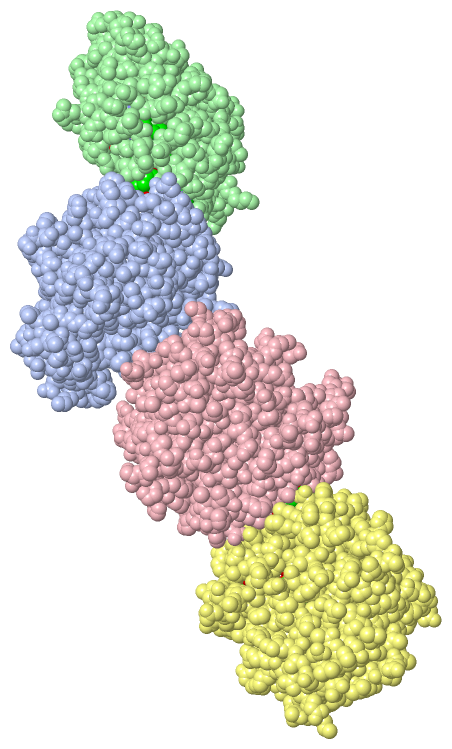
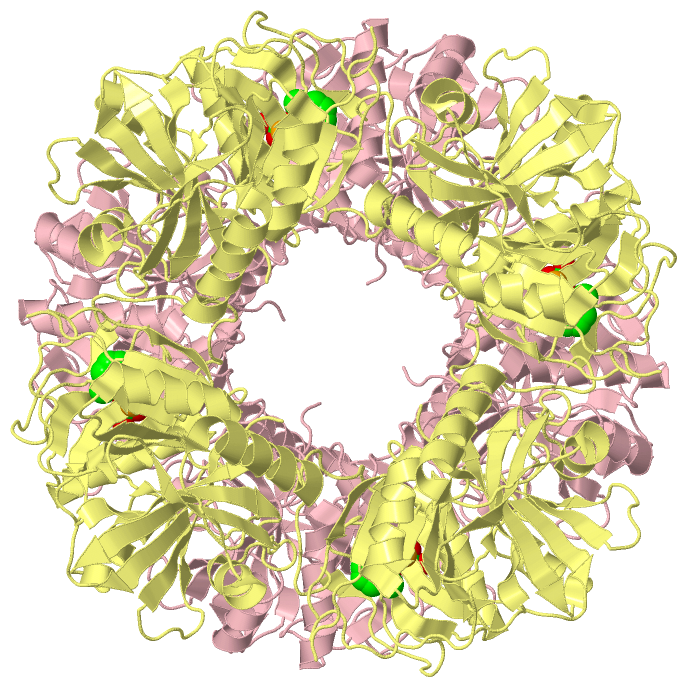
|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (4, 10)
Asymmetric Unit (4, 10)
|
Sites (10, 10)
Asymmetric Unit (10, 10)
|
SS Bonds (0, 0)| (no "SS Bond" information available for 2WL9) |
Cis Peptide Bonds (0, 0)| (no "Cis Peptide Bond" information available for 2WL9) |
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 2WL9) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 2WL9) |
Exons (0, 0)| (no "Exon" information available for 2WL9) |
Sequences/Alignments
Asymmetric UnitChain A from PDB Type:PROTEIN Length:300 aligned with Q6REQ5_9NOCA | Q6REQ5 from UniProtKB/TrEMBL Length:305 Alignment length:300 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 Q6REQ5_9NOCA 1 MAKVTELGYLGLSVSNLDAWRDYAAGIMGMQVVDDGEDDRIYLRMDRWHHRIVLHADGSDDLAYIGWRVAGPVELDELAEQLKNAGIPFEVASDADAAERRVLGLVKLHDPGGNPTEIFYGPQVDTSSPFHPGRPMFGKFVTEGQGLGHIIIREDDVEEATRFYRLLGLEGAVEYKFALPNGAVGTPVFMHCNDRHHSLAFGVGPMDKRINHLMIEYTHLDDLGYAHDLVRQQKIDVTLQIGKHSNDEALTFYCANPSGWLWEPGWGSRPAPAQQEHYLRDIFGHDNEVEGYGLDIPLKG 300 SCOP domains d2wl9a1 A:1-134 automated matches d2wl9a2 A:135-300 automated matches SCOP domains CATH domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ CATH domains Pfam domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Pfam domains SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SAPs(SNPs) PROSITE ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ PROSITE Transcript ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Transcript 2wl9 A 1 MAKVTELGYLGLSVSNLDAWRDYAAGIMGMQVVDDGEDDRIYLRMDRWHHRIVLHADGSDDLAYIGWRVAGPVELDELAEQLKNAGIPFEVASDADAAERRVLGLVKLHDPGGNPTEIFYGPQVDTSSPFHPGRPMFGKFVTEGQGLGHIIIREDDVEEATRFYRLLGLEGAVEYKFALPNGAVGTPVFMHCNDRHHSLAFGVGPMDKRINHLMIEYTHLDDLGYAHDLVRQQKIDVTLQIGKHSNDEALTFYCANPSGWLWEPGWGSRPAPAQQEHYLRDIFGHDNEVEGYGLDIPLKG 300 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 Chain B from PDB Type:PROTEIN Length:293 aligned with Q6REQ5_9NOCA | Q6REQ5 from UniProtKB/TrEMBL Length:305 Alignment length:298 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 Q6REQ5_9NOCA 2 