|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
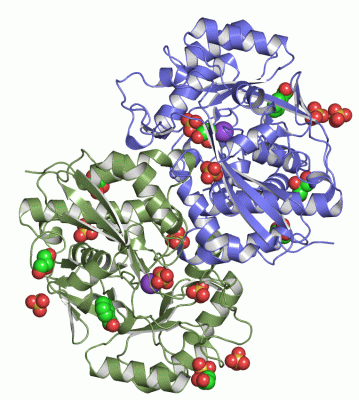
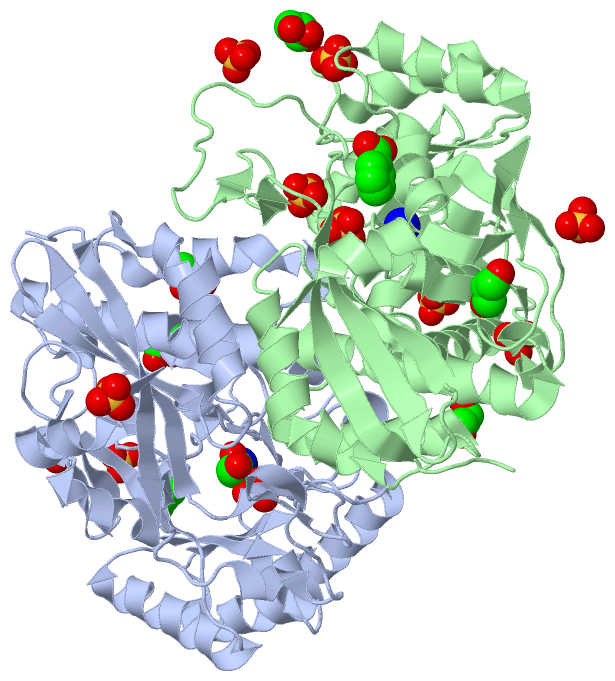
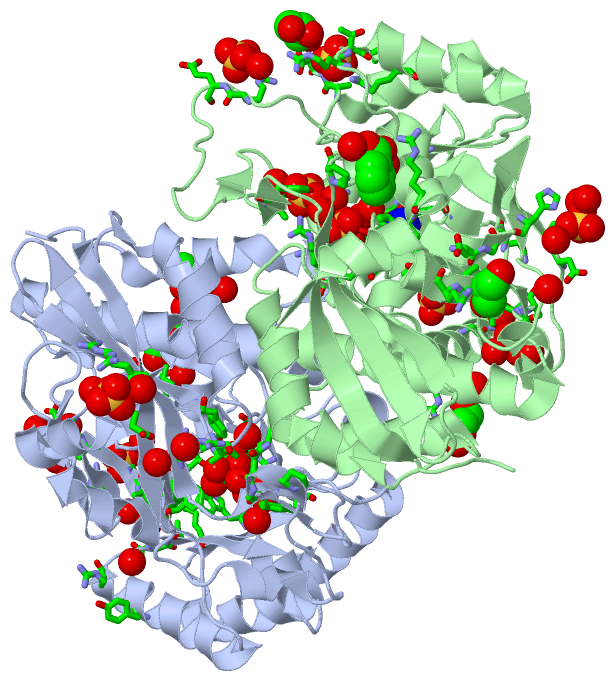
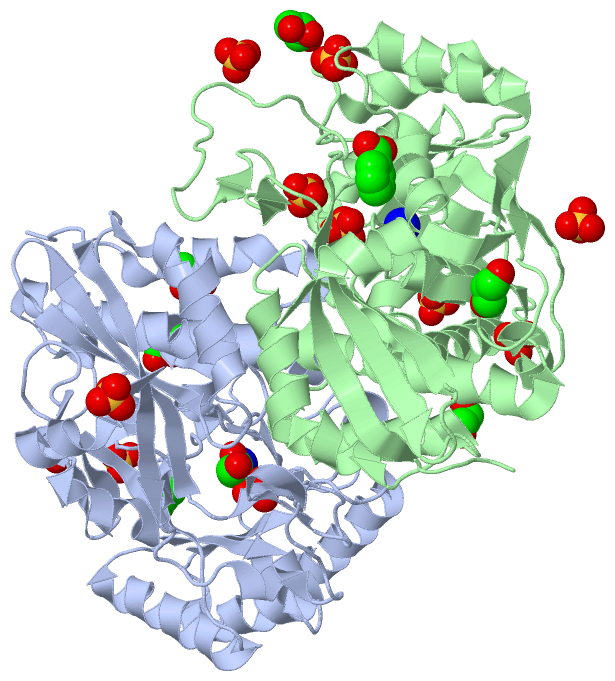
Ligands, Modified Residues, Ions (4, 21)
Asymmetric Unit (4, 21)
|
Sites (21, 21)
Asymmetric Unit (21, 21)
|
SS Bonds (0, 0)| (no "SS Bond" information available for 2NQL) |
Cis Peptide Bonds (0, 0)| (no "Cis Peptide Bond" information available for 2NQL) |
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 2NQL) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 2NQL) |
Exons (0, 0)| (no "Exon" information available for 2NQL) |
Sequences/Alignments
Asymmetric UnitChain A from PDB Type:PROTEIN Length:388 aligned with A9CL63_AGRFC | A9CL63 from UniProtKB/TrEMBL Length:388 Alignment length:388 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350 360 370 380 A9CL63_AGRFC 1 MNSPIATVEVFTLTQPRKVPYLGALREGEVVNPNGYIVRKGNRTVYPTFDRSVLVRMTTEAGTVGWGETYGIVAPGAVAALINDLLAGFVIGRDASDPSAVYDDLYDMMRVRGYTGGFYVDALAALDIALWDIAGQEAGKSIRDLLGGGVDSFPAYVSGLPERTLKARGELAKYWQDRGFNAFKFATPVADDGPAAEIANLRQVLGPQAKIAADMHWNQTPERALELIAEMQPFDPWFAEAPVWTEDIAGLEKVSKNTDVPIAVGEEWRTHWDMRARIERCRIAIVQPEMGHKGITNFIRIGALAAEHGIDVIPHATVGAGIFLAASLQASSTLSMLKGHEFQHSIFEPNRRLLDGDMDCREGRYHLPSGPGLGVRPSEAALGLIERI 388 SCOP domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SCOP domains CATH domains 2nqlA01 A:1-148,A:369-388 Enolase-like, N-terminal domain 2nqlA02 A:149-368 Enolase superfamily 2nqlA01 CATH domains Pfam domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2nql A 1 MNSPIATVEVFTLTQPRKVPYLGALREGEVVNPNGYIVRKGNRTVYPTFDRSVLVRMTTEAGTVGWGETYGIVAPGAVAALINDLLAGFVIGRDASDPSAVYDDLYDMMRVRGYTGGFYVDALAALDIALWDIAGQEAGKSIRDLLGGGVDSFPAYVSGLPERTLKARGELAKYWQDRGFNAFKFATPVADDGPAAEIANLRQVLGPQAKIAADMHWNQTPERALELIAEMQPFDPWFAEAPVWTEDIAGLEKVSKNTDVPIAVGEEWRTHWDMRARIERCRIAIVQPEMGHKGITNFIRIGALAAEHGIDVIPHATVGAGIFLAASLQASSTLSMLKGHEFQHSIFEPNRRLLDGDMDCREGRYHLPSGPGLGVRPSEAALGLIERI 