| molecular function |
|---|
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0009381 | | excinuclease ABC activity | | Catalysis of the hydrolysis of ester linkages within deoxyribonucleic acid at sites flanking regions of damaged DNA to which the Uvr ABC excinuclease complexes bind. |
| | GO:0004518 | | nuclease activity | | Catalysis of the hydrolysis of ester linkages within nucleic acids. |
| biological process |
|---|
| | GO:0006281 | | DNA repair | | The process of restoring DNA after damage. Genomes are subject to damage by chemical and physical agents in the environment (e.g. UV and ionizing radiations, chemical mutagens, fungal and bacterial toxins, etc.) and by free radicals or alkylating agents endogenously generated in metabolism. DNA is also damaged because of errors during its replication. A variety of different DNA repair pathways have been reported that include direct reversal, base excision repair, nucleotide excision repair, photoreactivation, bypass, double-strand break repair pathway, and mismatch repair pathway. |
| | GO:0009432 | | SOS response | | An error-prone process for repairing damaged microbial DNA. |
| | GO:0006974 | | cellular response to DNA damage stimulus | | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus indicating damage to its DNA from environmental insults or errors during metabolism. |
| | GO:0090305 | | nucleic acid phosphodiester bond hydrolysis | | The nucleic acid metabolic process in which the phosphodiester bonds between nucleotides are cleaved by hydrolysis. |
| | GO:0006289 | | nucleotide-excision repair | | A DNA repair process in which a small region of the strand surrounding the damage is removed from the DNA helix as an oligonucleotide. The small gap left in the DNA helix is filled in by the sequential action of DNA polymerase and DNA ligase. Nucleotide excision repair recognizes a wide range of substrates, including damage caused by UV irradiation (pyrimidine dimers and 6-4 photoproducts) and chemicals (intrastrand cross-links and bulky adducts). |
| cellular component |
|---|
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
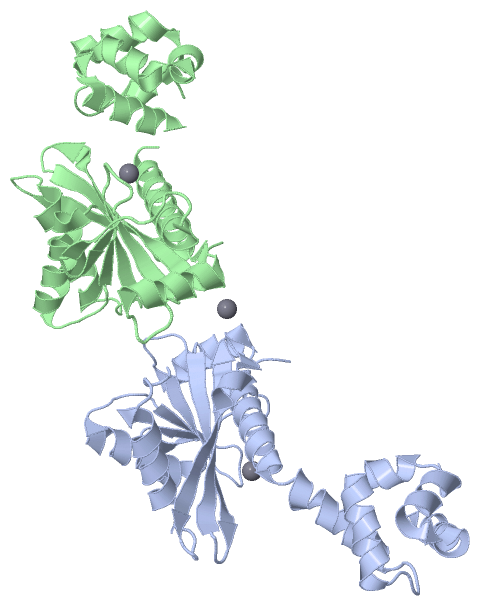
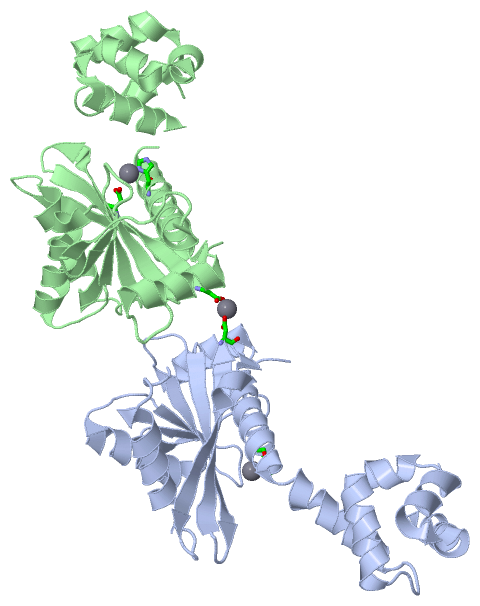
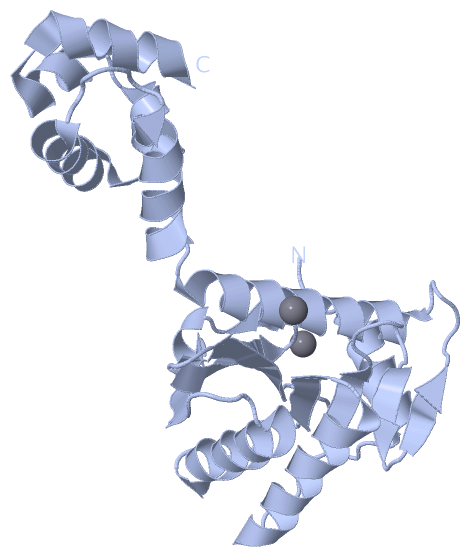
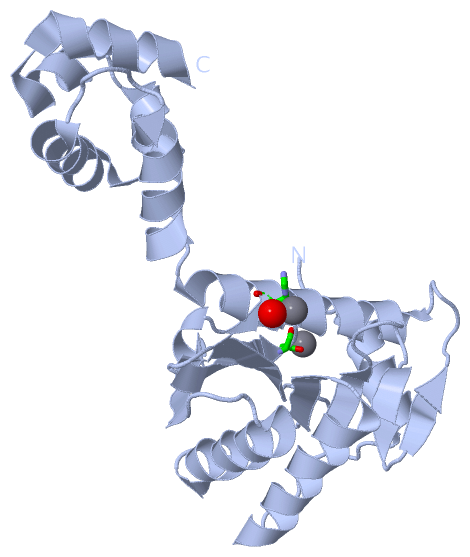
| | GO:0009380 | | excinuclease repair complex | | Any of the protein complexes formed by the UvrABC excinuclease system, which carries out nucleotide excision repair. Three different complexes are formed by the 3 proteins as they proceed through the excision repair process. First a complex consisting of two A subunits and two B subunits bind DNA and unwind it around the damaged site. Then, the A subunits disassociate leaving behind a stable complex between B subunits and DNA. Now, subunit C binds to this B+DNA complex and causes subunit B to nick the DNA on one side of the complex while subunit C nicks the DNA on the other side of the complex. DNA polymerase I and DNA ligase can then repair the resulting gap. |
 Description
Description