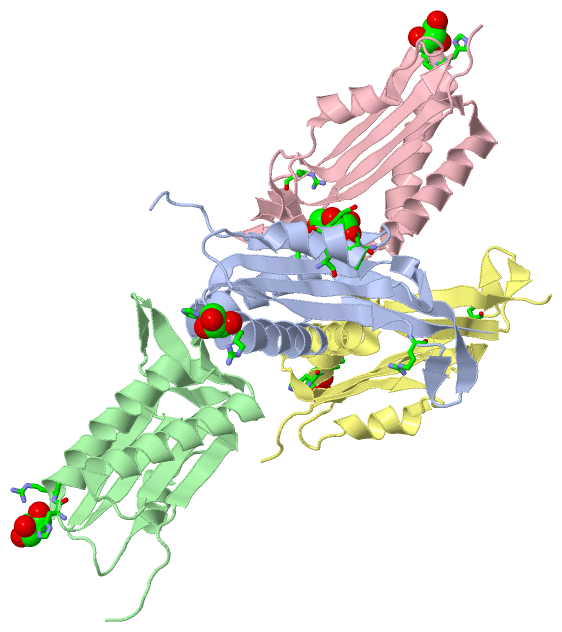
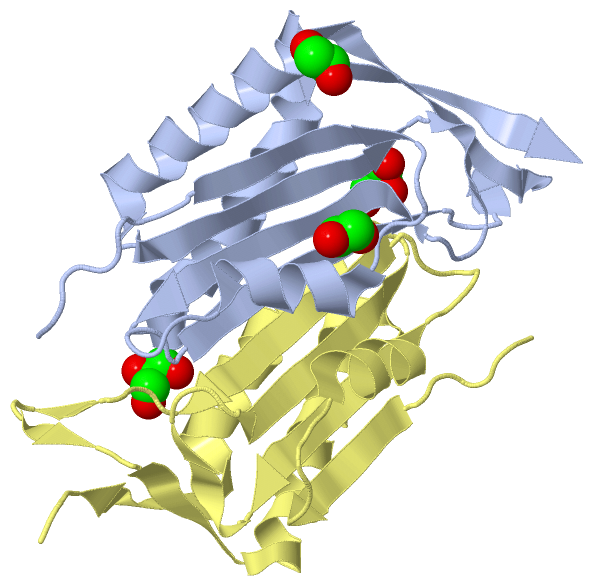
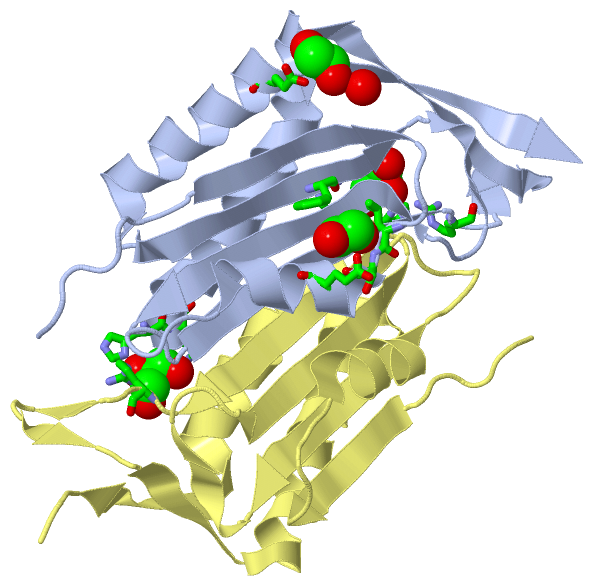
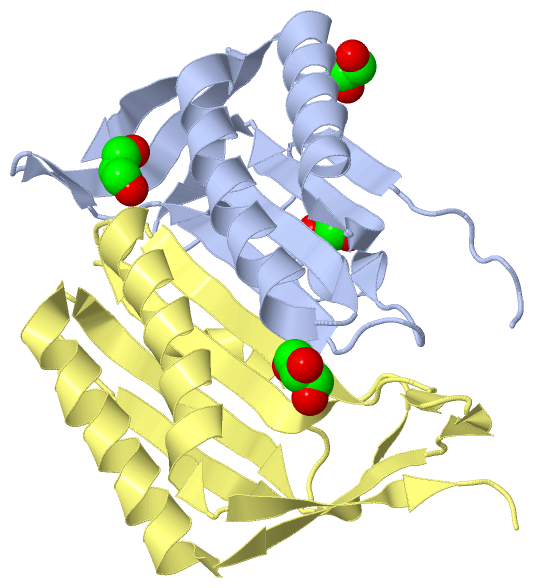
|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (2, 6)| Asymmetric Unit (2, 6) Biological Unit 1 (2, 3) Biological Unit 2 (1, 1) Biological Unit 3 (1, 1) Biological Unit 4 (1, 1) |
Sites (6, 6)
Asymmetric Unit (6, 6)
|
SS Bonds (0, 0)| (no "SS Bond" information available for 4AP8) |
Cis Peptide Bonds (3, 3)
Asymmetric Unit
|
||||||||||||||||
SAPs(SNPs)/Variants (4, 16)
Asymmetric Unit (4, 16)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 4AP8) |
Exons (0, 0)| (no "Exon" information available for 4AP8) |
Sequences/Alignments
Asymmetric UnitChain A from PDB Type:PROTEIN Length:134 aligned with MOC2B_HUMAN | O96007 from UniProtKB/Swiss-Prot Length:188 Alignment length:134 47 57 67 77 87 97 107 117 127 137 147 157 167 MOC2B_HUMAN 38 EVEEKSKDVINFTAEKLSVDEVSQLVISPLCGAISLFVGTTRNNFEGKKVISLEYEAYLPMAENEVRKICSDIRQKWPVKHIAVFHRLGLVPVSEASIIIAVSSAHRAASLEAVSYAIDTLKAKVPIWKKEIYE 171 SCOP domains d4ap8a_ A: automated matches SCOP domains CATH domains -------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains -------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ------------A--------------------------A---------------------------------------------Y--------------------------------------------K--- SAPs(SNPs) PROSITE -------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript -------------------------------------------------------------------------------------------------------------------------------------- Transcript 4ap8 A 38 EVEEKSKDVINFTAEKLSVDEVSQLVISPLCGAISLFVGTTRNNFEGKKVISLEYEAYLPMAENEVRKICSDIRQKWPVKHIAVFHRLGLVPVSEASIIIAVSSAHRAASLEAVSYAIDTLKAKVPIWKKEIYE 171 47 57 67 77 87 97 107 117 127 137 147 157 167 Chain B from PDB Type:PROTEIN Length:134 aligned with MOC2B_HUMAN | O96007 from UniProtKB/Swiss-Prot Length:188 Alignment length:134 47 57 67 77 87 97 107 117 127 137 147 157 167 MOC2B_HUMAN 38 EVEEKSKDVINFTAEKLSVDEVSQLVISPLCGAISLFVGTTRNNFEGKKVISLEYEAYLPMAENEVRKICSDIRQKWPVKHIAVFHRLGLVPVSEASIIIAVSSAHRAASLEAVSYAIDTLKAKVPIWKKEIYE 171 SCOP domains d4ap8b_ B: automated matches SCOP domains CATH domains -------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains -------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ------------A--------------------------A---------------------------------------------Y--------------------------------------------K--- SAPs(SNPs) PROSITE -------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript -------------------------------------------------------------------------------------------------------------------------------------- Transcript 4ap8 