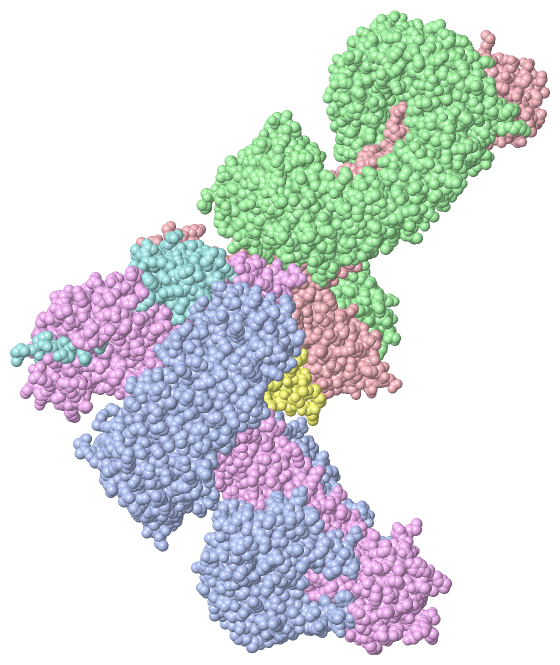
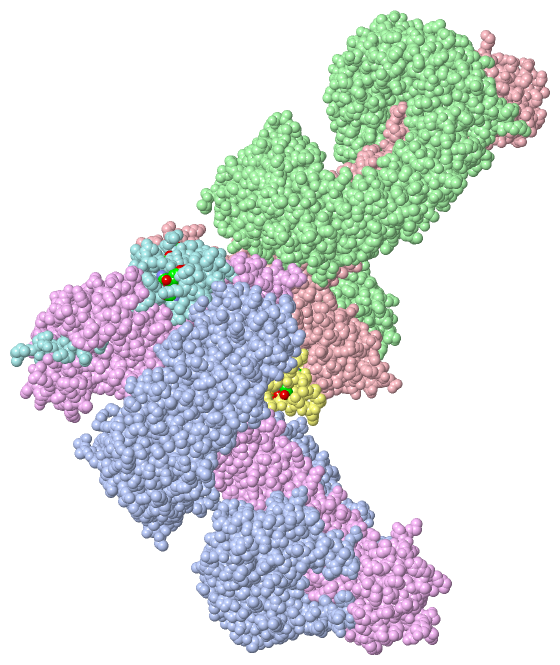
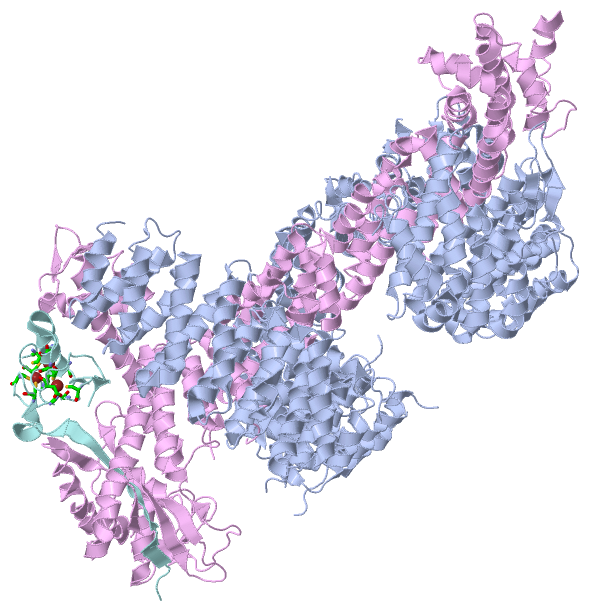
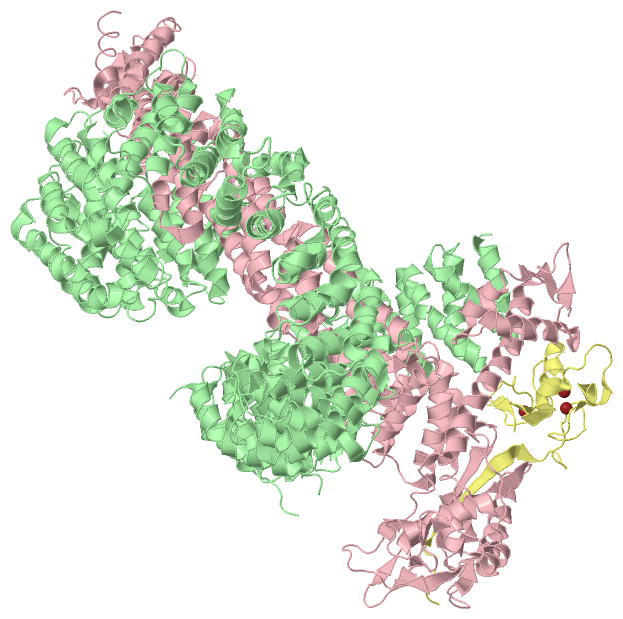
Asymmetric Unit(hide GO term definitions)
Chain A,B ( CAND1_HUMAN | Q86VP6)
| molecular function |
|---|
| | GO:0017025 | | TBP-class protein binding | | Interacting selectively and non-covalently with a member of the class of TATA-binding proteins (TBP), including any of the TBP-related factors (TRFs). |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| biological process |
|---|
| | GO:0010265 | | SCF complex assembly | | The aggregation, arrangement and bonding together of a set of components to form the SKP1-Cullin/Cdc53-F-box protein ubiquitin ligase (SCF) complex. |
| | GO:0030154 | | cell differentiation | | The process in which relatively unspecialized cells, e.g. embryonic or regenerative cells, acquire specialized structural and/or functional features that characterize the cells, tissues, or organs of the mature organism or some other relatively stable phase of the organism's life history. Differentiation includes the processes involved in commitment of a cell to a specific fate and its subsequent development to the mature state. |
| | GO:0043086 | | negative regulation of catalytic activity | | Any process that stops or reduces the activity of an enzyme. |
| | GO:0045899 | | positive regulation of RNA polymerase II transcriptional preinitiation complex assembly | | Any process that activates or increases the frequency, rate or extent of RNA polymerase II transcriptional preinitiation complex assembly. |
| | GO:0045893 | | positive regulation of transcription, DNA-templated | | Any process that activates or increases the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0016567 | | protein ubiquitination | | The process in which one or more ubiquitin groups are added to a protein. |
| cellular component |
|---|
| | GO:0005794 | | Golgi apparatus | | A compound membranous cytoplasmic organelle of eukaryotic cells, consisting of flattened, ribosome-free vesicles arranged in a more or less regular stack. The Golgi apparatus differs from the endoplasmic reticulum in often having slightly thicker membranes, appearing in sections as a characteristic shallow semicircle so that the convex side (cis or entry face) abuts the endoplasmic reticulum, secretory vesicles emerging from the concave side (trans or exit face). In vertebrate cells there is usually one such organelle, while in invertebrates and plants, where they are known usually as dictyosomes, there may be several scattered in the cytoplasm. The Golgi apparatus processes proteins produced on the ribosomes of the rough endoplasmic reticulum; such processing includes modification of the core oligosaccharides of glycoproteins, and the sorting and packaging of proteins for transport to a variety of cellular locations. Three different regions of the Golgi are now recognized both in terms of structure and function: cis, in the vicinity of the cis face, trans, in the vicinity of the trans face, and medial, lying between the cis and trans regions. |
| | GO:0031461 | | cullin-RING ubiquitin ligase complex | | Any ubiquitin ligase complex in which the catalytic core consists of a member of the cullin family and a RING domain protein; the core is associated with one or more additional proteins that confer substrate specificity. |
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0070062 | | extracellular exosome | | A vesicle that is released into the extracellular region by fusion of the limiting endosomal membrane of a multivesicular body with the plasma membrane. Extracellular exosomes, also simply called exosomes, have a diameter of about 40-100 nm. |
