|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (0, 0)| (no "Ligand,Modified Residues,Ions" information available for 4DQ8) |
Sites (0, 0)| (no "Site" information available for 4DQ8) |
SS Bonds (0, 0)| (no "SS Bond" information available for 4DQ8) |
Cis Peptide Bonds (0, 0)| (no "Cis Peptide Bond" information available for 4DQ8) |
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 4DQ8) |
PROSITE Motifs (2, 4)
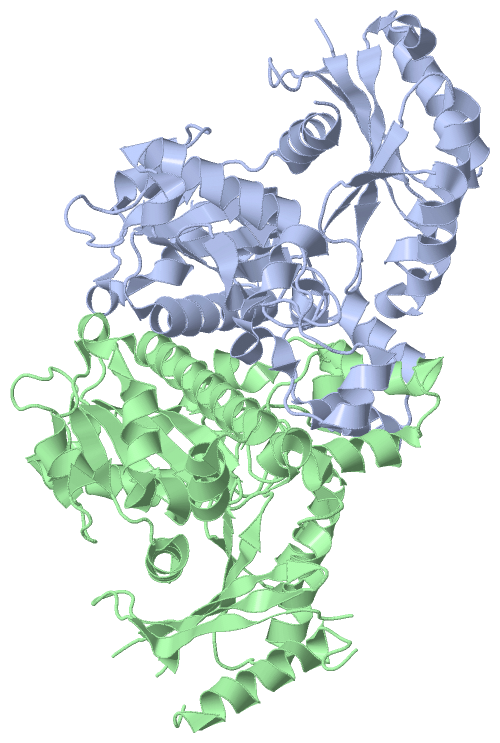
Asymmetric/Biological Unit (2, 4)
|
||||||||||||||||||||||||||||||||
Exons (0, 0)| (no "Exon" information available for 4DQ8) |
Sequences/Alignments
Asymmetric/Biological UnitChain A from PDB Type:PROTEIN Length:373 aligned with ACKA_MYCMM | B2HPZ3 from UniProtKB/Swiss-Prot Length:388 Alignment length:380 16 26 36 46 56 66 76 86 96 106 116 126 136 146 156 166 176 186 196 206 216 226 236 246 256 266 276 286 296 306 316 326 336 346 356 366 376 386 ACKA_MYCMM 7 NRVVLVLNSGSSSLKFQLVEPDSGMSRATGNIERIGEESSSVPDHDAALRRVFEILAEDDIDLQSCGLVAVGHRVVHGGKDFYEPTLLNDAVIGKLDELSPLAPLHNPPAVLCIRVARALLPDVPHIAVFDTAFFHQLPPAAATYAIDRELADVWKIRRYGFHGTSHEYVSQQAAEFLGKPIGDLNQIVLHLGNGASASAVAGGRPVETSMGLTPLEGLVMGTRSGDLDPGVIGYLWRTAKLGVDEIESMLNHRSGMLGLAGERDFRRLRAMIDDGDPAAELAYDVFIHRLRKYVGAYLAVLGHTDVVSFTAGIGEHDAAVRRDTLAGMAELGISLDERRNACPSGGARRISADDSPVTVLVIPTNEELAIARHCCSVLV 386 SCOP domains d4dq8a1 A:7-186 automated matches d4dq8a2 A:187-386 automated matches SCOP domains CATH domains -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ---ACETATE_KINA---------------------------------------------------------------------------------------------------------------------------------------------------------------------------ACETATE_KINASE_2 -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 4dq8 A 7 NRVVLVLNSGSSSLKFQLVEPDSGMSRATGNIERI-------PDHDAALRRVFEILAEDDIDLQSCGLVAVGHRVVHGGKDFYEPTLLNDAVIGKLDELSPLAPLHNPPAVLCIRVARALLPDVPHIAVFDTAFFHQLPPAAATYAIDRELADVWKIRRYGFHGTSHEYVSQQAAEFLGKPIGDLNQIVLHLGNGASASAVAGGRPVETSMGLTPLEGLVMGTRSGDLDPGVIGYLWRTAKLGVDEIESMLNHRSGMLGLAGERDFRRLRAMIDDGDPAAELAYDVFIHRLRKYVGAYLAVLGHTDVVSFTAGIGEHDAAVRRDTLAGMAELGISLDERRNACPSGGARRISADDSPVTVLVIPTNEELAIARHCCSVLV 386 16 26 36 | - | 56 66 76 86 96 106 116 126 136 146 156 166 176 186 196 206 216 226 236 246 256 266 276 286 296 306 316 326 336 346 356 366 376 386 41 49 Chain B from PDB Type:PROTEIN Length:371 aligned with ACKA_MYCMM | B2HPZ3 from UniProtKB/Swiss-Prot Length:388 Alignment length:379 16 26 36 46 56 66 76 86 96 106 116 126 136 146 156 166 176 186 196 206 216 226 236 246 256 266 276 286 296 306 316 326 336 346 356 366 376 ACKA_MYCMM 7 NRVVLVLNSGSSSLKFQLVEPDSGMSRATGNIERIGEESSSVPDHDAALRRVFEILAEDDIDLQSCGLVAVGHRVVHGGKDFYEPTLLNDAVIGKLDELSPLAPLHNPPAVLCIRVARALLPDVPHIAVFDTAFFHQLPPAAATYAIDRELADVWKIRRYGFHGTSHEYVSQQAAEFLGKPIGDLNQIVLHLGNGASASAVAGGRPVETSMGLTPLEGLVMGTRSGDLDPGVIGYLWRTAKLGVDEIESMLNHRSGMLGLAGERDFRRLRAMIDDGDPAAELAYDVFIHRLRKYVGAYLAVLGHTDVVSFTAGIGEHDAAVRRDTLAGMAELGISLDERRNACPSGGARRISADDSPVTVLVIPTNEELAIARHCCSVL 385 SCOP domains d4dq8b1 B:7-186 automated matches d4dq8b2 B:187-385 automated matches SCOP domains CATH domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ---ACETATE_KINA---------------------------------------------------------------------------------------------------------------------------------------------------------------------------ACETATE_KINASE_2 ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 4dq8 B 7 NRVVLVLNSGSSSLKFQLVEPDSGMSRATGNIERIG---SSVPDHDAALRRVFEILAEDDI-----GLVAVGHRVVHGGKDFYEPTLLNDAVIGKLDELSPLAPLHNPPAVLCIRVARALLPDVPHIAVFDTAFFHQLPPAAATYAIDRELADVWKIRRYGFHGTSHEYVSQQAAEFLGKPIGDLNQIVLHLGNGASASAVAGGRPVETSMGLTPLEGLVMGTRSGDLDPGVIGYLWRTAKLGVDEIESMLNHRSGMLGLAGERDFRRLRAMIDDGDPAAELAYDVFIHRLRKYVGAYLAVLGHTDVVSFTAGIGEHDAAVRRDTLAGMAELGISLDERRNACPSGGARRISADDSPVTVLVIPTNEELAIARHCCSVL 385 16 26 36 | 46 56 66| | 76 86 96 106 116 126 136 146 156 166 176 186 196 206 216 226 236 246 256 266 276 286 296 306 316 326 336 346 356 366 376 42 46 67 73
|
||||||||||||||||||||
SCOP Domains (1, 4)
Asymmetric/Biological Unit
 |
CATH Domains (0, 0)| (no "CATH Domain" information available for 4DQ8) |
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 4DQ8) |
Gene Ontology (14, 14)|
Asymmetric/Biological Unit(hide GO term definitions) Chain A,B (ACKA_MYCMM | B2HPZ3)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|