|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (0, 0)| (no "Ligand,Modified Residues,Ions" information available for 1ZHI) |
Sites (0, 0)| (no "Site" information available for 1ZHI) |
SS Bonds (0, 0)| (no "SS Bond" information available for 1ZHI) |
Cis Peptide Bonds (0, 0)| (no "Cis Peptide Bond" information available for 1ZHI) |
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 1ZHI) |
PROSITE Motifs (1, 1)
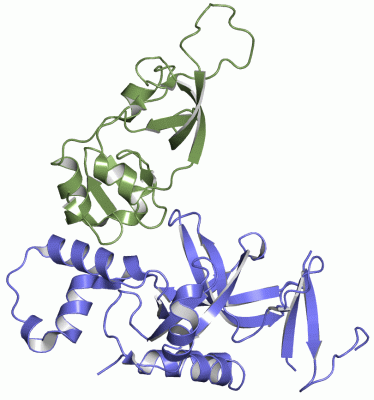
Asymmetric/Biological Unit (1, 1)
|
||||||||||||||||||||||||
Exons (2, 2)
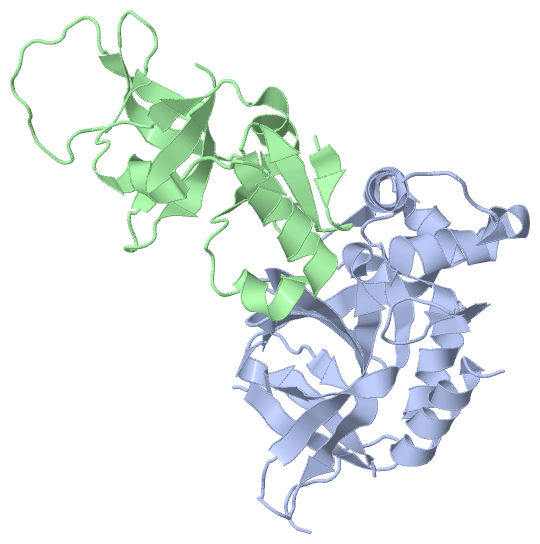
Asymmetric/Biological Unit (2, 2)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sequences/Alignments
Asymmetric/Biological UnitChain A from PDB Type:PROTEIN Length:195 aligned with ORC1_YEAST | P54784 from UniProtKB/Swiss-Prot Length:914 Alignment length:205 19 29 39 49 59 69 79 89 99 109 119 129 139 149 159 169 179 189 199 209 ORC1_YEAST 10 GWEIITTDEQGNIIDGGQKRLRRRGAKTEHYLKRSSDGIKLGRGDSVVMHNEAAGTYSVYMIQELRLNTLNNVVELWALTYLRWFEVNPLAHYRQFNPDANILNRPLNYYNKLFSETANKNELYLTAELAELQLFNFIRVANVMDGSKWEVLKGNVDPERDFTVRYICEPTGEKFVDINIEDVKAYIKKVEPREAQEYLKDLTLP 214 SCOP domains d1zhia_ A: Origin -recognition complex protein 120kDa subunit, Orc1p SCOP domains CATH domains ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains --------------------------------------BAH-1zhiA01 A:48-188 -------------------------- Pfam domains SAPs(SNPs) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE --------------------------------------BAH PDB: A:48-188 UniProt: 48-188 -------------------------- PROSITE Transcript 2 Exon 2.1 PDB: A:10-214 (gaps) UniProt: 1-914 [INCOMPLETE] Transcript 2 1zhi A 10 GWEIITTDEQGNIIDGG----------TEHYLKRSSDGIKLGRGDSVVMHNEAAGTYSVYMIQELRLNTLNNVVELWALTYLRWFEVNPLAHYRQFNPDANILNRPLNYYNKLFSETANKNELYLTAELAELQLFNFIRVANVMDGSKWEVLKGNVDPERDFTVRYICEPTGEKFVDINIEDVKAYIKKVEPREAQEYLKDLTLP 214 19 | - |39 49 59 69 79 89 99 109 119 129 139 149 159 169 179 189 199 209 26 37 Chain B from PDB Type:PROTEIN Length:125 aligned with SIR1_YEAST | P21691 from UniProtKB/Swiss-Prot Length:654 Alignment length:125 472 482 492 502 512 522 532 542 552 562 572 582 SIR1_YEAST 463 EEYVSPRFLVADGFLIDLAEEKPINPKDPRLLTLLKDHQRAMIDQMNLVKWNDFKKYQDPIPLKAKTLFKFCKQIKKKFLRGADFKLHTLPTEANLKYEPERMTVLCSCVPILLDDQTVQYLYDD 587 SCOP domains d1zhib1 B:487-611 Regulatory protein SIR1 SCOP domains CATH domains ----------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains Sir1-1zhiB01 B:487-611 Pfam domains SAPs(SNPs) ----------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ----------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript 1 Exon 1.1 PDB: B:487-611 UniProt: 1-654 [INCOMPLETE] Transcript 1 1zhi B 487 EEYVSPRFLVADGFLIDLAEEKPINPKDPRLLTLLKDHQRAMIDQMNLVKWNDFKKYQDPIPLKAKTLFKFCKQIKKKFLRGADFKLHTLPTEANLKYEPERMTVLASCVPILLDDQTVQYLYDD 611 496 506 516 526 536 546 556 566 576 586 596 606
|
||||||||||||||||||||
SCOP Domains (2, 2)
Asymmetric/Biological Unit
 |
CATH Domains (0, 0)| (no "CATH Domain" information available for 1ZHI) |
Pfam Domains (2, 2)
Asymmetric/Biological Unit
|
Gene Ontology (22, 25)|
Asymmetric/Biological Unit(hide GO term definitions) Chain A (ORC1_YEAST | P54784)
Chain B (SIR1_YEAST | P21691)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|