| | GO:0016020 | | membrane | | A lipid bilayer along with all the proteins and protein complexes embedded in it an attached to it. |
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0000151 | | ubiquitin ligase complex | | A protein complex that includes a ubiquitin-protein ligase and enables ubiquitin protein ligase activity. The complex also contains other proteins that may confer substrate specificity on the complex. |
Chain C,E ( CUL4B_HUMAN | Q13620)
| molecular function |
|---|
| | GO:0003684 | | damaged DNA binding | | Interacting selectively and non-covalently with damaged DNA. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0061630 | | ubiquitin protein ligase activity | | Catalysis of the transfer of ubiquitin to a substrate protein via the reaction X-ubiquitin + S -> X + S-ubiquitin, where X is either an E2 or E3 enzyme, the X-ubiquitin linkage is a thioester bond, and the S-ubiquitin linkage is an amide bond: an isopeptide bond between the C-terminal glycine of ubiquitin and the epsilon-amino group of lysine residues in the substrate or, in the linear extension of ubiquitin chains, a peptide bond the between the C-terminal glycine and N-terminal methionine of ubiquitin residues. |
| | GO:0031625 | | ubiquitin protein ligase binding | | Interacting selectively and non-covalently with a ubiquitin protein ligase enzyme, any of the E3 proteins. |
| biological process |
|---|
| | GO:0042769 | | DNA damage response, detection of DNA damage | | The series of events required to receive a stimulus indicating DNA damage has occurred and convert it to a molecular signal. |
| | GO:0006281 | | DNA repair | | The process of restoring DNA after damage. Genomes are subject to damage by chemical and physical agents in the environment (e.g. UV and ionizing radiations, chemical mutagens, fungal and bacterial toxins, etc.) and by free radicals or alkylating agents endogenously generated in metabolism. DNA is also damaged because of errors during its replication. A variety of different DNA repair pathways have been reported that include direct reversal, base excision repair, nucleotide excision repair, photoreactivation, bypass, double-strand break repair pathway, and mismatch repair pathway. |
| | GO:0070914 | | UV-damage excision repair | | A DNA repair process that is initiated by an endonuclease that introduces a single-strand incision immediately 5' of a UV-induced damage site. UV-damage excision repair acts on both cyclobutane pyrimidine dimers (CPDs) and pyrimidine-pyrimidone 6-4 photoproducts (6-4PPs). |
| | GO:0007049 | | cell cycle | | The progression of biochemical and morphological phases and events that occur in a cell during successive cell replication or nuclear replication events. Canonically, the cell cycle comprises the replication and segregation of genetic material followed by the division of the cell, but in endocycles or syncytial cells nuclear replication or nuclear division may not be followed by cell division. |
| | GO:0006974 | | cellular response to DNA damage stimulus | | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus indicating damage to its DNA from environmental insults or errors during metabolism. |
| | GO:0070911 | | global genome nucleotide-excision repair | | The nucleotide-excision repair process in which DNA lesions are removed from nontranscribed strands and from transcriptionally silent regions over the entire genome. |
| | GO:0035518 | | histone H2A monoubiquitination | | The modification of histone H2A by addition of a single ubiquitin group. |
