|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||
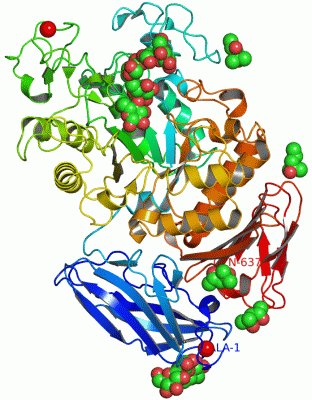
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (4, 15)| Asymmetric/Biological Unit (4, 15) |
Sites (15, 15)
Asymmetric Unit (15, 15)
|
SS Bonds (0, 0)| (no "SS Bond" information available for 2D0F) |
Cis Peptide Bonds (3, 3)
Asymmetric/Biological Unit
|
||||||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 2D0F) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 2D0F) |
Exons (0, 0)| (no "Exon" information available for 2D0F) |
Sequences/Alignments
Asymmetric/Biological UnitChain A from PDB Type:PROTEIN Length:637 aligned with NEPU1_THEVU | Q60053 from UniProtKB/Swiss-Prot Length:666 Alignment length:637 39 49 59 69 79 89 99 109 119 129 139 149 159 169 179 189 199 209 219 229 239 249 259 269 279 289 299 309 319 329 339 349 359 369 379 389 399 409 419 429 439 449 459 469 479 489 499 509 519 529 539 549 559 569 579 589 599 609 619 629 639 649 659 NEPU1_THEVU 30 AANDNNVEWNGLFHDQGPLFDNAPEPTSTQSVTLKLRTFKGDITSANIKYWDTADNAFHWVPMVWDSNDPTGTFDYWKGTIPASPSIKYYRFQINDGTSTAWYNGNGPSSTEPNADDFYIIPNFKTPDWLKNGVMYQIFPDRFYNGDSSNDVQTGSYTYNGTPTEKKAWGSSVYADPGYDNSLVFFGGDLAGIDQKLGYIKKTLGANILYLNPIFKAPTNHKYDTQDYMAVDPAFGDNSTLQTLINDIHSTANGPKGYLILDGVFNHTGDSHPWFDKYNNFSSQGAYESQSSPWYNYYTFYTWPDSYASFLGFNSLPKLNYGNSGSAVRGVIYNNSNSVAKTYLNPPYSVDGWRLDAAQYVDANGNNGSDVTNHQIWSEFRNAVKGVNSNAAIIGEYWGNANPWTAQGNQWDAATNFDGFTQPVSEWITGKDYQNNSASISTTQFDSWLRGTRANYPTNVQQSMMNFLSNHDITRFATRSGGDLWKTYLALIFQMTYVGTPTIYYGDEYGMQGGADPDNRRSFDWSQATPSNSAVALTQKLITIRNQYPALRTGSFMTLITDDTNKIYSYGRFDNVNRIAVVLNNDSVSHTVNVPVWQLSMPNGSTVTDKITGHSYTVQNGMVTVAVDGHYGAVLAQ 