| molecular function |
|---|
| | GO:0061665 | | SUMO ligase activity | | Catalysis of the transfer of SUMO to a substrate protein via the reaction X-SUMO + S --> X + S-SUMO, where X is either an E2 or E3 enzyme, the X-SUMO linkage is a thioester bond, and the S-SUMO linkage is an isopeptide bond between the C-terminal amino acid of SUMO and the epsilon-amino group of lysine residues in the substrate. |
| | GO:0019789 | | SUMO transferase activity | | Catalysis of the transfer of SUMO from one protein to another via the reaction X-SUMO + Y --> Y-SUMO + X, where both X-SUMO and Y-SUMO are covalent linkages. |
| | GO:0016874 | | ligase activity | | Catalysis of the joining of two substances, or two groups within a single molecule, with the concomitant hydrolysis of the diphosphate bond in ATP or a similar triphosphate. |
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0008270 | | zinc ion binding | | Interacting selectively and non-covalently with zinc (Zn) ions. |
| biological process |
|---|
| | GO:0016049 | | cell growth | | The process in which a cell irreversibly increases in size over time by accretion and biosynthetic production of matter similar to that already present. |
| | GO:0031668 | | cellular response to extracellular stimulus | | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of an extracellular stimulus. |
| | GO:0016925 | | protein sumoylation | | The process in which a SUMO protein (small ubiquitin-related modifier) is conjugated to a target protein via an isopeptide bond between the carboxyl terminus of SUMO with an epsilon-amino group of a lysine residue of the target protein. |
| cellular component |
|---|
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
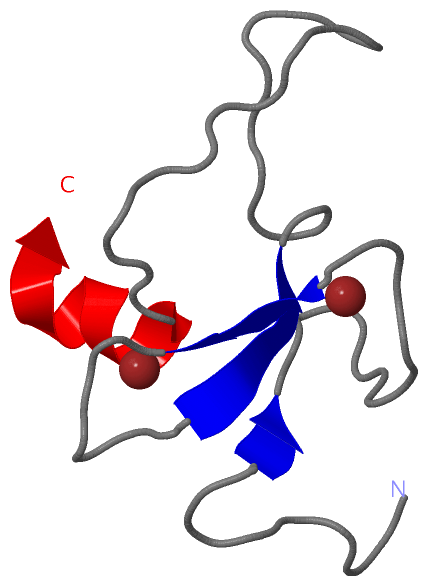
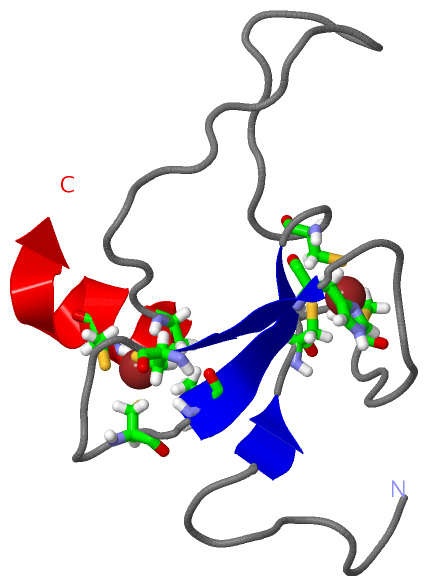
 Description
Description