Recognition of the intron 3'-splice site by components of the assembling U2- or U12-type spliceosome. |
| | GO:0006397 | | mRNA processing | | Any process involved in the conversion of a primary mRNA transcript into one or more mature mRNA(s) prior to translation into polypeptide. |
| | GO:0000398 | | mRNA splicing, via spliceosome | | The joining together of exons from one or more primary transcripts of messenger RNA (mRNA) and the excision of intron sequences, via a spliceosomal mechanism, so that mRNA consisting only of the joined exons is produced. |
| | GO:0030238 | | male sex determination | | The specification of male sex of an individual organism. |
| | GO:1903507 | | negative regulation of nucleic acid-templated transcription | | Any process that stops, prevents or reduces the frequency, rate or extent of nucleic acid-templated transcription. |
| | GO:0048662 | | negative regulation of smooth muscle cell proliferation | | Any process that stops, prevents or reduces the rate or extent of smooth muscle cell proliferation. |
| | GO:0050810 | | regulation of steroid biosynthetic process | | Any process that modulates the frequency, rate or extent of the chemical reactions and pathways resulting in the formation of steroids, compounds with a 1,2,cyclopentanoperhydrophenanthrene nucleus. |
| | GO:0006355 | | regulation of transcription, DNA-templated | | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0000245 | | spliceosomal complex assembly | | The aggregation, arrangement and bonding together of a spliceosomal complex, a ribonucleoprotein apparatus that catalyzes nuclear mRNA splicing via transesterification reactions. |
| | GO:0006351 | | transcription, DNA-templated | | The cellular synthesis of RNA on a template of DNA. |
| cellular component |
|---|
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0005840 | | ribosome | | An intracellular organelle, about 200 A in diameter, consisting of RNA and protein. It is the site of protein biosynthesis resulting from translation of messenger RNA (mRNA). It consists of two subunits, one large and one small, each containing only protein and RNA. Both the ribosome and its subunits are characterized by their sedimentation coefficients, expressed in Svedberg units (symbol: S). Hence, the prokaryotic ribosome (70S) comprises a large (50S) subunit and a small (30S) subunit, while the eukaryotic ribosome (80S) comprises a large (60S) subunit and a small (40S) subunit. Two sites on the ribosomal large subunit are involved in translation, namely the aminoacyl site (A site) and peptidyl site (P site). Ribosomes from prokaryotes, eukaryotes, mitochondria, and chloroplasts have characteristically distinct ribosomal proteins. |
| | GO:0005681 | | spliceosomal complex | | Any of a series of ribonucleoprotein complexes that contain snRNA(s) and small nuclear ribonucleoproteins (snRNPs), and are formed sequentially during the spliceosomal splicing of one or more substrate RNAs, and which also contain the RNA substrate(s) from the initial target RNAs of splicing, the splicing intermediate RNA(s), to the final RNA products. During cis-splicing, the initial target RNA is a single, contiguous RNA transcript, whether mRNA, snoRNA, etc., and the released products are a spliced RNA and an excised intron, generally as a lariat structure. During trans-splicing, there are two initial substrate RNAs, the spliced leader RNA and a pre-mRNA. |
|
 Description
Description