388 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350 360 370 380 Chain B from PDB Type:PROTEIN Length:388 aligned with A9CL63_AGRFC | A9CL63 from UniProtKB/TrEMBL Length:388 Alignment length:388 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350 360 370 380 A9CL63_AGRFC 1 MNSPIATVEVFTLTQPRKVPYLGALREGEVVNPNGYIVRKGNRTVYPTFDRSVLVRMTTEAGTVGWGETYGIVAPGAVAALINDLLAGFVIGRDASDPSAVYDDLYDMMRVRGYTGGFYVDALAALDIALWDIAGQEAGKSIRDLLGGGVDSFPAYVSGLPERTLKARGELAKYWQDRGFNAFKFATPVADDGPAAEIANLRQVLGPQAKIAADMHWNQTPERALELIAEMQPFDPWFAEAPVWTEDIAGLEKVSKNTDVPIAVGEEWRTHWDMRARIERCRIAIVQPEMGHKGITNFIRIGALAAEHGIDVIPHATVGAGIFLAASLQASSTLSMLKGHEFQHSIFEPNRRLLDGDMDCREGRYHLPSGPGLGVRPSEAALGLIERI 388 SCOP domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SCOP domains CATH domains 2nqlB01 B:1-148,B:369-388 Enolase-like, N-terminal domain 2nqlB02 B:149-368 Enolase superfamily 2nqlB01 CATH domains Pfam domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2nql B 1 MNSPIATVEVFTLTQPRKVPYLGALREGEVVNPNGYIVRKGNRTVYPTFDRSVLVRMTTEAGTVGWGETYGIVAPGAVAALINDLLAGFVIGRDASDPSAVYDDLYDMMRVRGYTGGFYVDALAALDIALWDIAGQEAGKSIRDLLGGGVDSFPAYVSGLPERTLKARGELAKYWQDRGFNAFKFATPVADDGPAAEIANLRQVLGPQAKIAADMHWNQTPERALELIAEMQPFDPWFAEAPVWTEDIAGLEKVSKNTDVPIAVGEEWRTHWDMRARIERCRIAIVQPEMGHKGITNFIRIGALAAEHGIDVIPHATVGAGIFLAASLQASSTLSMLKGHEFQHSIFEPNRRLLDGDMDCREGRYHLPSGPGLGVRPSEAALGLIERI 388 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350 360 370 380
|
||||||||||||||||||||
SCOP Domains (0, 0)| (no "SCOP Domain" information available for 2NQL) |
CATH Domains (2, 4)
Asymmetric Unit
 |
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 2NQL) |
Gene Ontology (5, 5)|
Asymmetric Unit(hide GO term definitions) Chain A,B (A9CL63_AGRFC | A9CL63)
|
||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|