666 SCOP domains d2d0fa1 A:1-122 automated matches d2d0fa3 A:123-554 automated matches d2d0fa2 A:555-637 automated matches SCOP domains CATH domains 2d0fA01 A:1-124 Immunoglobulins 2d0fA02 A:125-547 Glycosidases 2d0fA03 A:548-637 Golgi alpha-mannosidase II CATH domains Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2d0f A 1 AANDNNVEWNGLFHDQGPLFDNAPEPTSTQSVTLKLRTFKGDITSANIKYWDTADNAFHWVPMVWDSNDPTGTFDYWKGTIPASPSIKYYRFQINDGTSTAWYNGNGPSSTEPNADDFYIIPNFKTPDWLKNGVMYQIFPDRFYNGDSSNDVQTGSYTYNGTPTEKKAWGSSVYADPGYDNSLVFFGGDLAGIDQKLGYIKKTLGANILYLNPIFKAPTNHKYDTQDYMAVDPAFGDNSTLQTLINDIHSTANGPKGYLILDGVFNHTGDSHPWFDKYNNFSSQGAYESQSSPWYNYYTFYTWPDSYASFLGFNSLPKLNYGNSGSAVRGVIYNNSNSVAKTYLNPPYSVDGWRLNAAQYVDANGNNGSDVTNHQIWSEFRNAVKGVNSNAAIIGEYWGNANPWTAQGNQWDAATNFDGFTQPVSEWITGKDYQNNSASISTTQFDSWLRGTRANYPTNVQQSMMNFLSNHDITRFATRSGGDLWKTYLALIFQMTYVGTPTIYYGDEYGMQGGADPDNRRSFDWSQATPSNSAVALTQKLITIRNQYPALRTGSFMTLITDDTNKIYSYGRFDNVNRIAVVLNNDSVSHTVNVPVWQLSMPNGSTVTDKITGHSYTVQNGMVTVAVDGHYGAVLAQ 637 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350 360 370 380 390 400 410 420 430 440 450 460 470 480 490 500 510 520 530 540 550 560 570 580 590 600 610 620 630
|
||||||||||||||||||||
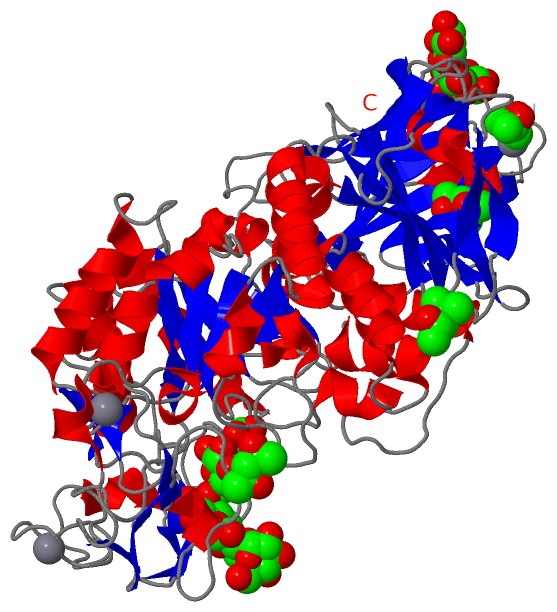
SCOP Domains (3, 3)
Asymmetric/Biological Unit

|
CATH Domains (3, 3)
Asymmetric/Biological Unit
|
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 2D0F) |
Gene Ontology (9, 9)|
Asymmetric/Biological Unit(hide GO term definitions) Chain A (NEPU1_THEVU | Q60053)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
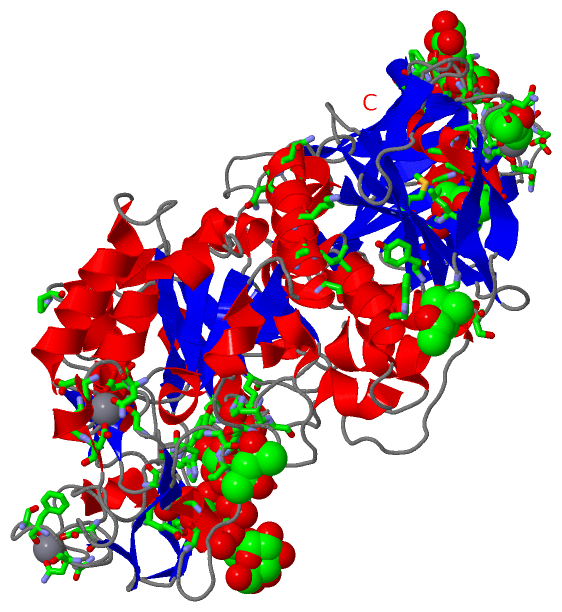
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|