| molecular function |
|---|
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0030337 | | DNA polymerase processivity factor activity | | An enzyme regulator activity that increases the processivity of polymerization by DNA polymerase, by allowing the polymerase to move rapidly along DNA while remaining topologically bound to it. |
| | GO:0042802 | | identical protein binding | | Interacting selectively and non-covalently with an identical protein or proteins. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| biological process |
|---|
| | GO:0006281 | | DNA repair | | The process of restoring DNA after damage. Genomes are subject to damage by chemical and physical agents in the environment (e.g. UV and ionizing radiations, chemical mutagens, fungal and bacterial toxins, etc.) and by free radicals or alkylating agents endogenously generated in metabolism. DNA is also damaged because of errors during its replication. A variety of different DNA repair pathways have been reported that include direct reversal, base excision repair, nucleotide excision repair, photoreactivation, bypass, double-strand break repair pathway, and mismatch repair pathway. |
| | GO:0006260 | | DNA replication | | The cellular metabolic process in which a cell duplicates one or more molecules of DNA. DNA replication begins when specific sequences, known as origins of replication, are recognized and bound by initiation proteins, and ends when the original DNA molecule has been completely duplicated and the copies topologically separated. The unit of replication usually corresponds to the genome of the cell, an organelle, or a virus. The template for replication can either be an existing DNA molecule or RNA. |
| | GO:0006974 | | cellular response to DNA damage stimulus | | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus indicating damage to its DNA from environmental insults or errors during metabolism. |
| | GO:0030466 | | chromatin silencing at silent mating-type cassette | | Repression of transcription at silent mating-type loci by alteration of the structure of chromatin. |
| | GO:0006348 | | chromatin silencing at telomere | | Repression of transcription of telomeric DNA by altering the structure of chromatin. |
| | GO:0070987 | | error-free translesion synthesis | | The conversion of DNA-damage induced single-stranded gaps into large molecular weight DNA after replication by using a specialized DNA polymerase or replication complex to insert a defined nucleotide across the lesion. This process does not remove the replication-blocking lesions but does not causes an increase in the endogenous mutation level. For S. cerevisiae, RAD30 encodes DNA polymerase eta, which incorporates two adenines. When incorporated across a thymine-thymine dimer, it does not increase the endogenous mutation level. |
| | GO:0034087 | | establishment of mitotic sister chromatid cohesion | | The process in which the sister chromatids of a replicated chromosome become joined along the entire length of the chromosome during S phase during a mitotic cell cycle. |
| | GO:0006273 | | lagging strand elongation | | The synthesis of DNA from a template strand in a net 3' to 5' direction. Lagging strand DNA elongation proceeds by discontinuous synthesis of short stretches of DNA, known as Okazaki fragments, from RNA primers; these fragments are then joined by DNA ligase. Although each segment of nascent DNA is synthesized in the 5' to 3' direction, the overall direction of lagging strand synthesis is 3' to 5', mirroring the progress of the replication fork. |
| | GO:0006272 | | leading strand elongation | | The synthesis of DNA from a template strand in the 5' to 3' direction; leading strand elongation is continuous as it proceeds in the same direction as the replication fork. |
| | GO:0035753 | | maintenance of DNA trinucleotide repeats | | Any process involved in sustaining the fidelity and copy number of DNA trinucleotide repeats. DNA trinucleotide repeats are naturally occurring runs of three base-pairs. |