AKVTELGYLGLSVSNLDAWRDYAAGIMGMQVVDDGEDDRIYLRMDRWHHRIVLHADGSDDLAYIGWRVAGPVELDELAEQLKNAGIPFEVASDADAAERRVLGLVKLHDPGGNPTEIFYGPQVDTSSPFHPGRPMFGKFVTEGQGLGHIIIREDDVEEATRFYRLLGLEGAVEYKFALPNGAVGTPVFMHCNDRHHSLAFGVGPMDKRINHLMIEYTHLDDLGYAHDLVRQQKIDVTLQIGKHSNDEALTFYCANPSGWLWEPGWGSRPAPAQQEHYLRDIFGHDNEVEGYGLDIPLK 299 SCOP domains d2wl9b1 B:2-134 automated matches d2wl9b2 B:135-299 automated matches SCOP domains CATH domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2wl9 B 2 AKVTELGYLGLSVSNLDAWRDYAAGIMGMQVVDDGEDDRIYLRMDRWHHRIVLHADGSDDLAYIGWRVAGPVELDELAEQLKNAGIPFEVASDADAAERRVLGLVKLHDPGGNPTEIFYGPQVDTSSPFHPGRPMFGKFVTEGQGLGHIIIREDDVEEATRFYRLLGLEGAVEYKFA-----VGTPVFMHCNDRHHSLAFGVGPMDKRINHLMIEYTHLDDLGYAHDLVRQQKIDVTLQIGKHSNDEALTFYCANPSGWLWEPGWGSRPAPAQQEHYLRDIFGHDNEVEGYGLDIPLK 299 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 | - | 191 201 211 221 231 241 251 261 271 281 291 178 184 Chain C from PDB Type:PROTEIN Length:299 aligned with Q6REQ5_9NOCA | Q6REQ5 from UniProtKB/TrEMBL Length:305 Alignment length:299 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 Q6REQ5_9NOCA 1 MAKVTELGYLGLSVSNLDAWRDYAAGIMGMQVVDDGEDDRIYLRMDRWHHRIVLHADGSDDLAYIGWRVAGPVELDELAEQLKNAGIPFEVASDADAAERRVLGLVKLHDPGGNPTEIFYGPQVDTSSPFHPGRPMFGKFVTEGQGLGHIIIREDDVEEATRFYRLLGLEGAVEYKFALPNGAVGTPVFMHCNDRHHSLAFGVGPMDKRINHLMIEYTHLDDLGYAHDLVRQQKIDVTLQIGKHSNDEALTFYCANPSGWLWEPGWGSRPAPAQQEHYLRDIFGHDNEVEGYGLDIPLK 299 SCOP domains d2wl9c1 C:1-134 automated matches d2wl9c2 C:135-299 automated matches SCOP domains CATH domains ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2wl9 C 1 MAKVTELGYLGLSVSNLDAWRDYAAGIMGMQVVDDGEDDRIYLRMDRWHHRIVLHADGSDDLAYIGWRVAGPVELDELAEQLKNAGIPFEVASDADAAERRVLGLVKLHDPGGNPTEIFYGPQVDTSSPFHPGRPMFGKFVTEGQGLGHIIIREDDVEEATRFYRLLGLEGAVEYKFALPNGAVGTPVFMHCNDRHHSLAFGVGPMDKRINHLMIEYTHLDDLGYAHDLVRQQKIDVTLQIGKHSNDEALTFYCANPSGWLWEPGWGSRPAPAQQEHYLRDIFGHDNEVEGYGLDIPLK 299 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 Chain D from PDB Type:PROTEIN Length:294 aligned with Q6REQ5_9NOCA | Q6REQ5 from UniProtKB/TrEMBL Length:305 Alignment length:299 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 Q6REQ5_9NOCA 2 