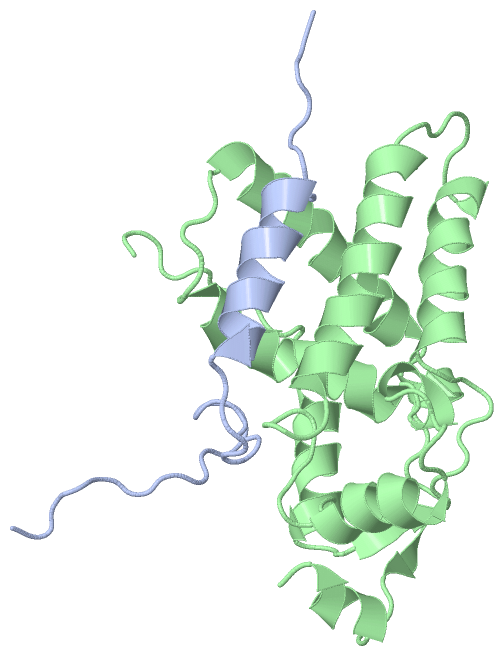
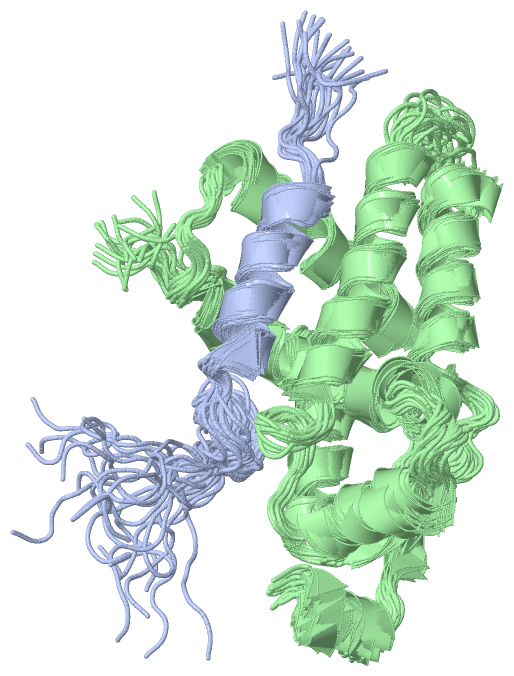
NMR Structure(hide GO term definitions)
Chain A ( PHF12_HUMAN | Q96QT6)
| molecular function |
|---|
| | GO:0000977 | | RNA polymerase II regulatory region sequence-specific DNA binding | | Interacting selectively and non-covalently with a specific sequence of DNA that is part of a regulatory region that controls the transcription of a gene or cistron by RNA polymerase II. |
| | GO:0001106 | | RNA polymerase II transcription corepressor activity | | Interacting selectively and non-covalently with an RNA polymerase II repressing transcription factor and also with the RNA polymerase II basal transcription machinery in order to stop, prevent, or reduce the frequency, rate or extent of transcription. Cofactors generally do not bind DNA, but rather mediate protein-protein interactions between repressive transcription factors and the basal transcription machinery. |
| | GO:0003682 | | chromatin binding | | Interacting selectively and non-covalently with chromatin, the network of fibers of DNA, protein, and sometimes RNA, that make up the chromosomes of the eukaryotic nucleus during interphase. |
| | GO:0042393 | | histone binding | | Interacting selectively and non-covalently with a histone, any of a group of water-soluble proteins found in association with the DNA of eukaroytic chromosomes. They are involved in the condensation and coiling of chromosomes during cell division and have also been implicated in nonspecific suppression of gene activity. |
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0035091 | | phosphatidylinositol binding | | Interacting selectively and non-covalently with any inositol-containing glycerophospholipid, i.e. phosphatidylinositol (PtdIns) and its phosphorylated derivatives. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0001222 | | transcription corepressor binding | | Interacting selectively and non-covalently with a transcription corepressor, any protein involved in negative regulation of transcription via protein-protein interactions with transcription factors and other proteins that negatively regulate transcription. Transcription corepressors do not bind DNA directly, but rather mediate protein-protein interactions between repressing transcription factors and the basal transcription machinery. |
| | GO:0008270 | | zinc ion binding | | Interacting selectively and non-covalently with zinc (Zn) ions. |
| biological process |
|---|
| | GO:0000122 | | negative regulation of transcription from RNA polymerase II promoter | | Any process that stops, prevents, or reduces the frequency, rate or extent of transcription from an RNA polymerase II promoter. |
| | GO:0045892 | | negative regulation of transcription, DNA-templated | | Any process that stops, prevents, or reduces the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0006355 | | regulation of transcription, DNA-templated | | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0006351 | | transcription, DNA-templated | | The cellular synthesis of RNA on a template of DNA. |
| cellular component |
|---|
| | GO:0016580 | | Sin3 complex | | A multiprotein complex that functions broadly in eukaryotic organisms as a transcriptional repressor of protein-coding genes, through the gene-specific deacetylation of histones. Amongst its subunits, the Sin3 complex contains Sin3-like proteins, and a number of core proteins that are shared with the NuRD complex (including histone deacetylases and histone binding proteins). The Sin3 complex does not directly bind DNA itself, but is targeted to specific genes through protein-protein interactions with DNA-binding proteins. |
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0017053 | | transcriptional repressor complex | | A protein complex that possesses activity that prevents or downregulates transcription. |
Chain B ( MO4L1_HUMAN | Q9UBU8)
| molecular function |
|---|
| | GO:0003682 | | chromatin binding | | Interacting selectively and non-covalently with chromatin, the network of fibers of DNA, protein, and sometimes RNA, that make up the chromosomes of the eukaryotic nucleus during interphase. |
| | GO:0047485 | | protein N-terminus binding | | Interacting selectively and non-covalently with a protein N-terminus, the end of any peptide chain at which the 2-amino (or 2-imino) function of a constituent amino acid is not attached in peptide linkage to another amino-acid residue. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| biological process |
