| molecular function |
|---|
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0001103 | | RNA polymerase II repressing transcription factor binding | | Interacting selectively and non-covalently with an RNA polymerase II transcription repressing factor, a protein involved in negative regulation of transcription. |
| | GO:0001106 | | RNA polymerase II transcription corepressor activity | | Interacting selectively and non-covalently with an RNA polymerase II repressing transcription factor and also with the RNA polymerase II basal transcription machinery in order to stop, prevent, or reduce the frequency, rate or extent of transcription. Cofactors generally do not bind DNA, but rather mediate protein-protein interactions between repressive transcription factors and the basal transcription machinery. |
| | GO:0003684 | | damaged DNA binding | | Interacting selectively and non-covalently with damaged DNA. |
| | GO:0004519 | | endonuclease activity | | Catalysis of the hydrolysis of ester linkages within nucleic acids by creating internal breaks. |
| | GO:0016787 | | hydrolase activity | | Catalysis of the hydrolysis of various bonds, e.g. C-O, C-N, C-C, phosphoric anhydride bonds, etc. Hydrolase is the systematic name for any enzyme of EC class 3. |
| | GO:0004518 | | nuclease activity | | Catalysis of the hydrolysis of ester linkages within nucleic acids. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0000014 | | single-stranded DNA endodeoxyribonuclease activity | | Catalysis of the hydrolysis of ester linkages within a single-stranded deoxyribonucleic acid molecule by creating internal breaks. |
| biological process |
|---|
| | GO:0000077 | | DNA damage checkpoint | | A cell cycle checkpoint that regulates progression through the cell cycle in response to DNA damage. A DNA damage checkpoint may blocks cell cycle progression (in G1, G2 or metaphase) or slow the rate at which S phase proceeds. |
| | GO:0000729 | | DNA double-strand break processing | | The 5' to 3' exonucleolytic resection of the DNA at the site of the break to form a 3' single-strand DNA overhang. |
| | GO:0010792 | | DNA double-strand break processing involved in repair via single-strand annealing | | The 5' to 3' exonucleolytic resection of the DNA at the site of the break to form a 3' single-strand DNA overhang that results in the repair of a double strand break via single-strand annealing. |
| | GO:0006281 | | DNA repair | | The process of restoring DNA after damage. Genomes are subject to damage by chemical and physical agents in the environment (e.g. UV and ionizing radiations, chemical mutagens, fungal and bacterial toxins, etc.) and by free radicals or alkylating agents endogenously generated in metabolism. DNA is also damaged because of errors during its replication. A variety of different DNA repair pathways have been reported that include direct reversal, base excision repair, nucleotide excision repair, photoreactivation, bypass, double-strand break repair pathway, and mismatch repair pathway. |
| | GO:0006260 | | DNA replication | | The cellular metabolic process in which a cell duplicates one or more molecules of DNA. DNA replication begins when specific sequences, known as origins of replication, are recognized and bound by initiation proteins, and ends when the original DNA molecule has been completely duplicated and the copies topologically separated. The unit of replication usually corresponds to the genome of the cell, an organelle, or a virus. The template for replication can either be an existing DNA molecule or RNA. |
| | GO:0000731 | | DNA synthesis involved in DNA repair | | Synthesis of DNA that proceeds from the broken 3' single-strand DNA end and uses the homologous intact duplex as the template. |
| | GO:0000082 | | G1/S transition of mitotic cell cycle | | The mitotic cell cycle transition by which a cell in G1 commits to S phase. The process begins with the build up of G1 cyclin-dependent kinase (G1 CDK), resulting in the activation of transcription of G1 cyclins. The process ends with the positive feedback of the G1 cyclins on the G1 CDK which commits the cell to S phase, in which DNA replication is initiated. |
| | GO:0031572 | | G2 DNA damage checkpoint | | A cell cycle checkpoint that detects and negatively regulates progression from G2 to M phase in the cell cycle in response to DNA damage. |
| | GO:0001835 | | blastocyst hatching | | The hatching of the cellular blastocyst from the zona pellucida. |
| | GO:0007049 | | cell cycle | | The progression of biochemical and morphological phases and events that occur in a cell during successive cell replication or nuclear replication events. Canonically, the cell cycle comprises the replication and segregation of genetic material followed by the division of the cell, but in endocycles or syncytial cells nuclear replication or nuclear division may not be followed by cell division. |
