| molecular function |
|---|
| | GO:0005524 | | ATP binding | | Interacting selectively and non-covalently with ATP, adenosine 5'-triphosphate, a universally important coenzyme and enzyme regulator. |
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0003689 | | DNA clamp loader activity | | Catalysis of the reaction: ATP + H2O = ADP + phosphate, to drive the opening of the ring structure of the PCNA complex, or any of the related sliding clamp complexes, and their closing around the DNA duplex. |
| | GO:0008047 | | enzyme activator activity | | Binds to and increases the activity of an enzyme. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| biological process |
|---|
| | GO:0042769 | | DNA damage response, detection of DNA damage | | The series of events required to receive a stimulus indicating DNA damage has occurred and convert it to a molecular signal. |
| | GO:0006281 | | DNA repair | | The process of restoring DNA after damage. Genomes are subject to damage by chemical and physical agents in the environment (e.g. UV and ionizing radiations, chemical mutagens, fungal and bacterial toxins, etc.) and by free radicals or alkylating agents endogenously generated in metabolism. DNA is also damaged because of errors during its replication. A variety of different DNA repair pathways have been reported that include direct reversal, base excision repair, nucleotide excision repair, photoreactivation, bypass, double-strand break repair pathway, and mismatch repair pathway. |
| | GO:0006260 | | DNA replication | | The cellular metabolic process in which a cell duplicates one or more molecules of DNA. DNA replication begins when specific sequences, known as origins of replication, are recognized and bound by initiation proteins, and ends when the original DNA molecule has been completely duplicated and the copies topologically separated. The unit of replication usually corresponds to the genome of the cell, an organelle, or a virus. The template for replication can either be an existing DNA molecule or RNA. |
| | GO:0006261 | | DNA-dependent DNA replication | | A DNA replication process that uses parental DNA as a template for the DNA-dependent DNA polymerases that synthesize the new strands. |
| | GO:0070987 | | error-free translesion synthesis | | The conversion of DNA-damage induced single-stranded gaps into large molecular weight DNA after replication by using a specialized DNA polymerase or replication complex to insert a defined nucleotide across the lesion. This process does not remove the replication-blocking lesions but does not causes an increase in the endogenous mutation level. For S. cerevisiae, RAD30 encodes DNA polymerase eta, which incorporates two adenines. When incorporated across a thymine-thymine dimer, it does not increase the endogenous mutation level. |
| | GO:0042276 | | error-prone translesion synthesis | | The conversion of DNA-damage induced single-stranded gaps into large molecular weight DNA after replication by using a specialized DNA polymerase or replication complex to insert a defined nucleotide across the lesion. This process does not remove the replication-blocking lesions and causes an increase in the endogenous mutation level. For example, in E. coli, a low fidelity DNA polymerase, pol V, copies lesions that block replication fork progress. This produces mutations specifically targeted to DNA template damage sites, but it can also produce mutations at undamaged sites. |
| | GO:0006297 | | nucleotide-excision repair, DNA gap filling | | Repair of the gap in the DNA helix by DNA polymerase and DNA ligase after the portion of the strand containing the lesion has been removed by pyrimidine-dimer repair enzymes. |
| | GO:0033683 | | nucleotide-excision repair, DNA incision | | A process that results in the endonucleolytic cleavage of the damaged strand of DNA. The incision occurs at the junction of single-stranded DNA and double-stranded DNA that is formed when the DNA duplex is unwound. |
| | GO:0006296 | | nucleotide-excision repair, DNA incision, 5'-to lesion | | The endonucleolytic cleavage of the damaged strand of DNA 5' to the site of damage. The incision occurs at the junction of single-stranded DNA and double-stranded DNA that is formed when the DNA duplex is unwound. The incision follows the incision formed 3' to the site of damage. |
| | GO:0043085 | | positive regulation of catalytic activity | | Any process that activates or increases the activity of an enzyme. |
| | GO:0006355 | | regulation of transcription, DNA-templated | | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0000722 | | telomere maintenance via recombination | | Any recombinational process that contributes to the maintenance of proper telomeric length. |
| | GO:0007004 | | telomere maintenance via telomerase | | The maintenance of proper telomeric length by the addition of telomeric repeats by telomerase. |
| | GO:0006351 | | transcription, DNA-templated | | The cellular synthesis of RNA on a template of DNA. |
| | GO:0006283 | | transcription-coupled nucleotide-excision repair | | The nucleotide-excision repair process that carries out preferential repair of DNA lesions on the actively transcribed strand of the DNA duplex. In addition, the transcription-coupled nucleotide-excision repair pathway is required for the recognition and repair of a small subset of lesions that are not recognized by the global genome nucleotide excision repair pathway. |
| | GO:0019985 | | translesion synthesis | | The replication of damaged DNA by synthesis across a lesion in the template strand; a specialized DNA polymerase or replication complex inserts a defined nucleotide across from the lesion which allows DNA synthesis to continue beyond the lesion. This process can be mutagenic depending on the damaged nucleotide and the inserted nucleotide. |
| cellular component |
|---|
| | GO:0005663 | | DNA replication factor C complex | | A complex that loads the DNA polymerase processivity factor proliferating cell nuclear antigen (PCNA) onto DNA, thereby permitting processive DNA synthesis catalyzed by DNA polymerase. In eukaryotes the complex consists of five polypeptides. |
| | GO:0070062 | | extracellular exosome | | A vesicle that is released into the extracellular region by fusion of the limiting endosomal membrane of a multivesicular body with the plasma membrane. Extracellular exosomes, also simply called exosomes, have a diameter of about 40-100 nm. |
| | GO:0005654 | | nucleoplasm | | That part of the nuclear content other than the chromosomes or the nucleolus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
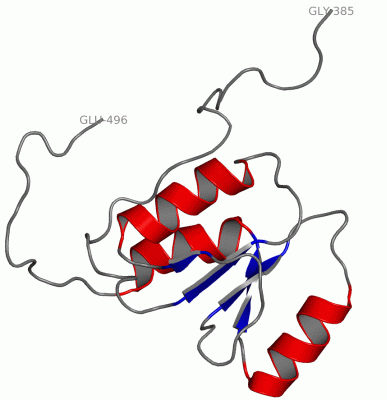
 Description
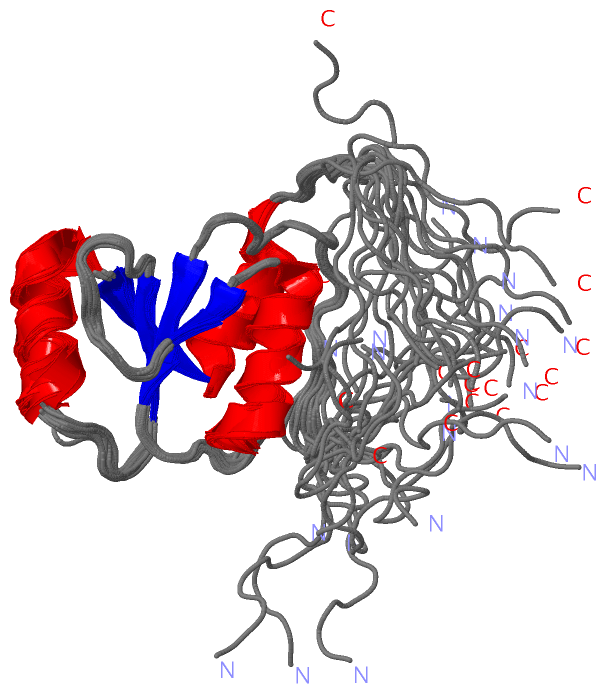
Description