| | GO:0031175 | | neuron projection development | | The process whose specific outcome is the progression of a neuron projection over time, from its formation to the mature structure. A neuron projection is any process extending from a neural cell, such as axons or dendrites (collectively called neurites). |
| | GO:0000715 | | nucleotide-excision repair, DNA damage recognition | | The identification of lesions in DNA, such as pyrimidine-dimers, intrastrand cross-links, and bulky adducts. The wide range of substrate specificity suggests the repair complex recognizes distortions in the DNA helix. |
| | GO:0000717 | | nucleotide-excision repair, DNA duplex unwinding | | The unwinding, or local denaturation, of the DNA duplex to create a bubble around the site of the DNA damage. |
| | GO:0033683 | | nucleotide-excision repair, DNA incision | | A process that results in the endonucleolytic cleavage of the damaged strand of DNA. The incision occurs at the junction of single-stranded DNA and double-stranded DNA that is formed when the DNA duplex is unwound. |
| | GO:0006295 | | nucleotide-excision repair, DNA incision, 3'-to lesion | | The endonucleolytic cleavage of the damaged strand of DNA 3' to the site of damage. The incision occurs at the junction of single-stranded DNA and double-stranded DNA that is formed when the DNA duplex is unwound. The incision precedes the incision formed 5' to the site of damage. |
| | GO:0006296 | | nucleotide-excision repair, DNA incision, 5'-to lesion | | The endonucleolytic cleavage of the damaged strand of DNA 5' to the site of damage. The incision occurs at the junction of single-stranded DNA and double-stranded DNA that is formed when the DNA duplex is unwound. The incision follows the incision formed 3' to the site of damage. |
| | GO:0006294 | | nucleotide-excision repair, preincision complex assembly | | The aggregation, arrangement and bonding together of proteins on DNA to form the multiprotein complex involved in damage recognition, DNA helix unwinding, and endonucleolytic cleavage at the site of DNA damage. This assembly occurs before the phosphodiester backbone of the damaged strand is cleaved 3' and 5' of the site of DNA damage. |
| | GO:0006293 | | nucleotide-excision repair, preincision complex stabilization | | The stabilization of the multiprotein complex involved in damage recognition, DNA helix unwinding, and endonucleolytic cleavage at the site of DNA damage as well as the unwound DNA. The stabilization of the protein-DNA complex ensures proper positioning of the preincision complex before the phosphodiester backbone of the damaged strand is cleaved 3' and 5' of the site of DNA damage. |
| | GO:1900087 | | positive regulation of G1/S transition of mitotic cell cycle | | Any cell cycle regulatory process that promotes the commitment of a cell from G1 to S phase of the mitotic cell cycle. |
| | GO:0045732 | | positive regulation of protein catabolic process | | Any process that activates or increases the frequency, rate or extent of the chemical reactions and pathways resulting in the breakdown of a protein by the destruction of the native, active configuration, with or without the hydrolysis of peptide bonds. |
| | GO:0016567 | | protein ubiquitination | | The process in which one or more ubiquitin groups are added to a protein. |
| | GO:0042787 | | protein ubiquitination involved in ubiquitin-dependent protein catabolic process | | The process in which a ubiquitin group, or multiple groups, are covalently attached to the target protein, thereby initiating the degradation of that protein. |