| | GO:0000075 | | cell cycle checkpoint | | A cell cycle process that controls cell cycle progression by monitoring the integrity of specific cell cycle events. A cell cycle checkpoint begins with detection of deficiencies or defects and ends with signal transduction. |
| | GO:0051301 | | cell division | | The process resulting in division and partitioning of components of a cell to form more cells; may or may not be accompanied by the physical separation of a cell into distinct, individually membrane-bounded daughter cells. |
| | GO:0006974 | | cellular response to DNA damage stimulus | | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus indicating damage to its DNA from environmental insults or errors during metabolism. |
| | GO:0000724 | | double-strand break repair via homologous recombination | | The error-free repair of a double-strand break in DNA in which the broken DNA molecule is repaired using homologous sequences. A strand in the broken DNA searches for a homologous region in an intact chromosome to serve as the template for DNA synthesis. The restoration of two intact DNA molecules results in the exchange, reciprocal or nonreciprocal, of genetic material between the intact DNA molecule and the broken DNA molecule. |
| | GO:0051321 | | meiotic cell cycle | | Progression through the phases of the meiotic cell cycle, in which canonically a cell replicates to produce four offspring with half the chromosomal content of the progenitor cell via two nuclear divisions. |
| | GO:0000122 | | negative regulation of transcription from RNA polymerase II promoter | | Any process that stops, prevents, or reduces the frequency, rate or extent of transcription from an RNA polymerase II promoter. |
| | GO:0090305 | | nucleic acid phosphodiester bond hydrolysis | | The nucleic acid metabolic process in which the phosphodiester bonds between nucleotides are cleaved by hydrolysis. |
| | GO:0006289 | | nucleotide-excision repair | | A DNA repair process in which a small region of the strand surrounding the damage is removed from the DNA helix as an oligonucleotide. The small gap left in the DNA helix is filled in by the sequential action of DNA polymerase and DNA ligase. Nucleotide excision repair recognizes a wide range of substrates, including damage caused by UV irradiation (pyrimidine dimers and 6-4 photoproducts) and chemicals (intrastrand cross-links and bulky adducts). |
| | GO:1901796 | | regulation of signal transduction by p53 class mediator | | Any process that modulates the frequency, rate or extent of signal transduction by p53 class mediator. |
| | GO:0006357 | | regulation of transcription from RNA polymerase II promoter | | Any process that modulates the frequency, rate or extent of transcription from an RNA polymerase II promoter. |
| | GO:0032355 | | response to estradiol | | Any process that results in a change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of stimulus by estradiol, a C18 steroid hormone hydroxylated at C3 and C17 that acts as a potent estrogen. |
| | GO:0000732 | | strand displacement | | The rejection of the broken 3' single-strand DNA molecule that formed heteroduplex DNA with its complement in an intact duplex DNA. The Watson-Crick base pairing in the original duplex is restored. The rejected 3' single-strand DNA molecule reanneals with its original complement to reform two intact duplex molecules. |
| cellular component |
|---|
| | GO:0005694 | | chromosome | | A structure composed of a very long molecule of DNA and associated proteins (e.g. histones) that carries hereditary information. |
| | GO:0005730 | | nucleolus | | A small, dense body one or more of which are present in the nucleus of eukaryotic cells. It is rich in RNA and protein, is not bounded by a limiting membrane, and is not seen during mitosis. Its prime function is the transcription of the nucleolar DNA into 45S ribosomal-precursor RNA, the processing of this RNA into 5.8S, 18S, and 28S components of ribosomal RNA, and the association of these components with 5S RNA and proteins synthesized outside the nucleolus. This association results in the formation of ribonucleoprotein precursors; these pass into the cytoplasm and mature into the 40S and 60S subunits of the ribosome. |
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0017053 | | transcriptional repressor complex | | A protein complex that possesses activity that prevents or downregulates transcription. |
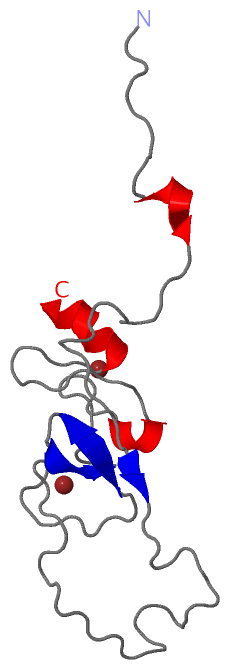
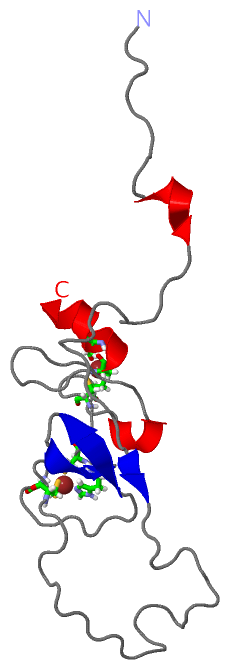
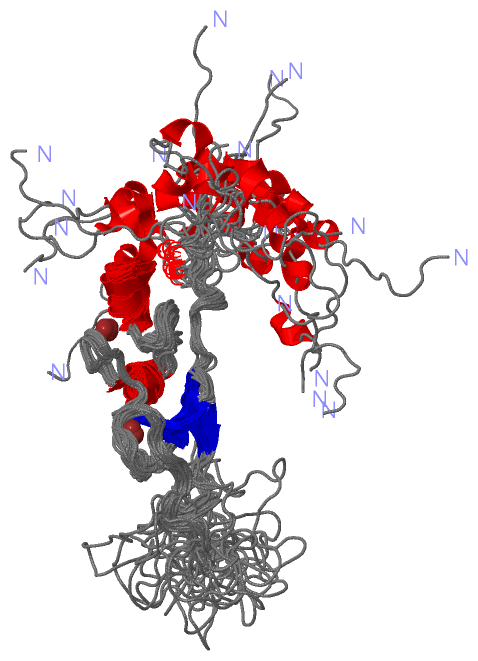
 Description
Description