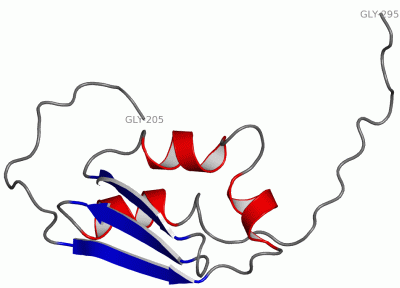
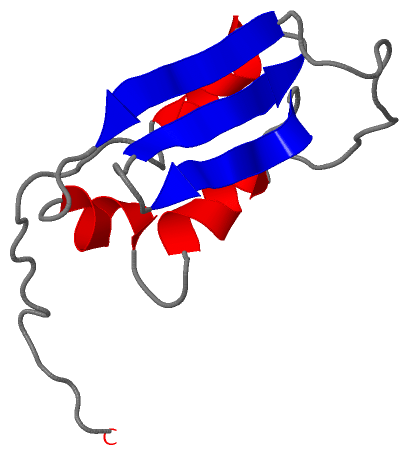
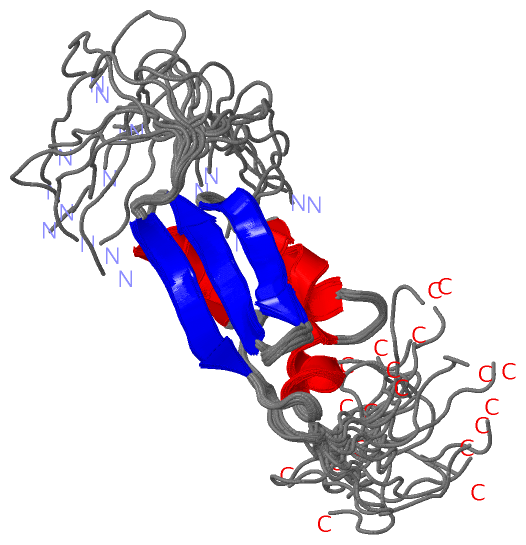
| molecular function |
|---|
| | GO:0002151 | | G-quadruplex RNA binding | | Interacting selectively and non-covalently with G-quadruplex RNA structures, in which groups of four guanines adopt a flat, cyclic hydrogen-bonding arrangement known as a guanine tetrad. |
| | GO:0003723 | | RNA binding | | Interacting selectively and non-covalently with an RNA molecule or a portion thereof. |
| | GO:0033592 | | RNA strand annealing activity | | Facilitates the base-pairing of complementary single-stranded RNA. |
| | GO:0003730 | | mRNA 3'-UTR binding | | Interacting selectively and non-covalently with the 3' untranslated region of an mRNA molecule. |
| | GO:0003729 | | mRNA binding | | Interacting selectively and non-covalently with messenger RNA (mRNA), an intermediate molecule between DNA and protein. mRNA includes UTR and coding sequences, but does not contain introns. |
| | GO:0003676 | | nucleic acid binding | | Interacting selectively and non-covalently with any nucleic acid. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0046982 | | protein heterodimerization activity | | Interacting selectively and non-covalently with a nonidentical protein to form a heterodimer. |
| | GO:0042803 | | protein homodimerization activity | | Interacting selectively and non-covalently with an identical protein to form a homodimer. |
| biological process |
|---|
| | GO:0006915 | | apoptotic process | | A programmed cell death process which begins when a cell receives an internal (e.g. DNA damage) or external signal (e.g. an extracellular death ligand), and proceeds through a series of biochemical events (signaling pathway phase) which trigger an execution phase. The execution phase is the last step of an apoptotic process, and is typically characterized by rounding-up of the cell, retraction of pseudopodes, reduction of cellular volume (pyknosis), chromatin condensation, nuclear fragmentation (karyorrhexis), plasma membrane blebbing and fragmentation of the cell into apoptotic bodies. When the execution phase is completed, the cell has died. |
| | GO:0030154 | | cell differentiation | | The process in which relatively unspecialized cells, e.g. embryonic or regenerative cells, acquire specialized structural and/or functional features that characterize the cells, tissues, or organs of the mature organism or some other relatively stable phase of the organism's life history. Differentiation includes the processes involved in commitment of a cell to a specific fate and its subsequent development to the mature state. |
| | GO:0007275 | | multicellular organism development | | The biological process whose specific outcome is the progression of a multicellular organism over time from an initial condition (e.g. a zygote or a young adult) to a later condition (e.g. a multicellular animal or an aged adult). |
| | GO:0007517 | | muscle organ development | | The process whose specific outcome is the progression of the muscle over time, from its formation to the mature structure. The muscle is an organ consisting of a tissue made up of various elongated cells that are specialized to contract and thus to produce movement and mechanical work. |
