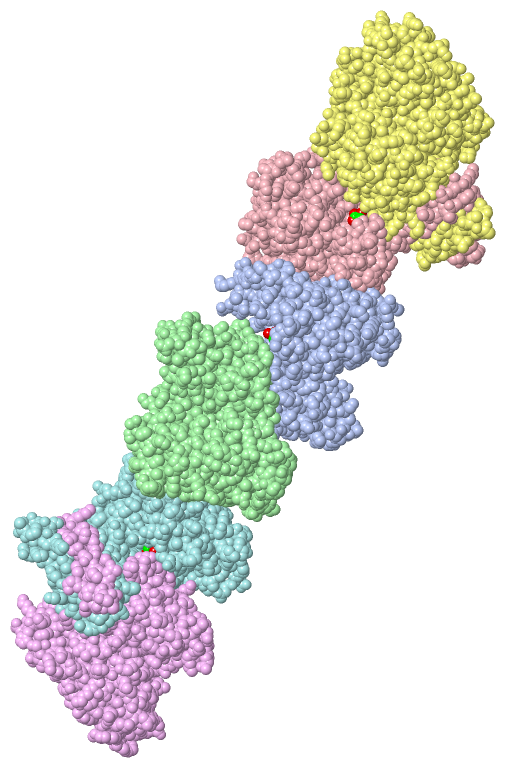
|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (1, 6)
Asymmetric Unit (1, 6)
|
Sites (6, 6)
Asymmetric Unit (6, 6)
|
SS Bonds (0, 0)| (no "SS Bond" information available for 2QFY) |
Cis Peptide Bonds (0, 0)| (no "Cis Peptide Bond" information available for 2QFY) |
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 2QFY) |
PROSITE Motifs (1, 6)
Asymmetric Unit (1, 6)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Exons (0, 0)| (no "Exon" information available for 2QFY) |
Sequences/Alignments
Asymmetric UnitChain A from PDB Type:PROTEIN Length:411 aligned with IDHP_YEAST | P21954 from UniProtKB/Swiss-Prot Length:428 Alignment length:411 26 36 46 56 66 76 86 96 106 116 126 136 146 156 166 176 186 196 206 216 226 236 246 256 266 276 286 296 306 316 326 336 346 356 366 376 386 396 406 416 426 IDHP_YEAST 17 FSKIKVKQPVVELDGDEMTRIIWDKIKKKLILPYLDVDLKYYDLSVESRDATSDKITQDAAEAIKKYGVGIKCATITPDEARVKEFNLHKMWKSPNGTIRNILGGTVFREPIVIPRIPRLVPRWEKPIIIGRHAHGDQYKATDTLIPGPGSLELVYKPSDPTTAQPQTLKVYDYKGSGVAMAMYNTDESIEGFAHSSFKLAIDKKLNLFLSTKNTILKKYDGRFKDIFQEVYEAQYKSKFEQLGIHYEHRLIDDMVAQMIKSKGGFIMALKNYDGDVQSDIVAQGFGSLGLMTSILVTPDGKTFESEAAHGTVTRHYRKYQKGEETSTNSIASIFAWSRGLLKRGELDNTPALCKFANILESATLNTVQQDGIMTKDLALACGNNERSAYVTTEEFLDAVEKRLQKEIKSI 427 SCOP domains d2qfya_ A: automated matches SCOP domains CATH domains 2qfyA00 A:2-412 Isopropylmalate Dehydrogenase CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------IDH_IMDH ------------------------------------------------------------------------------------------------------------------------ PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2qfy A 2 FSKIKVKQPVVELDGDEMTRIIWDKIKKKLILPYLDVDLKYYDLSVESRDATSDKITQDAAEAIKKYGVGIKCATITPDEARVKEFNLHKMWKSPNGTIRNILGGTVFREPIVIPRIPRLVPRWEKPIIIGRHAHGDQYKATDTLIPGPGSLELVYKPSDPTTAQPQTLKVYDYKGSGVAMAMYNTDESIEGFAHSSFKLAIDKKLNLFLSTKNTILKKYDGRFKDIFQEVYEAQYKSKFEQLGIHYEHRLIDDMVAQMIKSKGGFIMALKNYDGDVQSDIVAQGFGSLGLMTSILVTPDGKTFESEAAHGTVTRHYRKYQKGEETSTNSIASIFAWSRGLLKRGELDNTPALCKFANILESATLNTVQQDGIMTKDLALACGNNERSAYVTTEEFLDAVEKRLQKEIKSI 412 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 301 311 321 331 341 351 361 371 381 391 401 411 Chain B from PDB Type:PROTEIN Length:411 aligned with IDHP_YEAST | P21954 from UniProtKB/Swiss-Prot Length:428 Alignment length:411 25 35 45 55 65 75 85 95 105 115 125 135 145 155 165 175 185 195 205 215 225 235 245 255 265 275 285 295 305 315 325 335 345 355 365 375 385 395 405 415 425 IDHP_YEAST 16 