|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (0, 0)| (no "Ligand,Modified Residues,Ions" information available for 2EQN) |
Sites (0, 0)| (no "Site" information available for 2EQN) |
SS Bonds (0, 0)| (no "SS Bond" information available for 2EQN) |
Cis Peptide Bonds (0, 0)| (no "Cis Peptide Bond" information available for 2EQN) |
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 2EQN) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 2EQN) |
Exons (4, 4)
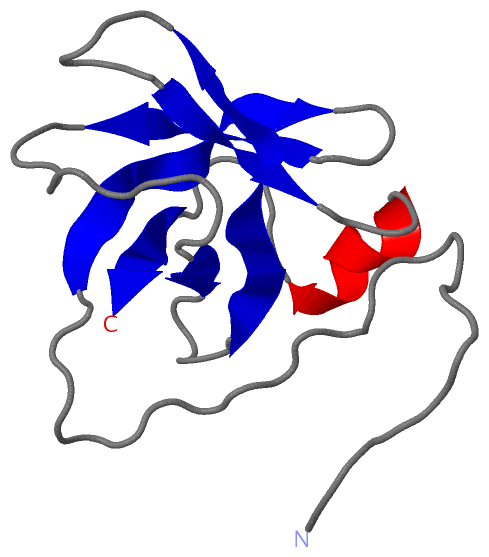
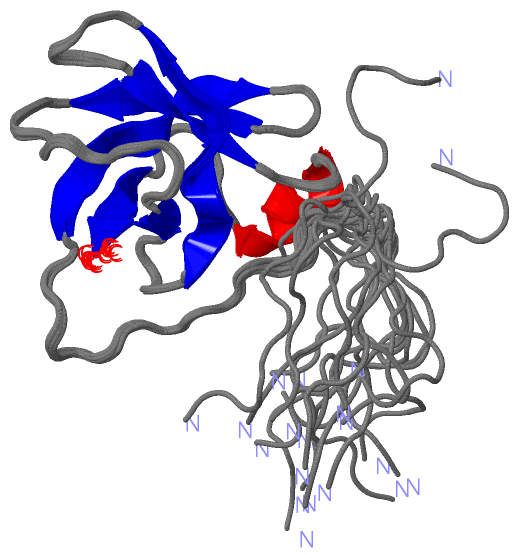
NMR Structure (4, 4)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sequences/Alignments
NMR StructureChain A from PDB Type:PROTEIN Length:103 aligned with NAF1_HUMAN | Q96HR8 from UniProtKB/Swiss-Prot Length:494 Alignment length:138 148 158 168 178 188 198 208 218 228 238 248 258 268 NAF1_HUMAN 139 SSSSSSSCISLPPVLSDGDDDLQIEKENKNFPLKTKDELLLNELPSVEELTIILPEDIELKPLGMVSSIIEQLVIIESMTNLPPVNEETVIFKSDRQAAGKIFEIFGPVAHPFYVLRFNSSDHIESKGIKIKETMYFA 276 SCOP domains ------------------------------------------------------------------------------------------------------------------------------------------ SCOP domains CATH domains ------------------------------------------------------------------------------------------------------------------------------------------ CATH domains Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------ Pfam domains SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------ SAPs(SNPs) PROSITE ------------------------------------------------------------------------------------------------------------------------------------------ PROSITE Transcript 1 (1) Exon 1.2 PDB: A:1-7 (gaps) [INCOMPLETE] Exon 1.5 PDB: A:8-39 ---------------------------Exon 1.7a PDB: A:67-103 [INCOMPLETE] Transcript 1 (1) Transcript 1 (2) -------------------------------------------------------------------------Exon 1.6 PDB: A:39-66 ------------------------------------- Transcript 1 (2) 2eqn A 1 GSSGSS-----------G------------------------ELPSVEELTIILPEDIELKPLGMVSSIIEQLVIIESMTNLPPVNEETVIFKSDRQAAGKIFEIFGPVAHPFYVLRFNSSDHIESKGIKIKETMYFA 103 | - | - - - | 15 25 35 45 55 65 75 85 95 6 7 8
|
||||||||||||||||||||
SCOP Domains (0, 0)| (no "SCOP Domain" information available for 2EQN) |
CATH Domains (0, 0)| (no "CATH Domain" information available for 2EQN) |
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 2EQN) |
Gene Ontology (11, 11)|
NMR Structure(hide GO term definitions) Chain A (NAF1_HUMAN | Q96HR8)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|