| | GO:0006283 | | transcription-coupled nucleotide-excision repair | | The nucleotide-excision repair process that carries out preferential repair of DNA lesions on the actively transcribed strand of the DNA duplex. In addition, the transcription-coupled nucleotide-excision repair pathway is required for the recognition and repair of a small subset of lesions that are not recognized by the global genome nucleotide excision repair pathway. |
| | GO:0006511 | | ubiquitin-dependent protein catabolic process | | The chemical reactions and pathways resulting in the breakdown of a protein or peptide by hydrolysis of its peptide bonds, initiated by the covalent attachment of a ubiquitin group, or multiple ubiquitin groups, to the protein. |
| cellular component |
|---|
| | GO:0031465 | | Cul4B-RING E3 ubiquitin ligase complex | | A ubiquitin ligase complex in which a cullin from the Cul4B subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by unknown subunits. |
| | GO:0031461 | | cullin-RING ubiquitin ligase complex | | Any ubiquitin ligase complex in which the catalytic core consists of a member of the cullin family and a RING domain protein; the core is associated with one or more additional proteins that confer substrate specificity. |
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0005829 | | cytosol | | The part of the cytoplasm that does not contain organelles but which does contain other particulate matter, such as protein complexes. |
| | GO:0070062 | | extracellular exosome | | A vesicle that is released into the extracellular region by fusion of the limiting endosomal membrane of a multivesicular body with the plasma membrane. Extracellular exosomes, also simply called exosomes, have a diameter of about 40-100 nm. |
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
Chain D,F ( RBX1_MOUSE | P62878)
| molecular function |
|---|
| | GO:0019788 | | NEDD8 transferase activity | | Catalysis of the transfer of NEDD8 from one protein to another via the reaction X-NEDD8 + Y --> Y-NEDD8 + X, where both X-NEDD8 and Y-NEDD8 are covalent linkages. |
| | GO:0097602 | | cullin family protein binding | | Interacting selectively and non-covalently with any member of the cullin family, hydrophobic proteins that act as scaffolds for ubiquitin ligases (E3). |
| | GO:0008190 | | eukaryotic initiation factor 4E binding | | Interacting selectively and non-covalently with eukaryotic initiation factor 4E, a polypeptide factor involved in the initiation of ribosome-mediated translation. |
| | GO:0016874 | | ligase activity | | Catalysis of the joining of two substances, or two groups within a single molecule, with the concomitant hydrolysis of the diphosphate bond in ATP or a similar triphosphate. |
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0032403 | | protein complex binding | | Interacting selectively and non-covalently with any protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0061630 | | ubiquitin protein ligase activity | | Catalysis of the transfer of ubiquitin to a substrate protein via the reaction X-ubiquitin + S -> X + S-ubiquitin, where X is either an E2 or E3 enzyme, the X-ubiquitin linkage is a thioester bond, and the S-ubiquitin linkage is an amide bond: an isopeptide bond between the C-terminal glycine of ubiquitin and the epsilon-amino group of lysine residues in the substrate or, in the linear extension of ubiquitin chains, a peptide bond the between the C-terminal glycine and N-terminal methionine of ubiquitin residues. |
| | GO:0031625 | | ubiquitin protein ligase binding | | Interacting selectively and non-covalently with a ubiquitin protein ligase enzyme, any of the E3 proteins. |