AFSKIKVKQPVVELDGDEMTRIIWDKIKKKLILPYLDVDLKYYDLSVESRDATSDKITQDAAEAIKKYGVGIKCATITPDEARVKEFNLHKMWKSPNGTIRNILGGTVFREPIVIPRIPRLVPRWEKPIIIGRHAHGDQYKATDTLIPGPGSLELVYKPSDPTTAQPQTLKVYDYKGSGVAMAMYNTDESIEGFAHSSFKLAIDKKLNLFLSTKNTILKKYDGRFKDIFQEVYEAQYKSKFEQLGIHYEHRLIDDMVAQMIKSKGGFIMALKNYDGDVQSDIVAQGFGSLGLMTSILVTPDGKTFESEAAHGTVTRHYRKYQKGEETSTNSIASIFAWSRGLLKRGELDNTPALCKFANILESATLNTVQQDGIMTKDLALACGNNERSAYVTTEEFLDAVEKRLQKEIKS 426 SCOP domains d2qfyb_ B: automated matches SCOP domains CATH domains 2qfyB00 B:1-411 Isopropylmalate Dehydrogenase CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------IDH_IMDH ----------------------------------------------------------------------------------------------------------------------- PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2qfy B 1 AFSKIKVKQPVVELDGDEMTRIIWDKIKKKLILPYLDVDLKYYDLSVESRDATSDKITQDAAEAIKKYGVGIKCATITPDEARVKEFNLHKMWKSPNGTIRNILGGTVFREPIVIPRIPRLVPRWEKPIIIGRHAHGDQYKATDTLIPGPGSLELVYKPSDPTTAQPQTLKVYDYKGSGVAMAMYNTDESIEGFAHSSFKLAIDKKLNLFLSTKNTILKKYDGRFKDIFQEVYEAQYKSKFEQLGIHYEHRLIDDMVAQMIKSKGGFIMALKNYDGDVQSDIVAQGFGSLGLMTSILVTPDGKTFESEAAHGTVTRHYRKYQKGEETSTNSIASIFAWSRGLLKRGELDNTPALCKFANILESATLNTVQQDGIMTKDLALACGNNERSAYVTTEEFLDAVEKRLQKEIKS 411 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350 360 370 380 390 400 410 Chain C from PDB Type:PROTEIN Length:411 aligned with IDHP_YEAST | P21954 from UniProtKB/Swiss-Prot Length:428 Alignment length:411 25 35 45 55 65 75 85 95 105 115 125 135 145 155 165 175 185 195 205 215 225 235 245 255 265 275 285 295 305 315 325 335 345 355 365 375 385 395 405 415 425 IDHP_YEAST 16 AFSKIKVKQPVVELDGDEMTRIIWDKIKKKLILPYLDVDLKYYDLSVESRDATSDKITQDAAEAIKKYGVGIKCATITPDEARVKEFNLHKMWKSPNGTIRNILGGTVFREPIVIPRIPRLVPRWEKPIIIGRHAHGDQYKATDTLIPGPGSLELVYKPSDPTTAQPQTLKVYDYKGSGVAMAMYNTDESIEGFAHSSFKLAIDKKLNLFLSTKNTILKKYDGRFKDIFQEVYEAQYKSKFEQLGIHYEHRLIDDMVAQMIKSKGGFIMALKNYDGDVQSDIVAQGFGSLGLMTSILVTPDGKTFESEAAHGTVTRHYRKYQKGEETSTNSIASIFAWSRGLLKRGELDNTPALCKFANILESATLNTVQQDGIMTKDLALACGNNERSAYVTTEEFLDAVEKRLQKEIKS 426 SCOP domains d2qfyc_ C: automated matches SCOP domains CATH domains 2qfyC00 C:1-411 Isopropylmalate Dehydrogenase CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------IDH_IMDH ----------------------------------------------------------------------------------------------------------------------- PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2qfy C 1 AFSKIKVKQPVVELDGDEMTRIIWDKIKKKLILPYLDVDLKYYDLSVESRDATSDKITQDAAEAIKKYGVGIKCATITPDEARVKEFNLHKMWKSPNGTIRNILGGTVFREPIVIPRIPRLVPRWEKPIIIGRHAHGDQYKATDTLIPGPGSLELVYKPSDPTTAQPQTLKVYDYKGSGVAMAMYNTDESIEGFAHSSFKLAIDKKLNLFLSTKNTILKKYDGRFKDIFQEVYEAQYKSKFEQLGIHYEHRLIDDMVAQMIKSKGGFIMALKNYDGDVQSDIVAQGFGSLGLMTSILVTPDGKTFESEAAHGTVTRHYRKYQKGEETSTNSIASIFAWSRGLLKRGELDNTPALCKFANILESATLNTVQQDGIMTKDLALACGNNERSAYVTTEEFLDAVEKRLQKEIKS 