AKVTELGYLGLSVSNLDAWRDYAAGIMGMQVVDDGEDDRIYLRMDRWHHRIVLHADGSDDLAYIGWRVAGPVELDELAEQLKNAGIPFEVASDADAAERRVLGLVKLHDPGGNPTEIFYGPQVDTSSPFHPGRPMFGKFVTEGQGLGHIIIREDDVEEATRFYRLLGLEGAVEYKFALPNGAVGTPVFMHCNDRHHSLAFGVGPMDKRINHLMIEYTHLDDLGYAHDLVRQQKIDVTLQIGKHSNDEALTFYCANPSGWLWEPGWGSRPAPAQQEHYLRDIFGHDNEVEGYGLDIPLKG 300 SCOP domains d2wl9d1 D:2-134 automated matches d2wl9d2 D:135-300 automated matches SCOP domains CATH domains ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains (1) ------------------------------------------------------------------------------------------------------------------------------------------------Glyoxalase-2wl9D01 D:146-263 ------------------------------------- Pfam domains (1) Pfam domains (2) ------------------------------------------------------------------------------------------------------------------------------------------------Glyoxalase-2wl9D02 D:146-263 ------------------------------------- Pfam domains (2) Pfam domains (3) ------------------------------------------------------------------------------------------------------------------------------------------------Glyoxalase-2wl9D03 D:146-263 ------------------------------------- Pfam domains (3) Pfam domains (4) ------------------------------------------------------------------------------------------------------------------------------------------------Glyoxalase-2wl9D04 D:146-263 ------------------------------------- Pfam domains (4) SAPs(SNPs) ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 2wl9 D 2 AKVTELGYLGLSVSNLDAWRDYAAGIMGMQVVDDGEDDRIYLRMDRWHHRIVLHADGSDDLAYIGWRVAGPVELDELAEQLKNAGIPFEVASDADAAERRVLGLVKLHDPGGNPTEIFYGPQVDTSSPFHPGRPMFGKFVTEGQGLGHIIIREDDVEEATRFYRLLGLEGAVEYKF-----AVGTPVFMHCNDRHHSLAFGVGPMDKRINHLMIEYTHLDDLGYAHDLVRQQKIDVTLQIGKHSNDEALTFYCANPSGWLWEPGWGSRPAPAQQEHYLRDIFGHDNEVEGYGLDIPLKG 300 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 | - | 191 201 211 221 231 241 251 261 271 281 291 177 183
|
||||||||||||||||||||
SCOP Domains (1, 8)
Asymmetric Unit
 |
CATH Domains (0, 0)| (no "CATH Domain" information available for 2WL9) |
Pfam Domains (1, 4)
Asymmetric Unit
|
Gene Ontology (10, 10)|
Asymmetric Unit(hide GO term definitions) Chain A,B,C,D (Q6REQ5_9NOCA | Q6REQ5)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|