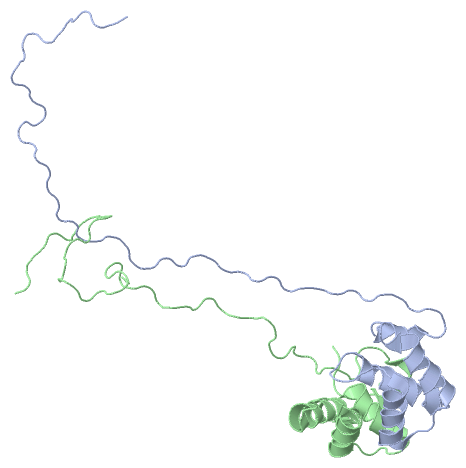
NMR Structure(hide GO term definitions)
Chain A ( RLA1_HUMAN | P05386)
| molecular function |
|---|
| | GO:0070180 | | large ribosomal subunit rRNA binding | | Interacting selectively and non-covalently with the large ribosomal subunit RNA (LSU rRNA), a constituent of the large ribosomal subunit. In S. cerevisiae, this is the 25S rRNA. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0030295 | | protein kinase activator activity | | Binds to and increases the activity of a protein kinase, an enzyme which phosphorylates a protein. |
| | GO:0003735 | | structural constituent of ribosome | | The action of a molecule that contributes to the structural integrity of the ribosome. |
| biological process |
|---|
| | GO:0006614 | | SRP-dependent cotranslational protein targeting to membrane | | The targeting of proteins to a membrane that occurs during translation and is dependent upon two key components, the signal-recognition particle (SRP) and the SRP receptor. SRP is a cytosolic particle that transiently binds to the endoplasmic reticulum (ER) signal sequence in a nascent protein, to the large ribosomal unit, and to the SRP receptor in the ER membrane. |
| | GO:0032147 | | activation of protein kinase activity | | Any process that initiates the activity of an inactive protein kinase. |
| | GO:0002181 | | cytoplasmic translation | | The chemical reactions and pathways resulting in the formation of a protein in the cytoplasm. This is a ribosome-mediated process in which the information in messenger RNA (mRNA) is used to specify the sequence of amino acids in the protein. |
| | GO:0000184 | | nuclear-transcribed mRNA catabolic process, nonsense-mediated decay | | The nonsense-mediated decay pathway for nuclear-transcribed mRNAs degrades mRNAs in which an amino-acid codon has changed to a nonsense codon; this prevents the translation of such mRNAs into truncated, and potentially harmful, proteins. |
| | GO:0045860 | | positive regulation of protein kinase activity | | Any process that activates or increases the frequency, rate or extent of protein kinase activity. |
| | GO:0006364 | | rRNA processing | | Any process involved in the conversion of a primary ribosomal RNA (rRNA) transcript into one or more mature rRNA molecules. |
| | GO:0006412 | | translation | | The cellular metabolic process in which a protein is formed, using the sequence of a mature mRNA or circRNA molecule to specify the sequence of amino acids in a polypeptide chain. Translation is mediated by the ribosome, and begins with the formation of a ternary complex between aminoacylated initiator methionine tRNA, GTP, and initiation factor 2, which subsequently associates with the small subunit of the ribosome and an mRNA or circRNA. Translation ends with the release of a polypeptide chain from the ribosome. |
| | GO:0006414 | | translational elongation | | The successive addition of amino acid residues to a nascent polypeptide chain during protein biosynthesis. |
| | GO:0006413 | | translational initiation | | The process preceding formation of the peptide bond between the first two amino acids of a protein. This includes the formation of a complex of the ribosome, mRNA or circRNA, and an initiation complex that contains the first aminoacyl-tRNA. |
| | GO:0019083 | | viral transcription | | The process by which a viral genome, or part of a viral genome, is transcribed within the host cell. |
| cellular component |
|---|
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0005829 | | cytosol | | The part of the cytoplasm that does not contain organelles but which does contain other particulate matter, such as protein complexes. |
| | GO:0022625 | | cytosolic large ribosomal subunit | | The large subunit of a ribosome located in the cytosol. |
| | GO:0070062 | | extracellular exosome | | A vesicle that is released into the extracellular region by fusion of the limiting endosomal membrane of a multivesicular body with the plasma membrane. Extracellular exosomes, also simply called exosomes, have a diameter of about 40-100 nm. |
| | GO:0005925 | | focal adhesion | | Small region on the surface of a cell that anchors the cell to the extracellular matrix and that forms a point of termination of actin filaments. |
| | GO:0005622 | | intracellular | | The living contents of a cell; the matter contained within (but not including) the plasma membrane, usually taken to exclude large vacuoles and masses of secretory or ingested material. In eukaryotes it includes the nucleus and cytoplasm. |
| | GO:0030529 | | intracellular ribonucleoprotein complex | | An intracellular macromolecular complex containing both protein and RNA molecules. |
| | GO:0030687 | | preribosome, large subunit precursor | | A preribosomal complex consisting of 27SA, 27SB, and/or 7S pre-rRNA, 5S rRNA, ribosomal proteins including late-associating large subunit proteins, and associated proteins; a precursor of the eukaryotic cytoplasmic large ribosomal subunit. |
| | GO:0005840 | | ribosome | | An intracellular organelle, about 200 A in diameter, consisting of RNA and protein. It is the site of protein biosynthesis resulting from translation of messenger RNA (mRNA). It consists of two subunits, one large and one small, each containing only protein and RNA. Both the ribosome and its subunits are characterized by their sedimentation coefficients, expressed in Svedberg units (symbol: S). Hence, the prokaryotic ribosome (70S) comprises a large (50S) subunit and a small (30S) subunit, while the eukaryotic ribosome (80S) comprises a large (60S) subunit and a small (40S) subunit. Two sites on the ribosomal large subunit are involved in translation, namely the aminoacyl site (A site) and peptidyl site (P site). Ribosomes from prokaryotes, eukaryotes, mitochondria, and chloroplasts have characteristically distinct ribosomal proteins. |