| | GO:0017148 | | negative regulation of translation | | Any process that stops, prevents, or reduces the frequency, rate or extent of the chemical reactions and pathways resulting in the formation of proteins by the translation of mRNA or circRNA. |
| | GO:2000637 | | positive regulation of gene silencing by miRNA | | Any process that activates or increases the frequency, rate or extent of gene silencing by miRNA. |
| cellular component |
|---|
| | GO:0030424 | | axon | | The long process of a neuron that conducts nerve impulses, usually away from the cell body to the terminals and varicosities, which are sites of storage and release of neurotransmitter. |
| | GO:0043034 | | costamere | | Regular periodic sub membranous arrays of vinculin in skeletal and cardiac muscle cells, these arrays link Z-discs to the sarcolemma and are associated with links to extracellular matrix. |
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0030425 | | dendrite | | A neuron projection that has a short, tapering, often branched, morphology, receives and integrates signals from other neurons or from sensory stimuli, and conducts a nerve impulse towards the axon or the cell body. In most neurons, the impulse is conveyed from dendrites to axon via the cell body, but in some types of unipolar neuron, the impulse does not travel via the cell body. |
| | GO:0043197 | | dendritic spine | | A small, membranous protrusion from a dendrite that forms a postsynaptic compartment - typically receiving input from a single presynapse. They function as partially isolated biochemical and an electrical compartments. Spine morphology is variable including "thin", "stubby", "mushroom", and "branched", with a continuum of intermediate morphologies. They typically terminate in a bulb shape, linked to the dendritic shaft by a restriction. Spine remodeling is though to be involved in synaptic plasticity. |
| | GO:0016020 | | membrane | | A lipid bilayer along with all the proteins and protein complexes embedded in it an attached to it. |
| | GO:0005730 | | nucleolus | | A small, dense body one or more of which are present in the nucleus of eukaryotic cells. It is rich in RNA and protein, is not bounded by a limiting membrane, and is not seen during mitosis. Its prime function is the transcription of the nucleolar DNA into 45S ribosomal-precursor RNA, the processing of this RNA into 5.8S, 18S, and 28S components of ribosomal RNA, and the association of these components with 5S RNA and proteins synthesized outside the nucleolus. This association results in the formation of ribonucleoprotein precursors; these pass into the cytoplasm and mature into the 40S and 60S subunits of the ribosome. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0048471 | | perinuclear region of cytoplasm | | Cytoplasm situated near, or occurring around, the nucleus. |
| | GO:0005844 | | polysome | | A multiribosomal structure representing a linear array of ribosomes held together by messenger RNA. They represent the active complexes in cellular protein synthesis and are able to incorporate amino acids into polypeptides both in vivo and in vitro. |
| | GO:0035770 | | ribonucleoprotein granule | | A non-membranous macromolecular complex containing proteins and translationally silenced mRNAs. RNA granules contain proteins that control the localization, stability, and translation of their RNA cargo. Different types of RNA granules (RGs) exist, depending on the cell type and cellular conditions. |
 Description
Description