| | GO:0004842 | | ubiquitin-protein transferase activity | | Catalysis of the transfer of ubiquitin from one protein to another via the reaction X-Ub + Y --> Y-Ub + X, where both X-Ub and Y-Ub are covalent linkages. |
| | GO:0034450 | | ubiquitin-ubiquitin ligase activity | | Isoenergetic transfer of ubiquitin from one protein to an existing ubiquitin chain via the reaction X-ubiquitin + Y-ubiquitin -> Y-ubiquitin-ubiquitin + X, where both the X-ubiquitin and Y-ubiquitin-ubiquitin linkages are thioester bonds between the C-terminal glycine of ubiquitin and a sulfhydryl side group of a cysteine residue. |
| | GO:0008270 | | zinc ion binding | | Interacting selectively and non-covalently with zinc (Zn) ions. |
| biological process |
|---|
| | GO:0006281 | | DNA repair | | The process of restoring DNA after damage. Genomes are subject to damage by chemical and physical agents in the environment (e.g. UV and ionizing radiations, chemical mutagens, fungal and bacterial toxins, etc.) and by free radicals or alkylating agents endogenously generated in metabolism. DNA is also damaged because of errors during its replication. A variety of different DNA repair pathways have been reported that include direct reversal, base excision repair, nucleotide excision repair, photoreactivation, bypass, double-strand break repair pathway, and mismatch repair pathway. |
| | GO:0031146 | | SCF-dependent proteasomal ubiquitin-dependent protein catabolic process | | The chemical reactions and pathways resulting in the breakdown of a protein or peptide by hydrolysis of its peptide bonds, initiated by the covalent attachment of ubiquitin, with ubiquitin-protein ligation catalyzed by an SCF (Skp1/Cul1/F-box protein) complex, and mediated by the proteasome. |
| | GO:0006974 | | cellular response to DNA damage stimulus | | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus indicating damage to its DNA from environmental insults or errors during metabolism. |
| | GO:0043161 | | proteasome-mediated ubiquitin-dependent protein catabolic process | | The chemical reactions and pathways resulting in the breakdown of a protein or peptide by hydrolysis of its peptide bonds, initiated by the covalent attachment of ubiquitin, and mediated by the proteasome. |
| | GO:0030163 | | protein catabolic process | | The chemical reactions and pathways resulting in the breakdown of a protein by the destruction of the native, active configuration, with or without the hydrolysis of peptide bonds. |
| | GO:0006513 | | protein monoubiquitination | | Addition of a single ubiquitin group to a protein. |
| | GO:0045116 | | protein neddylation | | Covalent attachment of the ubiquitin-like protein NEDD8 (RUB1) to another protein. |
| | GO:0016567 | | protein ubiquitination | | The process in which one or more ubiquitin groups are added to a protein. |
| | GO:0042787 | | protein ubiquitination involved in ubiquitin-dependent protein catabolic process | | The process in which a ubiquitin group, or multiple groups, are covalently attached to the target protein, thereby initiating the degradation of that protein. |
| | GO:0006511 | | ubiquitin-dependent protein catabolic process | | The chemical reactions and pathways resulting in the breakdown of a protein or peptide by hydrolysis of its peptide bonds, initiated by the covalent attachment of a ubiquitin group, or multiple ubiquitin groups, to the protein. |
| cellular component |
|---|
| | GO:0031462 | | Cul2-RING ubiquitin ligase complex | | A ubiquitin ligase complex in which a cullin from the Cul2 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by an elongin-BC adaptor and a SOCS/BC box protein. |
