| molecular function |
|---|
| | GO:0003723 | | RNA binding | | Interacting selectively and non-covalently with an RNA molecule or a portion thereof. |
| | GO:0016874 | | ligase activity | | Catalysis of the joining of two substances, or two groups within a single molecule, with the concomitant hydrolysis of the diphosphate bond in ATP or a similar triphosphate. |
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0003676 | | nucleic acid binding | | Interacting selectively and non-covalently with any nucleic acid. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| | GO:0004842 | | ubiquitin-protein transferase activity | | Catalysis of the transfer of ubiquitin from one protein to another via the reaction X-Ub + Y --> Y-Ub + X, where both X-Ub and Y-Ub are covalent linkages. |
| | GO:0008270 | | zinc ion binding | | Interacting selectively and non-covalently with zinc (Zn) ions. |
| biological process |
|---|
| | GO:0051865 | | protein autoubiquitination | | The ubiquitination by a protein of one or more of its own amino acid residues, or residues on an identical protein. Ubiquitination occurs on the lysine residue by formation of an isopeptide crosslink. |
| | GO:0016567 | | protein ubiquitination | | The process in which one or more ubiquitin groups are added to a protein. |
| | GO:0006355 | | regulation of transcription, DNA-templated | | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0006351 | | transcription, DNA-templated | | The cellular synthesis of RNA on a template of DNA. |
| cellular component |
|---|
| | GO:0030014 | | CCR4-NOT complex | | The evolutionarily conserved CCR4-NOT complex is involved in several aspects of mRNA metabolism, including repression and activation of mRNA initiation, control of mRNA elongation, and the deadenylation and subsequent degradation of mRNA. In Saccharomyces the CCR4-NOT complex comprises a core complex of 9 proteins (Ccr4p, Caf1p, Caf40p, Caf130p, Not1p, Not2p, Not3p, Not4p, and Not5p), Caf4p, Caf16p, and several less well characterized proteins. |
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
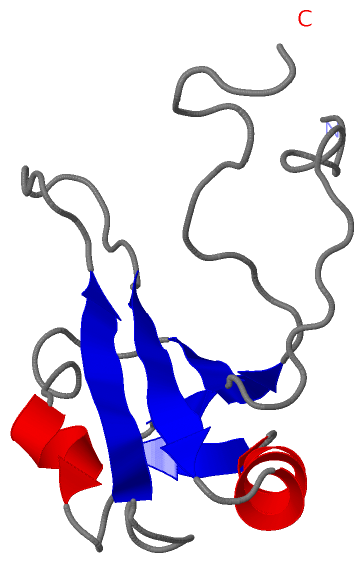
 Description
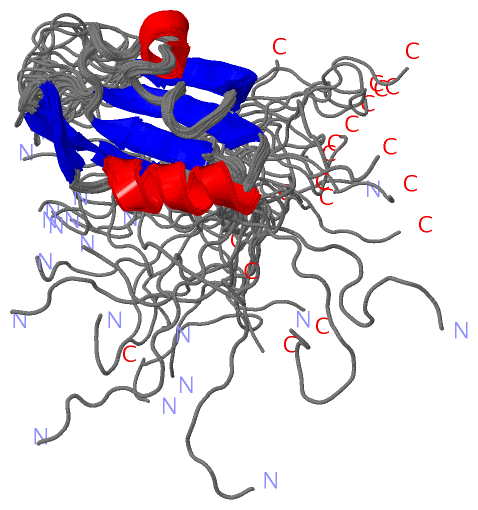
Description