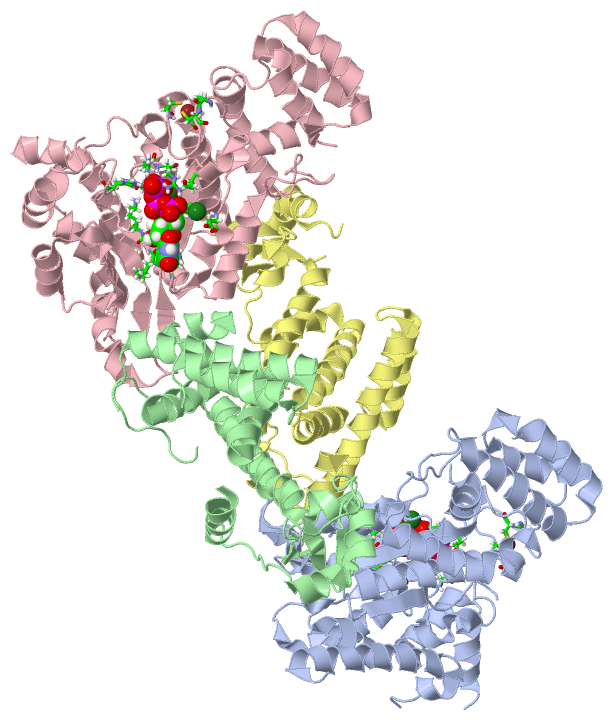
Asymmetric Unit(hide GO term definitions)
Chain A,C ( PRI1_HUMAN | P49642)
| molecular function |
|---|
| | GO:0003896 | | DNA primase activity | | Catalysis of the synthesis of a short RNA primer on a DNA template, providing a free 3'-OH that can be extended by DNA-directed DNA polymerases. |
| | GO:0003899 | | DNA-directed 5'-3' RNA polymerase activity | | Catalysis of the reaction: nucleoside triphosphate + RNA(n) = diphosphate + RNA(n+1). Utilizes a DNA template, i.e. the catalysis of DNA-template-directed extension of the 3'-end of an RNA strand by one nucleotide at a time. Can initiate a chain 'de novo'. |
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0016779 | | nucleotidyltransferase activity | | Catalysis of the transfer of a nucleotidyl group to a reactant. |
| | GO:0016740 | | transferase activity | | Catalysis of the transfer of a group, e.g. a methyl group, glycosyl group, acyl group, phosphorus-containing, or other groups, from one compound (generally regarded as the donor) to another compound (generally regarded as the acceptor). Transferase is the systematic name for any enzyme of EC class 2. |
| biological process |
|---|
| | GO:0006260 | | DNA replication | | The cellular metabolic process in which a cell duplicates one or more molecules of DNA. DNA replication begins when specific sequences, known as origins of replication, are recognized and bound by initiation proteins, and ends when the original DNA molecule has been completely duplicated and the copies topologically separated. The unit of replication usually corresponds to the genome of the cell, an organelle, or a virus. The template for replication can either be an existing DNA molecule or RNA. |
| | GO:0006270 | | DNA replication initiation | | The process in which DNA-dependent DNA replication is started; this involves the separation of a stretch of the DNA double helix, the recruitment of DNA polymerases and the initiation of polymerase action. |
| | GO:0006269 | | DNA replication, synthesis of RNA primer | | The synthesis of a short RNA polymer, usually 4-15 nucleotides long, using one strand of unwound DNA as a template; the RNA then serves as a primer from which DNA polymerases extend synthesis. |
| | GO:0006271 | | DNA strand elongation involved in DNA replication | | The process in which a DNA strand is synthesized from template DNA during replication by the action of polymerases, which add nucleotides to the 3' end of the nascent DNA strand. |
| | GO:0000082 | | G1/S transition of mitotic cell cycle | | The mitotic cell cycle transition by which a cell in G1 commits to S phase. The process begins with the build up of G1 cyclin-dependent kinase (G1 CDK), resulting in the activation of transcription of G1 cyclins. The process ends with the positive feedback of the G1 cyclins on the G1 CDK which commits the cell to S phase, in which DNA replication is initiated. |
| | GO:0000722 | | telomere maintenance via recombination | | Any recombinational process that contributes to the maintenance of proper telomeric length. |
| cellular component |
|---|
| | GO:0016020 | | membrane | | A lipid bilayer along with all the proteins and protein complexes embedded in it an attached to it. |
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:1990077 | | primosome complex | | Any of a family of protein complexes that form at the origin of replication or stalled replication forks and function in replication primer synthesis in all organisms. Early complexes initiate double-stranded DNA unwinding. The core unit consists of a replicative helicase and a primase. The helicase further unwinds the DNA and recruits the polymerase machinery. The primase synthesizes RNA primers that act as templates for complementary stand replication by the polymerase machinery. The primosome contains a number of associated proteins and protein complexes and contributes to the processes of replication initiation, lagging strand elongation, and replication restart. |
Chain B,D ( PRI2_HUMAN | P49643)
| molecular function |
|---|