Chain B ( RLA2_HUMAN | P05387)
| molecular function |
|---|
| | GO:0070180 | | large ribosomal subunit rRNA binding | | Interacting selectively and non-covalently with the large ribosomal subunit RNA (LSU rRNA), a constituent of the large ribosomal subunit. In S. cerevisiae, this is the 25S rRNA. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0003735 | | structural constituent of ribosome | | The action of a molecule that contributes to the structural integrity of the ribosome. |
| biological process |
|---|
| | GO:0006614 | | SRP-dependent cotranslational protein targeting to membrane | | The targeting of proteins to a membrane that occurs during translation and is dependent upon two key components, the signal-recognition particle (SRP) and the SRP receptor. SRP is a cytosolic particle that transiently binds to the endoplasmic reticulum (ER) signal sequence in a nascent protein, to the large ribosomal unit, and to the SRP receptor in the ER membrane. |
| | GO:0002181 | | cytoplasmic translation | | The chemical reactions and pathways resulting in the formation of a protein in the cytoplasm. This is a ribosome-mediated process in which the information in messenger RNA (mRNA) is used to specify the sequence of amino acids in the protein. |
| | GO:0000184 | | nuclear-transcribed mRNA catabolic process, nonsense-mediated decay | | The nonsense-mediated decay pathway for nuclear-transcribed mRNAs degrades mRNAs in which an amino-acid codon has changed to a nonsense codon; this prevents the translation of such mRNAs into truncated, and potentially harmful, proteins. |
| | GO:0006364 | | rRNA processing | | Any process involved in the conversion of a primary ribosomal RNA (rRNA) transcript into one or more mature rRNA molecules. |
| | GO:0006412 | | translation | | The cellular metabolic process in which a protein is formed, using the sequence of a mature mRNA or circRNA molecule to specify the sequence of amino acids in a polypeptide chain. Translation is mediated by the ribosome, and begins with the formation of a ternary complex between aminoacylated initiator methionine tRNA, GTP, and initiation factor 2, which subsequently associates with the small subunit of the ribosome and an mRNA or circRNA. Translation ends with the release of a polypeptide chain from the ribosome. |
| | GO:0006414 | | translational elongation | | The successive addition of amino acid residues to a nascent polypeptide chain during protein biosynthesis. |
| | GO:0006413 | | translational initiation | | The process preceding formation of the peptide bond between the first two amino acids of a protein. This includes the formation of a complex of the ribosome, mRNA or circRNA, and an initiation complex that contains the first aminoacyl-tRNA. |
| | GO:0019083 | | viral transcription | | The process by which a viral genome, or part of a viral genome, is transcribed within the host cell. |
| cellular component |
|---|
| | GO:0005829 | | cytosol | | The part of the cytoplasm that does not contain organelles but which does contain other particulate matter, such as protein complexes. |
| | GO:0022625 | | cytosolic large ribosomal subunit | | The large subunit of a ribosome located in the cytosol. |
| | GO:0070062 | | extracellular exosome | | A vesicle that is released into the extracellular region by fusion of the limiting endosomal membrane of a multivesicular body with the plasma membrane. Extracellular exosomes, also simply called exosomes, have a diameter of about 40-100 nm. |
| | GO:0005925 | | focal adhesion | | Small region on the surface of a cell that anchors the cell to the extracellular matrix and that forms a point of termination of actin filaments. |
| | GO:0005622 | | intracellular | | The living contents of a cell; the matter contained within (but not including) the plasma membrane, usually taken to exclude large vacuoles and masses of secretory or ingested material. In eukaryotes it includes the nucleus and cytoplasm. |
| | GO:0030529 | | intracellular ribonucleoprotein complex | | An intracellular macromolecular complex containing both protein and RNA molecules. |
| | GO:0016020 | | membrane | | A lipid bilayer along with all the proteins and protein complexes embedded in it an attached to it. |
| | GO:0030687 | | preribosome, large subunit precursor | | A preribosomal complex consisting of 27SA, 27SB, and/or 7S pre-rRNA, 5S rRNA, ribosomal proteins including late-associating large subunit proteins, and associated proteins; a precursor of the eukaryotic cytoplasmic large ribosomal subunit. |
| | GO:0005840 | | ribosome | | An intracellular organelle, about 200 A in diameter, consisting of RNA and protein. It is the site of protein biosynthesis resulting from translation of messenger RNA (mRNA). It consists of two subunits, one large and one small, each containing only protein and RNA. Both the ribosome and its subunits are characterized by their sedimentation coefficients, expressed in Svedberg units (symbol: S). Hence, the prokaryotic ribosome (70S) comprises a large (50S) subunit and a small (30S) subunit, while the eukaryotic ribosome (80S) comprises a large (60S) subunit and a small (40S) subunit. Two sites on the ribosomal large subunit are involved in translation, namely the aminoacyl site (A site) and peptidyl site (P site). Ribosomes from prokaryotes, eukaryotes, mitochondria, and chloroplasts have characteristically distinct ribosomal proteins. |
|
 Description
Description