411 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350 360 370 380 390 400 410 Chain D from PDB Type:PROTEIN Length:411 aligned with IDHP_YEAST | P21954 from UniProtKB/Swiss-Prot Length:428 Alignment length:411 26 36 46 56 66 76 86 96 106 116 126 136 146 156 166 176 186 196 206 216 226 236 246 256 266 276 286 296 306 316 326 336 346 356 366 376 386 396 406 416 426 IDHP_YEAST 17 FSKIKVKQPVVELDGDEMTRIIWDKIKKKLILPYLDVDLKYYDLSVESRDATSDKITQDAAEAIKKYGVGIKCATITPDEARVKEFNLHKMWKSPNGTIRNILGGTVFREPIVIPRIPRLVPRWEKPIIIGRHAHGDQYKATDTLIPGPGSLELVYKPSDPTTAQPQTLKVYDYKGSGVAMAMYNTDESIEGFAHSSFKLAIDKKLNLFLSTKNTILKKYDGRFKDIFQEVYEAQYKSKFEQLGIHYEHRLIDDMVAQMIKSKGGFIMALKNYDGDVQSDIVAQGFGSLGLMTSILVTPDGKTFESEAAHGTVTRHYRKYQKGEETSTNSIASIFAWSRGLLKRGELDNTPALCKFANILESATLNTVQQDGIMTKDLALACGNNERSAYVTTEEFLDAVEKRLQKEIKSI 427 SCOP domains d2qfyd_ D: automated matches SCOP domains CATH domains 2qfyD00 D:2-412 Isopropylmalate Dehydrogenase CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------IDH_IMDH ------------------------------------------------------------------------------------------------------------------------ PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2qfy D 2 FSKIKVKQPVVELDGDEMTRIIWDKIKKKLILPYLDVDLKYYDLSVESRDATSDKITQDAAEAIKKYGVGIKCATITPDEARVKEFNLHKMWKSPNGTIRNILGGTVFREPIVIPRIPRLVPRWEKPIIIGRHAHGDQYKATDTLIPGPGSLELVYKPSDPTTAQPQTLKVYDYKGSGVAMAMYNTDESIEGFAHSSFKLAIDKKLNLFLSTKNTILKKYDGRFKDIFQEVYEAQYKSKFEQLGIHYEHRLIDDMVAQMIKSKGGFIMALKNYDGDVQSDIVAQGFGSLGLMTSILVTPDGKTFESEAAHGTVTRHYRKYQKGEETSTNSIASIFAWSRGLLKRGELDNTPALCKFANILESATLNTVQQDGIMTKDLALACGNNERSAYVTTEEFLDAVEKRLQKEIKSI 412 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 301 311 321 331 341 351 361 371 381 391 401 411 Chain E from PDB Type:PROTEIN Length:411 aligned with IDHP_YEAST | P21954 from UniProtKB/Swiss-Prot Length:428 Alignment length:411 25 35 45 55 65 75 85 95 105 115 125 135 145 155 165 175 185 195 205 215 225 235 245 255 265 275 285 295 305 315 325 335 345 355 365 375 385 395 405 415 425 IDHP_YEAST 16 AFSKIKVKQPVVELDGDEMTRIIWDKIKKKLILPYLDVDLKYYDLSVESRDATSDKITQDAAEAIKKYGVGIKCATITPDEARVKEFNLHKMWKSPNGTIRNILGGTVFREPIVIPRIPRLVPRWEKPIIIGRHAHGDQYKATDTLIPGPGSLELVYKPSDPTTAQPQTLKVYDYKGSGVAMAMYNTDESIEGFAHSSFKLAIDKKLNLFLSTKNTILKKYDGRFKDIFQEVYEAQYKSKFEQLGIHYEHRLIDDMVAQMIKSKGGFIMALKNYDGDVQSDIVAQGFGSLGLMTSILVTPDGKTFESEAAHGTVTRHYRKYQKGEETSTNSIASIFAWSRGLLKRGELDNTPALCKFANILESATLNTVQQDGIMTKDLALACGNNERSAYVTTEEFLDAVEKRLQKEIKS 426 SCOP domains d2qfye_ E: automated matches SCOP domains CATH domains 2qfyE00 E:1-411 Isopropylmalate Dehydrogenase CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------IDH_IMDH ----------------------------------------------------------------------------------------------------------------------- PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2qfy E 1 AFSKIKVKQPVVELDGDEMTRIIWDKIKKKLILPYLDVDLKYYDLSVESRDATSDKITQDAAEAIKKYGVGIKCATITPDEARVKEFNLHKMWKSPNGTIRNILGGTVFREPIVIPRIPRLVPRWEKPIIIGRHAHGDQYKATDTLIPGPGSLELVYKPSDPTTAQPQTLKVYDYKGSGVAMAMYNTDESIEGFAHSSFKLAIDKKLNLFLSTKNTILKKYDGRFKDIFQEVYEAQYKSKFEQLGIHYEHRLIDDMVAQMIKSKGGFIMALKNYDGDVQSDIVAQGFGSLGLMTSILVTPDGKTFESEAAHGTVTRHYRKYQKGEETSTNSIASIFAWSRGLLKRGELDNTPALCKFANILESATLNTVQQDGIMTKDLALACGNNERSAYVTTEEFLDAVEKRLQKEIKS 411 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350 360 370 380 390 400 410 Chain F from PDB Type:PROTEIN Length:411 aligned with IDHP_YEAST | P21954 from UniProtKB/Swiss-Prot Length:428 Alignment length:411 26 36 46 56 66 76 86 96 106 116 126 136 146 156 166 176 186 196 206 216 226 236 246 256 266 276 286 296 306 316 326 336 346 356 366 376 386 396 406 416 426 IDHP_YEAST 17 FSKIKVKQPVVELDGDEMTRIIWDKIKKKLILPYLDVDLKYYDLSVESRDATSDKITQDAAEAIKKYGVGIKCATITPDEARVKEFNLHKMWKSPNGTIRNILGGTVFREPIVIPRIPRLVPRWEKPIIIGRHAHGDQYKATDTLIPGPGSLELVYKPSDPTTAQPQTLKVYDYKGSGVAMAMYNTDESIEGFAHSSFKLAIDKKLNLFLSTKNTILKKYDGRFKDIFQEVYEAQYKSKFEQLGIHYEHRLIDDMVAQMIKSKGGFIMALKNYDGDVQSDIVAQGFGSLGLMTSILVTPDGKTFESEAAHGTVTRHYRKYQKGEETSTNSIASIFAWSRGLLKRGELDNTPALCKFANILESATLNTVQQDGIMTKDLALACGNNERSAYVTTEEFLDAVEKRLQKEIKSI 427 SCOP domains d2qfyf_ F: automated matches SCOP domains CATH domains 2qfyF00 F:2-412 Isopropylmalate Dehydrogenase CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------IDH_IMDH ------------------------------------------------------------------------------------------------------------------------ PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2qfy F 2 FSKIKVKQPVVELDGDEMTRIIWDKIKKKLILPYLDVDLKYYDLSVESRDATSDKITQDAAEAIKKYGVGIKCATITPDEARVKEFNLHKMWKSPNGTIRNILGGTVFREPIVIPRIPRLVPRWEKPIIIGRHAHGDQYKATDTLIPGPGSLELVYKPSDPTTAQPQTLKVYDYKGSGVAMAMYNTDESIEGFAHSSFKLAIDKKLNLFLSTKNTILKKYDGRFKDIFQEVYEAQYKSKFEQLGIHYEHRLIDDMVAQMIKSKGGFIMALKNYDGDVQSDIVAQGFGSLGLMTSILVTPDGKTFESEAAHGTVTRHYRKYQKGEETSTNSIASIFAWSRGLLKRGELDNTPALCKFANILESATLNTVQQDGIMTKDLALACGNNERSAYVTTEEFLDAVEKRLQKEIKSI 412 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 301 311 321 331 341 351 361 371 381 391 401 411
|
||||||||||||||||||||
SCOP Domains (1, 6)
Asymmetric Unit
 |
CATH Domains (1, 6)
Asymmetric Unit
|
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 2QFY) |
Gene Ontology (14, 14)|
Asymmetric Unit(hide GO term definitions) Chain A,B,C,D,E,F (IDHP_YEAST | P21954)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|