|---|
| | GO:0006310 | | DNA recombination | | Any process in which a new genotype is formed by reassortment of genes resulting in gene combinations different from those that were present in the parents. In eukaryotes genetic recombination can occur by chromosome assortment, intrachromosomal recombination, or nonreciprocal interchromosomal recombination. Intrachromosomal recombination occurs by crossing over. In bacteria it may occur by genetic transformation, conjugation, transduction, or F-duction. |
| | GO:0006281 | | DNA repair | | The process of restoring DNA after damage. Genomes are subject to damage by chemical and physical agents in the environment (e.g. UV and ionizing radiations, chemical mutagens, fungal and bacterial toxins, etc.) and by free radicals or alkylating agents endogenously generated in metabolism. DNA is also damaged because of errors during its replication. A variety of different DNA repair pathways have been reported that include direct reversal, base excision repair, nucleotide excision repair, photoreactivation, bypass, double-strand break repair pathway, and mismatch repair pathway. |
| | GO:0008283 | | cell proliferation | | The multiplication or reproduction of cells, resulting in the expansion of a cell population. |
| | GO:0006974 | | cellular response to DNA damage stimulus | | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus indicating damage to its DNA from environmental insults or errors during metabolism. |
| | GO:0006338 | | chromatin remodeling | | Dynamic structural changes to eukaryotic chromatin occurring throughout the cell division cycle. These changes range from the local changes necessary for transcriptional regulation to global changes necessary for chromosome segregation. |
| | GO:0006342 | | chromatin silencing | | Repression of transcription by altering the structure of chromatin, e.g. by conversion of large regions of DNA into an inaccessible state often called heterochromatin. |
| | GO:0000724 | | double-strand break repair via homologous recombination | | The error-free repair of a double-strand break in DNA in which the broken DNA molecule is repaired using homologous sequences. A strand in the broken DNA searches for a homologous region in an intact chromosome to serve as the template for DNA synthesis. The restoration of two intact DNA molecules results in the exchange, reciprocal or nonreciprocal, of genetic material between the intact DNA molecule and the broken DNA molecule. |
| | GO:0043968 | | histone H2A acetylation | | The modification of histone H2A by the addition of an acetyl group. |
| | GO:0043967 | | histone H4 acetylation | | The modification of histone H4 by the addition of an acetyl group. |
| | GO:0016575 | | histone deacetylation | | The modification of histones by removal of acetyl groups. |
| | GO:0040008 | | regulation of growth | | Any process that modulates the frequency, rate or extent of the growth of all or part of an organism so that it occurs at its proper speed, either globally or in a specific part of the organism's development. |
| | GO:0006355 | | regulation of transcription, DNA-templated | | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0006351 | | transcription, DNA-templated | | The cellular synthesis of RNA on a template of DNA. |
| cellular component |
|---|
| | GO:0035267 | | NuA4 histone acetyltransferase complex | | A complex having histone acetylase activity on chromatin, as well as ATPase, DNA helicase and structural DNA binding activities. The complex is thought to be involved in double-strand DNA break repair. Subunits of the human complex include HTATIP/TIP60, TRRAP, RUVBL1, BUVBL2, beta-actin and BAF53/ACTL6A. In yeast, the complex has 13 subunits, including the catalytic subunit Esa1 (homologous to human Tip60). |
| | GO:0016580 | | Sin3 complex | | A multiprotein complex that functions broadly in eukaryotic organisms as a transcriptional repressor of protein-coding genes, through the gene-specific deacetylation of histones. Amongst its subunits, the Sin3 complex contains Sin3-like proteins, and a number of core proteins that are shared with the NuRD complex (including histone deacetylases and histone binding proteins). The Sin3 complex does not directly bind DNA itself, but is targeted to specific genes through protein-protein interactions with DNA-binding proteins. |
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
|
 Description
Description