|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
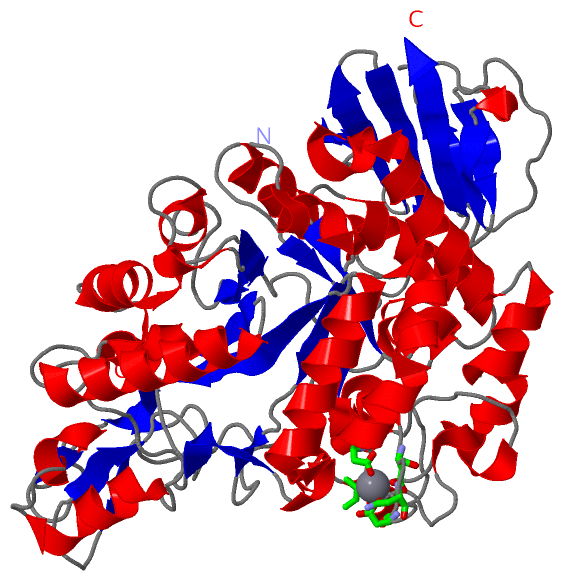
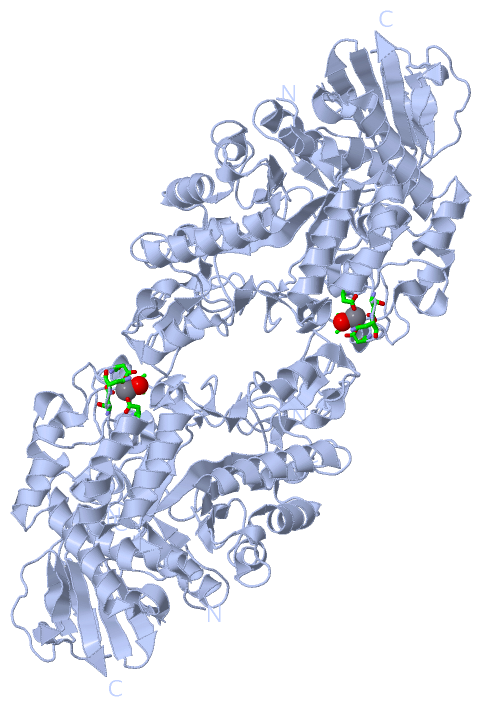
Ligands, Modified Residues, Ions (1, 1)
Asymmetric Unit (1, 1)
|
Sites (1, 1)
Asymmetric Unit (1, 1)
|
SS Bonds (0, 0)| (no "SS Bond" information available for 2ZE0) |
Cis Peptide Bonds (0, 0)| (no "Cis Peptide Bond" information available for 2ZE0) |
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 2ZE0) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 2ZE0) |
Exons (0, 0)| (no "Exon" information available for 2ZE0) |
Sequences/Alignments
Asymmetric UnitChain A from PDB Type:PROTEIN Length:531 aligned with Q33E90_9BACI | Q33E90 from UniProtKB/TrEMBL Length:555 Alignment length:554 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 301 311 321 331 341 351 361 371 381 391 401 411 421 431 441 451 461 471 481 491 501 511 521 531 541 551 Q33E90_9BACI 2 KKTWWKEGVAYQIYPRSFMDANGDGIGDLRGIIEKLDYLVELGVDIVWICPIYRSPNADNGYDISDYYAIMDEFGTMDDFDELLAQAHRRGLKVILDLVINHTSDEHPWFIESRSSRDNPKRDWYIWRDGKDGREPNNWESIFGGSAWQYDERTGQYYLHIFDVKQPDLNWENSEVRQALYEMVNWWLDKGIDGFRIDAISHIKKKPGLPDLPNPKGLKYVPSFAGHMNQPGIMEYLRELKEQTFARYDIMTVGEANGVTVDEAEQWVGEENGVFNMIFQFEHLGLWERRADGSIDVRRLKRTLTKWQKGLENRGWNALFLENHDLPRSVSTWGNDRDYWAESAKALGALYFFMQGTPFIYQGQEIGMTNVRFDDIRDYRDVSALRLYELERAKGRTHEEAMTIIWKTGRDNSRTPMQWSGASNAGFTTGTPWIKVNENYRTINVEAERRDPNSVWSFYRQMIQLRKANELFVYGTYDLLLENHPSIYAYTRTLGRDRALVVVNLSDRPSLYRYDGFRLQSSDLALSNYPVRPHKNATRFKLKPYEARVYIWKE 555 SCOP domains d2ze0a1 A:2-471 automated matches d2ze0a2 A:472-551 automated matches SCOP domains CATH domains -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains --------------------------Alpha-amylase-2ze0A01 A:28-378 --------- ------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2ze0 A 2 KKTWWKEGVAYQIYPRSFMDANGDGIGDLRGIIEKLDYLVELGVDIVWICPIYRSPNADNGYDISDYYAIMDEFGTMDDFDELLAQAHRRGLKVILDLVINHTSDEHPWFIESRSSRDNPKRDWYIWRDGKDGREPNNWESIFGGSAWQYDERTGQYYLHIFDVKQPDLNWENSEVRQALYEMVNWWLDKGIDGFRIDAISHIKKKPGLPDLP----LKYVPSFAGHMNQPGIMEYLRELKEQTFARYDIMTVGEANGVTVDEAEQWVGEENGVFNMIFQFEHLGLWERRA--SIDVRRLKRTLTKWQKGLENRGWNALFLENHDLPRSVSTWGNDRDYWAESAKALGALYFFMQGTPFIYQGQEIGMTNVRFDDIRDYRDVSALR-----------------IIWKTGRDNSRTPMQWSGASNAGFTTGTPWIKVNENYRTINVEAERRDPNSVWSFYRQMIQLRKANELFVYGTYDLLLENHPSIYAYTRTLGRDRALVVVNLSDRPSLYRYDGFRLQSSDLALSNYPVRPHKNATRFKLKPYEARVYIWKE 551 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 201 211 | 221 231 241 251 261 271 281 291| | 301 311 321 331 341 351 361 371 381 | - - | 407 417 427 437 447 457 467 477 487 497 507 517 527 537 547 214 219 292 | 387 401 295
|
||||||||||||||||||||
SCOP Domains (2, 2)
Asymmetric Unit

|
CATH Domains (0, 0)| (no "CATH Domain" information available for 2ZE0) |
Pfam Domains (1, 1)
Asymmetric Unit
|
Gene Ontology (8, 8)|
Asymmetric Unit(hide GO term definitions) Chain A (Q33E90_9BACI | Q33E90)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|