| | GO:0000710 | | meiotic mismatch repair | | A system for the identification and correction of base-base mismatches, small insertion-deletion loops, and regions of heterology that are present in duplex DNA formed with strands from two recombining molecules. Correction of the mismatch can result in non-Mendelian segregation of alleles following meiosis. |
| | GO:0006298 | | mismatch repair | | A system for the correction of errors in which an incorrect base, which cannot form hydrogen bonds with the corresponding base in the parent strand, is incorporated into the daughter strand. The mismatch repair system promotes genomic fidelity by repairing base-base mismatches, insertion-deletion loops and heterologies generated during DNA replication and recombination. |
| | GO:0000278 | | mitotic cell cycle | | Progression through the phases of the mitotic cell cycle, the most common eukaryotic cell cycle, which canonically comprises four successive phases called G1, S, G2, and M and includes replication of the genome and the subsequent segregation of chromosomes into daughter cells. In some variant cell cycles nuclear replication or nuclear division may not be followed by cell division, or G1 and G2 phases may be absent. |
| | GO:0007064 | | mitotic sister chromatid cohesion | | The cell cycle process in which the sister chromatids of a replicated chromosome are joined along the entire length of the chromosome, from their formation in S phase through metaphase during a mitotic cell cycle. This cohesion cycle is critical for high fidelity chromosome transmission. |
| | GO:0006289 | | nucleotide-excision repair | | A DNA repair process in which a small region of the strand surrounding the damage is removed from the DNA helix as an oligonucleotide. The small gap left in the DNA helix is filled in by the sequential action of DNA polymerase and DNA ligase. Nucleotide excision repair recognizes a wide range of substrates, including damage caused by UV irradiation (pyrimidine dimers and 6-4 photoproducts) and chemicals (intrastrand cross-links and bulky adducts). |
| | GO:1902394 | | positive regulation of exodeoxyribonuclease activity | | Any process that activates or increases the frequency, rate or extent of exodeoxyribonuclease activity. |
| | GO:1903022 | | positive regulation of phosphodiesterase activity, acting on 3'-phosphoglycolate-terminated DNA strands | | Any process that activates or increases the frequency, rate or extent of phosphodiesterase activity, acting on 3'-phosphoglycolate-terminated DNA strands. |
| | GO:0006301 | | postreplication repair | | The conversion of DNA-damage induced single-stranded gaps into large molecular weight DNA after replication. Includes pathways that remove replication-blocking lesions in conjunction with DNA replication. |
| | GO:0006275 | | regulation of DNA replication | | Any process that modulates the frequency, rate or extent of DNA replication. |
| cellular component |
|---|
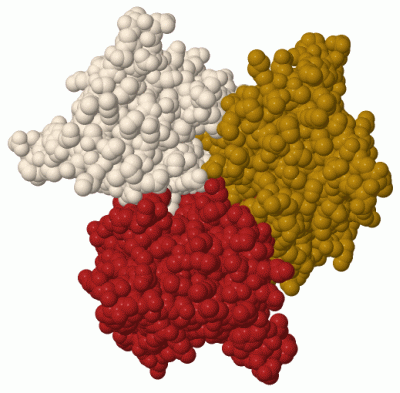
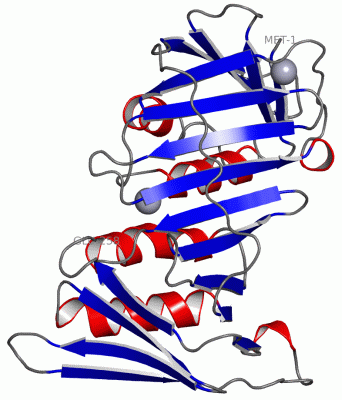
| | GO:0043626 | | PCNA complex | | A protein complex composed of three identical PCNA monomers, each comprising two similar domains, which are joined in a head-to-tail arrangement to form a homotrimer. Forms a ring-like structure in solution, with a central hole sufficiently large to accommodate the double helix of DNA. Originally characterized as a DNA sliding clamp for replicative DNA polymerases and as an essential component of the replisome, and has also been shown to be involved in other processes including Okazaki fragment processing, DNA repair, translesion DNA synthesis, DNA methylation, chromatin remodeling and cell cycle regulation. |
| | GO:0000781 | | chromosome, telomeric region | | The terminal region of a linear chromosome that includes the telomeric DNA repeats and associated proteins. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0005657 | | replication fork | | The Y-shaped region of a replicating DNA molecule, resulting from the separation of the DNA strands and in which the synthesis of new strands takes place. Also includes associated protein complexes. |
 Description
Description