| molecular function |
|---|
| | GO:0003723 | | RNA binding | | Interacting selectively and non-covalently with an RNA molecule or a portion thereof. |
| | GO:0033592 | | RNA strand annealing activity | | Facilitates the base-pairing of complementary single-stranded RNA. |
| | GO:0034057 | | RNA strand-exchange activity | | Facilitates the displacement of one strand of an RNA-RNA duplex and its replacement with a different strand of higher complementarity. |
| | GO:0003676 | | nucleic acid binding | | Interacting selectively and non-covalently with any nucleic acid. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| | GO:0043024 | | ribosomal small subunit binding | | Interacting selectively and non-covalently with any part of the small ribosomal subunit. |
| | GO:0003743 | | translation initiation factor activity | | Functions in the initiation of ribosome-mediated translation of mRNA into a polypeptide. |
| biological process |
|---|
| | GO:0002181 | | cytoplasmic translation | | The chemical reactions and pathways resulting in the formation of a protein in the cytoplasm. This is a ribosome-mediated process in which the information in messenger RNA (mRNA) is used to specify the sequence of amino acids in the protein. |
| | GO:0048589 | | developmental growth | | The increase in size or mass of an entire organism, a part of an organism or a cell, where the increase in size or mass has the specific outcome of the progression of the organism over time from one condition to another. |
| | GO:0097010 | | eukaryotic translation initiation factor 4F complex assembly | | The aggregation, arrangement and bonding together of a set of components to form the eukaryotic translation initiation factor 4F complex. |
| | GO:0001731 | | formation of translation preinitiation complex | | The joining of the small ribosomal subunit, ternary complex, and mRNA. |
| | GO:0019953 | | sexual reproduction | | A reproduction process that creates a new organism by combining the genetic material of two organisms. It occurs both in eukaryotes and prokaryotes: in multicellular eukaryotic organisms, an individual is created anew; in prokaryotes, the initial cell has additional or transformed genetic material. In a process called genetic recombination, genetic material (DNA) originating from two different individuals (parents) join up so that homologous sequences are aligned with each other, and this is followed by exchange of genetic information. After the new recombinant chromosome is formed, it is passed on to progeny. |
| | GO:0006412 | | translation | | The cellular metabolic process in which a protein is formed, using the sequence of a mature mRNA or circRNA molecule to specify the sequence of amino acids in a polypeptide chain. Translation is mediated by the ribosome, and begins with the formation of a ternary complex between aminoacylated initiator methionine tRNA, GTP, and initiation factor 2, which subsequently associates with the small subunit of the ribosome and an mRNA or circRNA. Translation ends with the release of a polypeptide chain from the ribosome. |
| | GO:0006413 | | translational initiation | | The process preceding formation of the peptide bond between the first two amino acids of a protein. This includes the formation of a complex of the ribosome, mRNA or circRNA, and an initiation complex that contains the first aminoacyl-tRNA. |
| cellular component |
|---|
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0016281 | | eukaryotic translation initiation factor 4F complex | | The eukaryotic translation initiation factor 4F complex is composed of eIF4E, eIF4A and eIF4G; it is involved in the recognition of the mRNA cap, ATP-dependent unwinding of the 5'-terminal secondary structure and recruitment of the mRNA to the ribosome. |
| | GO:0016020 | | membrane | | A lipid bilayer along with all the proteins and protein complexes embedded in it an attached to it. |
| | GO:0048471 | | perinuclear region of cytoplasm | | Cytoplasm situated near, or occurring around, the nucleus. |
| | GO:0005844 | | polysome | | A multiribosomal structure representing a linear array of ribosomes held together by messenger RNA. They represent the active complexes in cellular protein synthesis and are able to incorporate amino acids into polypeptides both in vivo and in vitro. |
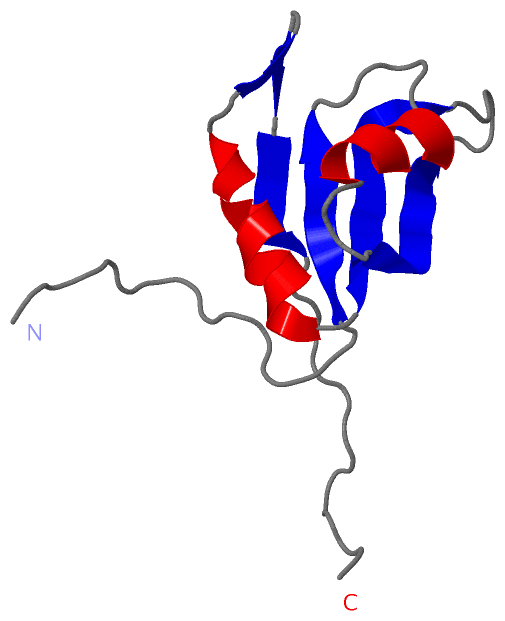
 Description
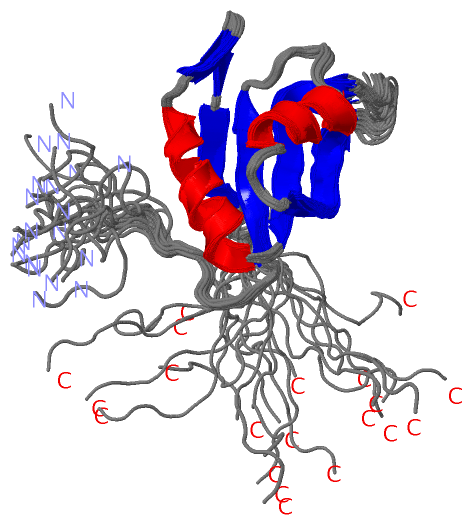
Description