| molecular function |
|---|
| | GO:0043024 | | ribosomal small subunit binding | | Interacting selectively and non-covalently with any part of the small ribosomal subunit. |
| | GO:0008135 | | translation factor activity, RNA binding | | Functions during translation by interacting selectively and non-covalently with RNA during polypeptide synthesis at the ribosome. |
| | GO:0003743 | | translation initiation factor activity | | Functions in the initiation of ribosome-mediated translation of mRNA into a polypeptide. |
| biological process |
|---|
| | GO:0070124 | | mitochondrial translational initiation | | The process preceding formation of the peptide bond between the first two amino acids of a protein in a mitochondrion. This includes the formation of a complex of the ribosome, mRNA, and an initiation complex that contains the first aminoacyl-tRNA. |
| | GO:0032790 | | ribosome disassembly | | The disaggregation of a ribosome into its constituent components; includes the dissociation of ribosomal subunits. |
| | GO:0006412 | | translation | | The cellular metabolic process in which a protein is formed, using the sequence of a mature mRNA or circRNA molecule to specify the sequence of amino acids in a polypeptide chain. Translation is mediated by the ribosome, and begins with the formation of a ternary complex between aminoacylated initiator methionine tRNA, GTP, and initiation factor 2, which subsequently associates with the small subunit of the ribosome and an mRNA or circRNA. Translation ends with the release of a polypeptide chain from the ribosome. |
| | GO:0006413 | | translational initiation | | The process preceding formation of the peptide bond between the first two amino acids of a protein. This includes the formation of a complex of the ribosome, mRNA or circRNA, and an initiation complex that contains the first aminoacyl-tRNA. |
| cellular component |
|---|
| | GO:0005739 | | mitochondrion | | A semiautonomous, self replicating organelle that occurs in varying numbers, shapes, and sizes in the cytoplasm of virtually all eukaryotic cells. It is notably the site of tissue respiration. |
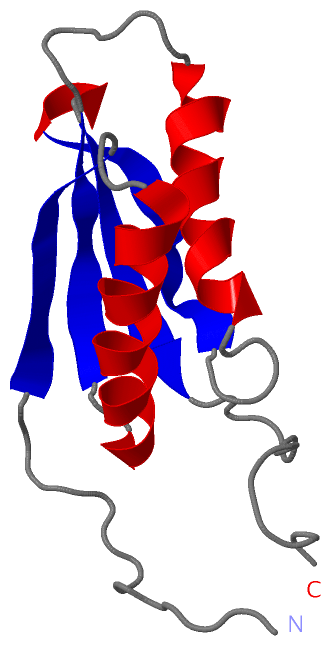
 Description
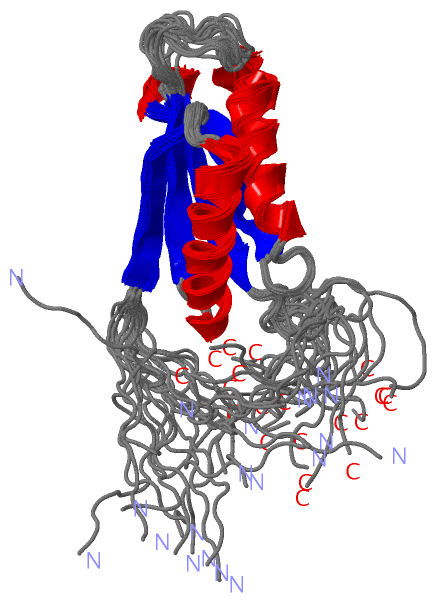
Description