B 38 EVEEKSKDVINFTAEKLSVDEVSQLVISPLCGAISLFVGTTRNNFEGKKVISLEYEAYLPMAENEVRKICSDIRQKWPVKHIAVFHRLGLVPVSEASIIIAVSSAHRAASLEAVSYAIDTLKAKVPIWKKEIYE 171 47 57 67 77 87 97 107 117 127 137 147 157 167 Chain C from PDB Type:PROTEIN Length:134 aligned with MOC2B_HUMAN | O96007 from UniProtKB/Swiss-Prot Length:188 Alignment length:134 47 57 67 77 87 97 107 117 127 137 147 157 167 MOC2B_HUMAN 38 EVEEKSKDVINFTAEKLSVDEVSQLVISPLCGAISLFVGTTRNNFEGKKVISLEYEAYLPMAENEVRKICSDIRQKWPVKHIAVFHRLGLVPVSEASIIIAVSSAHRAASLEAVSYAIDTLKAKVPIWKKEIYE 171 SCOP domains d4ap8c_ C: automated matches SCOP domains CATH domains -------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains -------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ------------A--------------------------A---------------------------------------------Y--------------------------------------------K--- SAPs(SNPs) PROSITE -------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript -------------------------------------------------------------------------------------------------------------------------------------- Transcript 4ap8 C 38 EVEEKSKDVINFTAEKLSVDEVSQLVISPLCGAISLFVGTTRNNFEGKKVISLEYEAYLPMAENEVRKICSDIRQKWPVKHIAVFHRLGLVPVSEASIIIAVSSAHRAASLEAVSYAIDTLKAKVPIWKKEIYE 171 47 57 67 77 87 97 107 117 127 137 147 157 167 Chain D from PDB Type:PROTEIN Length:133 aligned with MOC2B_HUMAN | O96007 from UniProtKB/Swiss-Prot Length:188 Alignment length:133 49 59 69 79 89 99 109 119 129 139 149 159 169 MOC2B_HUMAN 40 EEKSKDVINFTAEKLSVDEVSQLVISPLCGAISLFVGTTRNNFEGKKVISLEYEAYLPMAENEVRKICSDIRQKWPVKHIAVFHRLGLVPVSEASIIIAVSSAHRAASLEAVSYAIDTLKAKVPIWKKEIYEE 172 SCOP domains d4ap8d_ D: automated matches SCOP domains CATH domains ------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains ------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ----------A--------------------------A---------------------------------------------Y--------------------------------------------K---- SAPs(SNPs) PROSITE ------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ------------------------------------------------------------------------------------------------------------------------------------- Transcript 4ap8 D 40 EEKSKDVINFTAEKLSVDEVSQLVISPLCGAISLFVGTTRNNFEGKKVISLEYEAYLPMAENEVRKICSDIRQKWPVKHIAVFHRLGLVPVSEASIIIAVSSAHRAASLEAVSYAIDTLKAKVPIWKKEIYEE 172 49 59 69 79 89 99 109 119 129 139 149 159 169
|
||||||||||||||||||||
SCOP Domains (1, 4)
Asymmetric Unit
 |
CATH Domains (0, 0)| (no "CATH Domain" information available for 4AP8) |
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 4AP8) |
Gene Ontology (8, 8)|
Asymmetric Unit(hide GO term definitions) Chain A,B,C,D (MOC2B_HUMAN | O96007)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|