| | GO:0051539 | | 4 iron, 4 sulfur cluster binding | | Interacting selectively and non-covalently with a 4 iron, 4 sulfur (4Fe-4S) cluster; this cluster consists of four iron atoms, with the inorganic sulfur atoms found between the irons and acting as bridging ligands. |
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0003896 | | DNA primase activity | | Catalysis of the synthesis of a short RNA primer on a DNA template, providing a free 3'-OH that can be extended by DNA-directed DNA polymerases. |
| | GO:0003899 | | DNA-directed 5'-3' RNA polymerase activity | | Catalysis of the reaction: nucleoside triphosphate + RNA(n) = diphosphate + RNA(n+1). Utilizes a DNA template, i.e. the catalysis of DNA-template-directed extension of the 3'-end of an RNA strand by one nucleotide at a time. Can initiate a chain 'de novo'. |
| | GO:0051536 | | iron-sulfur cluster binding | | Interacting selectively and non-covalently with an iron-sulfur cluster, a combination of iron and sulfur atoms. |
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0016779 | | nucleotidyltransferase activity | | Catalysis of the transfer of a nucleotidyl group to a reactant. |
| | GO:0016740 | | transferase activity | | Catalysis of the transfer of a group, e.g. a methyl group, glycosyl group, acyl group, phosphorus-containing, or other groups, from one compound (generally regarded as the donor) to another compound (generally regarded as the acceptor). Transferase is the systematic name for any enzyme of EC class 2. |
| biological process |
|---|
| | GO:0006260 | | DNA replication | | The cellular metabolic process in which a cell duplicates one or more molecules of DNA. DNA replication begins when specific sequences, known as origins of replication, are recognized and bound by initiation proteins, and ends when the original DNA molecule has been completely duplicated and the copies topologically separated. The unit of replication usually corresponds to the genome of the cell, an organelle, or a virus. The template for replication can either be an existing DNA molecule or RNA. |
| | GO:0006270 | | DNA replication initiation | | The process in which DNA-dependent DNA replication is started; this involves the separation of a stretch of the DNA double helix, the recruitment of DNA polymerases and the initiation of polymerase action. |
| | GO:0006269 | | DNA replication, synthesis of RNA primer | | The synthesis of a short RNA polymer, usually 4-15 nucleotides long, using one strand of unwound DNA as a template; the RNA then serves as a primer from which DNA polymerases extend synthesis. |
| | GO:0006271 | | DNA strand elongation involved in DNA replication | | The process in which a DNA strand is synthesized from template DNA during replication by the action of polymerases, which add nucleotides to the 3' end of the nascent DNA strand. |
| | GO:0000082 | | G1/S transition of mitotic cell cycle | | The mitotic cell cycle transition by which a cell in G1 commits to S phase. The process begins with the build up of G1 cyclin-dependent kinase (G1 CDK), resulting in the activation of transcription of G1 cyclins. The process ends with the positive feedback of the G1 cyclins on the G1 CDK which commits the cell to S phase, in which DNA replication is initiated. |
| | GO:0000722 | | telomere maintenance via recombination | | Any recombinational process that contributes to the maintenance of proper telomeric length. |
| cellular component |
|---|
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:1990077 | | primosome complex | | Any of a family of protein complexes that form at the origin of replication or stalled replication forks and function in replication primer synthesis in all organisms. Early complexes initiate double-stranded DNA unwinding. The core unit consists of a replicative helicase and a primase. The helicase further unwinds the DNA and recruits the polymerase machinery. The primase synthesizes RNA primers that act as templates for complementary stand replication by the polymerase machinery. The primosome contains a number of associated proteins and protein complexes and contributes to the processes of replication initiation, lagging strand elongation, and replication restart. |
|
 Description
Description