| | GO:0031463 | | Cul3-RING ubiquitin ligase complex | | A ubiquitin ligase complex in which a cullin from the Cul3 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by a BTB-domain-containing protein. |
| | GO:0080008 | | Cul4-RING E3 ubiquitin ligase complex | | A ubiquitin ligase complex in which a cullin from the Cul4 family and a RING domain protein form the catalytic core; substrate specificity is conferred by an adaptor protein. |
| | GO:0031464 | | Cul4A-RING E3 ubiquitin ligase complex | | A ubiquitin ligase complex in which a cullin from the Cul4A subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by an adaptor protein. |
| | GO:0031465 | | Cul4B-RING E3 ubiquitin ligase complex | | A ubiquitin ligase complex in which a cullin from the Cul4B subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by unknown subunits. |
| | GO:0031466 | | Cul5-RING ubiquitin ligase complex | | A ubiquitin ligase complex in which a cullin from the Cul5 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by an elongin-BC adaptor and a SOCS/BC box protein. |
| | GO:0031467 | | Cul7-RING ubiquitin ligase complex | | A ubiquitin ligase complex in which a cullin from the Cul7 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by a Skp1 linker and an F-box protein. |
| | GO:0019005 | | SCF ubiquitin ligase complex | | A ubiquitin ligase complex in which a cullin from the Cul1 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by a Skp1 adaptor and an F-box protein. SCF complexes are involved in targeting proteins for degradation by the proteasome. The best characterized complexes are those from yeast and mammals (with core subunits named Cdc53/Cul1, Rbx1/Hrt1/Roc1). |
| | GO:0030891 | | VCB complex | | A protein complex that possesses ubiquitin ligase activity; the complex is usually pentameric; for example, in mammals the subunits are pVHL, elongin B, elongin C, cullin-2 (Cul2), and Rbx1. |
| | GO:0005680 | | anaphase-promoting complex | | A ubiquitin ligase complex that degrades mitotic cyclins and anaphase inhibitory protein, thereby triggering sister chromatid separation and exit from mitosis. Substrate recognition by APC occurs through degradation signals, the most common of which is termed the Dbox degradation motif, originally discovered in cyclin B. |
| | GO:0031461 | | cullin-RING ubiquitin ligase complex | | Any ubiquitin ligase complex in which the catalytic core consists of a member of the cullin family and a RING domain protein; the core is associated with one or more additional proteins that confer substrate specificity. |
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0005829 | | cytosol | | The part of the cytoplasm that does not contain organelles but which does contain other particulate matter, such as protein complexes. |
| | GO:0043224 | | nuclear SCF ubiquitin ligase complex | | A ubiquitin ligase complex, located in the nucleus, in which a cullin from the Cul1 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by a Skp1 adaptor and an F-box protein. SCF complexes are involved in targeting proteins for degradation by the proteasome. The best characterized complexes are those from yeast and mammals (with core subunits named Cdc53/Cul1, Rbx1/Hrt1/Roc1). |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0000151 | | ubiquitin ligase complex | | A protein complex that includes a ubiquitin-protein ligase and enables ubiquitin protein ligase activity. The complex also contains other proteins that may confer substrate specificity on the complex. |
|
 Description
Description